The Intel Xeon E5 v4 Review: Testing Broadwell-EP With Demanding Server Workloads
by Johan De Gelas on March 31, 2016 12:30 PM EST- Posted in
- CPUs
- Intel
- Xeon
- Enterprise
- Enterprise CPUs
- Broadwell
Broadwell-EP: A 10,000 Foot View
What are the building blocks of a 22-core Xeon? The short answer: 24 cores, 2.5 MB L3-cache per core, 2 rings connected by 2 bridges (s-boxes) and several PCIe/QPI/home "agents".
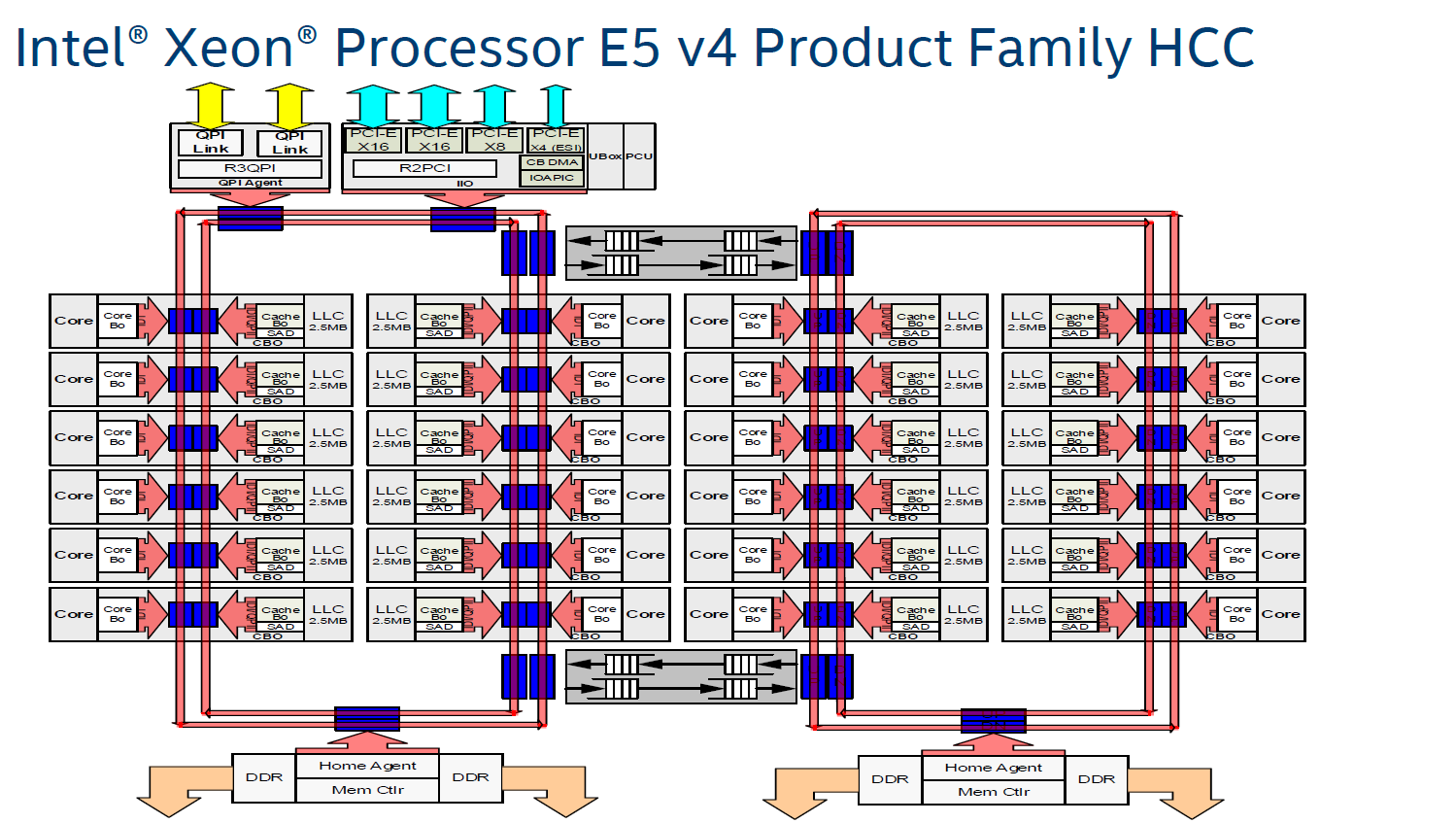
The fact that only 22 of those 24 cores are activated in the top Xeon E5 SKU is purely a product differentiation decision. The 18 core Xeon E5 v3 used exactly the same die as the Xeon E7, and this has not changed in the new "Broadwell" generation.
