The Intel Xeon E5 v4 Review: Testing Broadwell-EP With Demanding Server Workloads
by Johan De Gelas on March 31, 2016 12:30 PM EST- Posted in
- CPUs
- Intel
- Xeon
- Enterprise
- Enterprise CPUs
- Broadwell
Broadwell-EP: A 10,000 Foot View
What are the building blocks of a 22-core Xeon? The short answer: 24 cores, 2.5 MB L3-cache per core, 2 rings connected by 2 bridges (s-boxes) and several PCIe/QPI/home "agents".
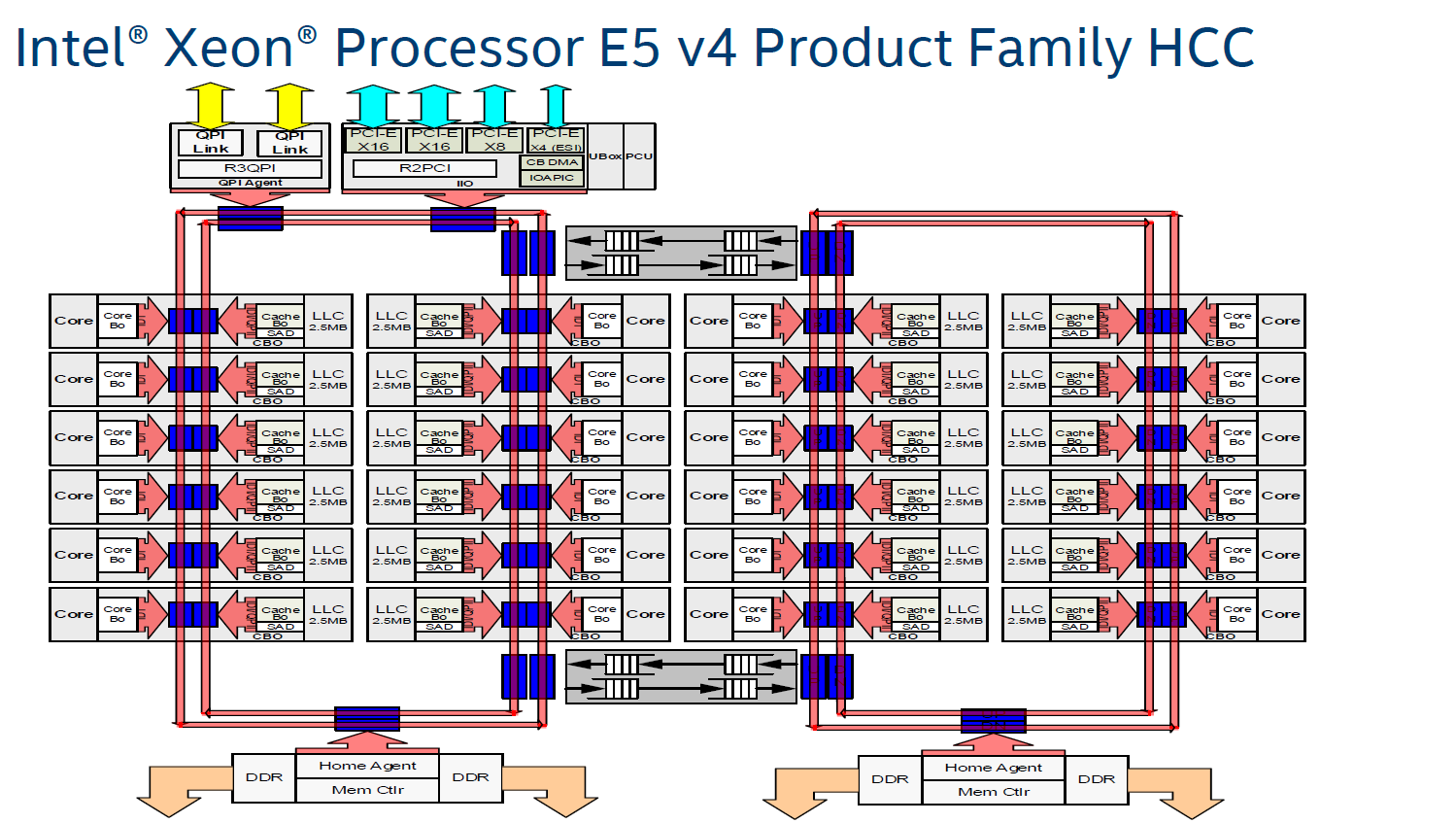
The fact that only 22 of those 24 cores are activated in the top Xeon E5 SKU is purely a product differentiation decision. The 18 core Xeon E5 v3 used exactly the same die as the Xeon E7, and this has not changed in the new "Broadwell" generation.
The largest die (+/- 454 mm²), highest core (HCC) count SKUs still work with a two ring configuration connected by two bridges. The rings move data in opposite directions (clockwise/counter-clockwise) in order to reduce latency by allowing data to take the shortest path to the destination. The blue points indicate where data can jump onto the ring buses. Physical addresses are evenly distributed over the different cache slices (each 2.5 MB) to make sure that L3-cache accesses are also distributed, as a "hotspot" on one L3-cache slice would lower performance significantly. The L3-cache latency is rather variable: if the core is lucky enough to find the data in its own cache slice, only one extra cycle is needed (on top of the normal L1-L2-L3 latency). Getting a cacheline of another slice can cost up to 12 cycles, with an average cost of 6 cycles..
Meanwhile rings and other entities of the uncore work on a separate voltage plane and frequency. Power can be dynamically allocated to these entities, although the uncore parts are limited to 3 GHz.
Just like Haswell-EP, the Broadwell-EP Xeon E5 has three different die configurations. The second configuration supports 12 to 15 cores and is a smaller version (306mm²) of the third die configuration that we described above. These dies still have two memory controllers.