The largest die (+/- 454 mm²), highest core (HCC) count SKUs still work with a two ring configuration connected by two bridges. The rings move data in opposite directions (clockwise/counter-clockwise) in order to reduce latency by allowing data to take the shortest path to the destination. The blue points indicate where data can jump onto the ring buses. Physical addresses are evenly distributed over the different cache slices (each 2.5 MB) to make sure that L3-cache accesses are also distributed, as a "hotspot" on one L3-cache slice would lower performance significantly. The L3-cache latency is rather variable: if the core is lucky enough to find the data in its own cache slice, only one extra cycle is needed (on top of the normal L1-L2-L3 latency). Getting a cacheline of another slice can cost up to 12 cycles, with an average cost of 6 cycles..
Meanwhile rings and other entities of the uncore work on a separate voltage plane and frequency. Power can be dynamically allocated to these entities, although the uncore parts are limited to 3 GHz.
Just like Haswell-EP, the Broadwell-EP Xeon E5 has three different die configurations. The second configuration supports 12 to 15 cores and is a smaller version (306mm²) of the third die configuration that we described above. These dies still have two memory controllers.
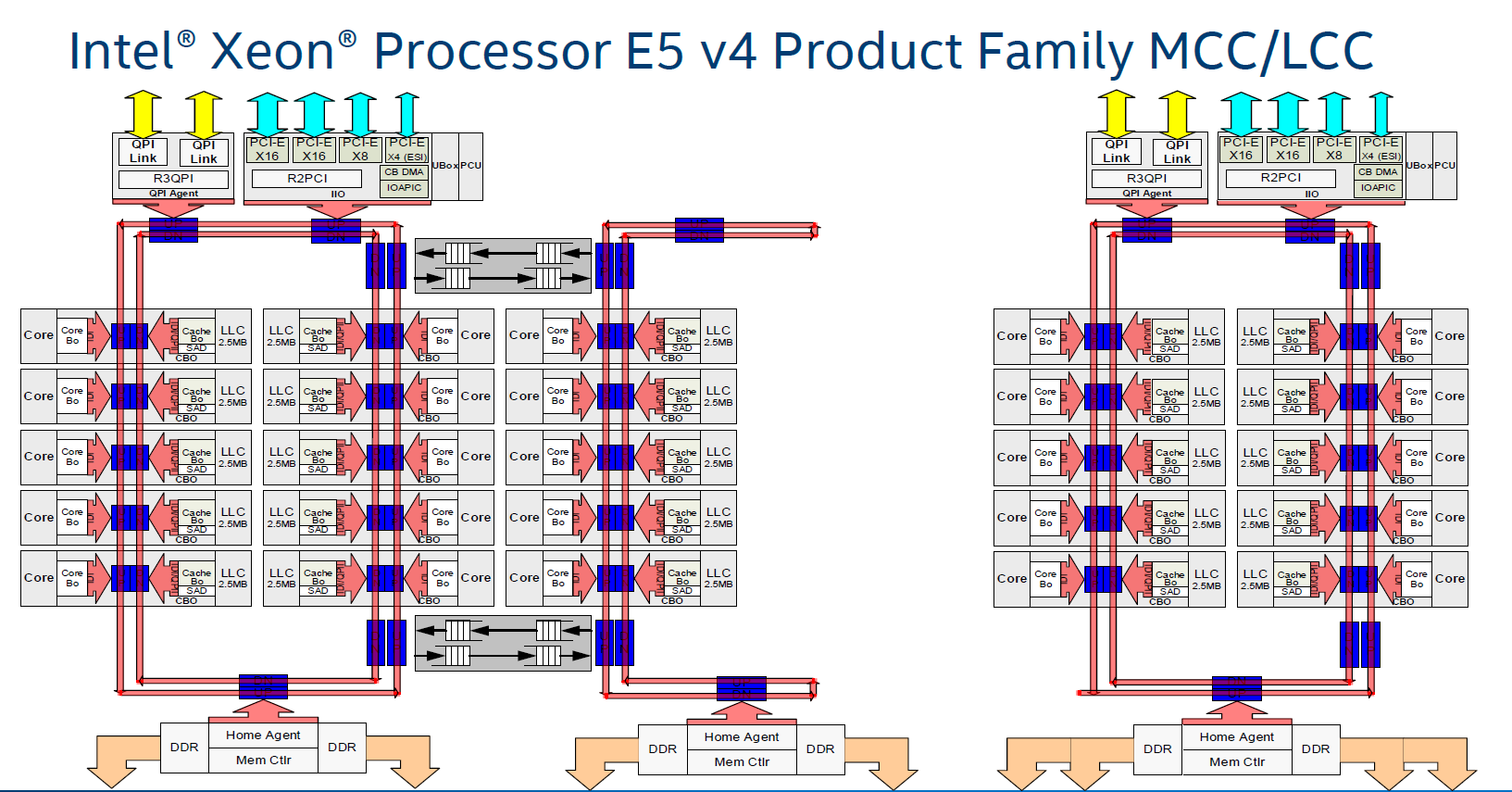
Otherwise the smallest 10 core die uses only one dual ring, two columns of cores, and only one memory controller. However, the memory controller drives 4 channels instead of 2, so there is a very small bandwidth penalty (5-10%) compared to the larger dies (HCC+MCC) with two memory controllers. The smaller die has a smaller L3-cache of course (25 MB max.). As the L3-cache gets smaller, latency is also a bit lower.
Cache Coherency
As the core count goes up, it gets increasingly complex to keep cache coherency. Intel uses the MESIF (Modified, Exclusive, shared, Invalid and Forward) protocol for cache coherency. The Home Agents inside the memory controller and the caching agents inside the L3-cache slice implement the cache coherency. To maintain consistency, a snoop mechanism is necessary. There are now no less than 4 different snoop methods.
The first, Early Snoop, was available starting with Sandy Bridge-EP models. With early snoop, caching agents broadcast snoop requests in the event of an L3-cache miss. Early snoop mode offers low latency, but it generates massive broadcasting traffic. As a result, it is not a good match for high core count dies running bandwidth intensive applications.
The second mode, Home Snoop, was introduced with Ivy Bridge. Cache line requests are no longer broadcasted but forwarded to the home agent in the home node. This adds a bit of latency, but significantly reduces the amount of cache coherency traffic.
Haswell-EP added a third mode, Cluster on Die (CoD). Each home agent has 14 KB directory cache. This directory cache keeps track of the contested cache lines to lower cache-to-cache transfer latencies. In the event of a request, it is checked first, and the directory cache returns a hit, snoops are only sent to indicated (by the directory cache) agents.
On Broadwell-EP, the dice are indeed split along the rings: all cores on one ring are one NUMA node, all other cores on the other ring make the second NUMA node. On Haswell-EP, the split was weirder, with one core of the second ring being a member of the first cluster. On top of that, CoD splits the processor in two NUMA nodes, more or less one node per ring.
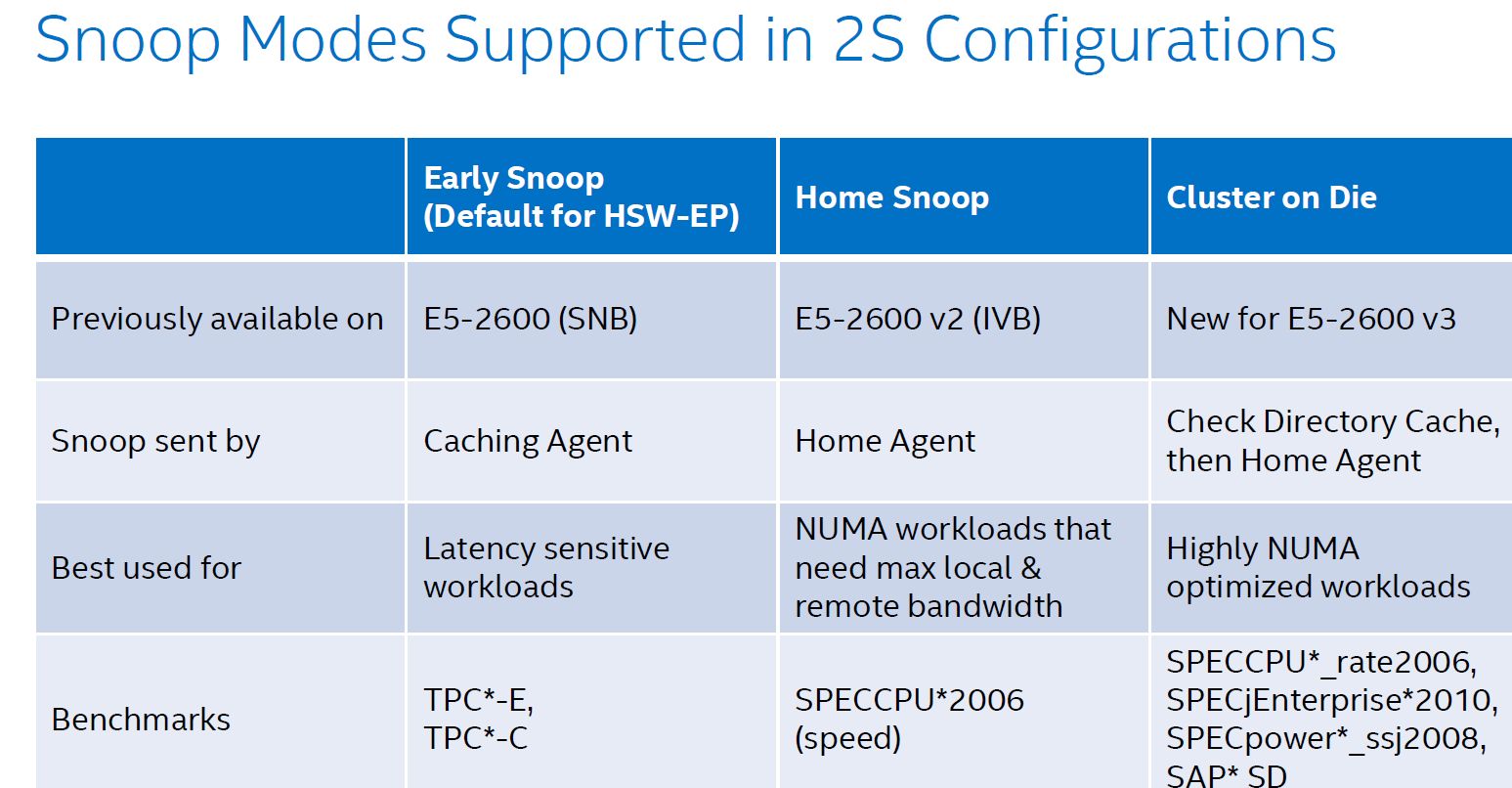
The fourth mode, introduced with Broadwell EP, is the "home snoop" method, but improved with the use of the directory cache and yet another refinement called opportunistic snoop broadcast. This mode already starts snoops to the remote socket early and does the read of the memory directory in parallel instead of waiting for the latter to be done. This is the default snoop method on Broadwell EP.
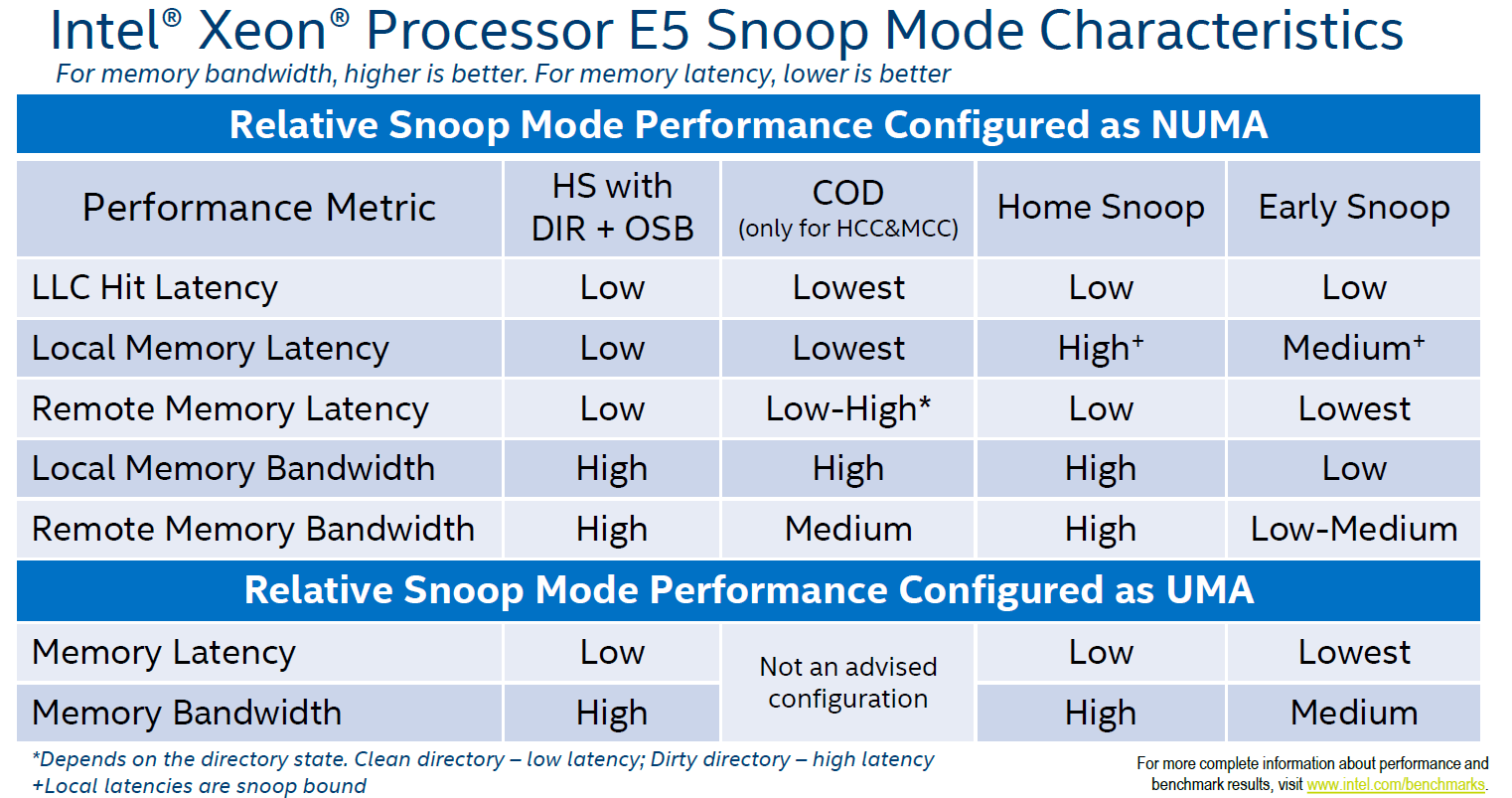
This opportunistic snooping lowers the latency to remote memory.
These snoop modes can be set in the BIOS as you can see above.








112 Comments
View All Comments
isrv - Sunday, April 3, 2016 - link
i will belive that only after one by one comparison E5-1630v3 vs any of E5v4 composing wordpress front page for example.and so far, that's only a words about better caching etc...
simplyfabio - Monday, April 4, 2016 - link
Could I ask one thing here? For a Workstation 3D, both for rendering and graphic/cad, (like illustrator, photoshop, autocad, 3dsmax), could be better have more core like the E5 2690 (considering all the turbo clock speed for each core active) ore better frequency, like the 1680? Thanks a lot to everyone, I can't find a nice review on this side of this CPUs...grantdesrosiers - Monday, April 4, 2016 - link
Not sure if anyone has pointed it out yet, but I think there is an error on the "Multi-Threaded Integer Performance" page, first graph. The 2695v4 says 22 cores, I believe it should be 18.SanX - Monday, April 4, 2016 - link
Poor Moore's law for workstations... 10-20% gain per 2-years generation.Think about it: there is no reason to upgrade for the next *** 5-10 generations *** or the next 10-20 years (!!!) when the processors will be only e-fold (2.71x) faster.
dragonsqrrl - Monday, April 4, 2016 - link
The problem is your first assumption is already false.Khenglish - Monday, April 4, 2016 - link
I can't understand why the 4C and under turbo speeds are so slow on the v4 2699. A Broadwell with 55MB of cache being outperformed by a stock clocked Sandy Bridge is ridiculous. Why would this CPU not clock up to at least 4.2GHz with a 4 core workload, and say 4.4GHz for a 1 core workload? Hell it costs over $4000 and a massive TDP. You'd think Intel could take a minute to make the low core count speeds not terribly low.My workstation in my lab has a 1650 v3. My workloads peak between 4-8 cores. There is not a single CPU in the v4 lineup that would be an upgrade over the 1650 v3 despite the major power savings of 14nm and the cache size increase due to Intel's inability to set reasonable 8C and under frequencies.
Romulous - Monday, April 4, 2016 - link
People who are serious about recompiling the same software often would probably use ccache and maybe even distcc. So your Linux kernel compile test is really only there for to show potential cpu performance.LHL2500 - Tuesday, April 5, 2016 - link
"It finds a home in the same LGA 2011-3 socket."Not according to Intel's website.
http://ark.intel.com/compare/91754,81908
In this comparison between a v3 and a v4 version of a E5-2680, the socket support for the two chips are different. The older version using the the FCLGA2011-3 and the newer version using FCLGA2011.
So who is right? Anandtech or Intel?
And it not just this chip. It's all the v4s.
While I hope it's a typo on Intel's behalf, for now it doesn't look like the v4s are direct upgrades to the v3s. You will apparently need new motherboards.
xrror - Tuesday, April 5, 2016 - link
That... is a bit disconcerting. I also like how "VID Voltage Range" for the v4 parts is simply listed as "0" ...SeanJ76 - Tuesday, April 5, 2016 - link
My School had the 3rd Generation Xeon's in their Workstations, they were slow as fuck@3.3ghz!! The consumer i7 4790K/6700K would run laps around these Xeon crap cpus!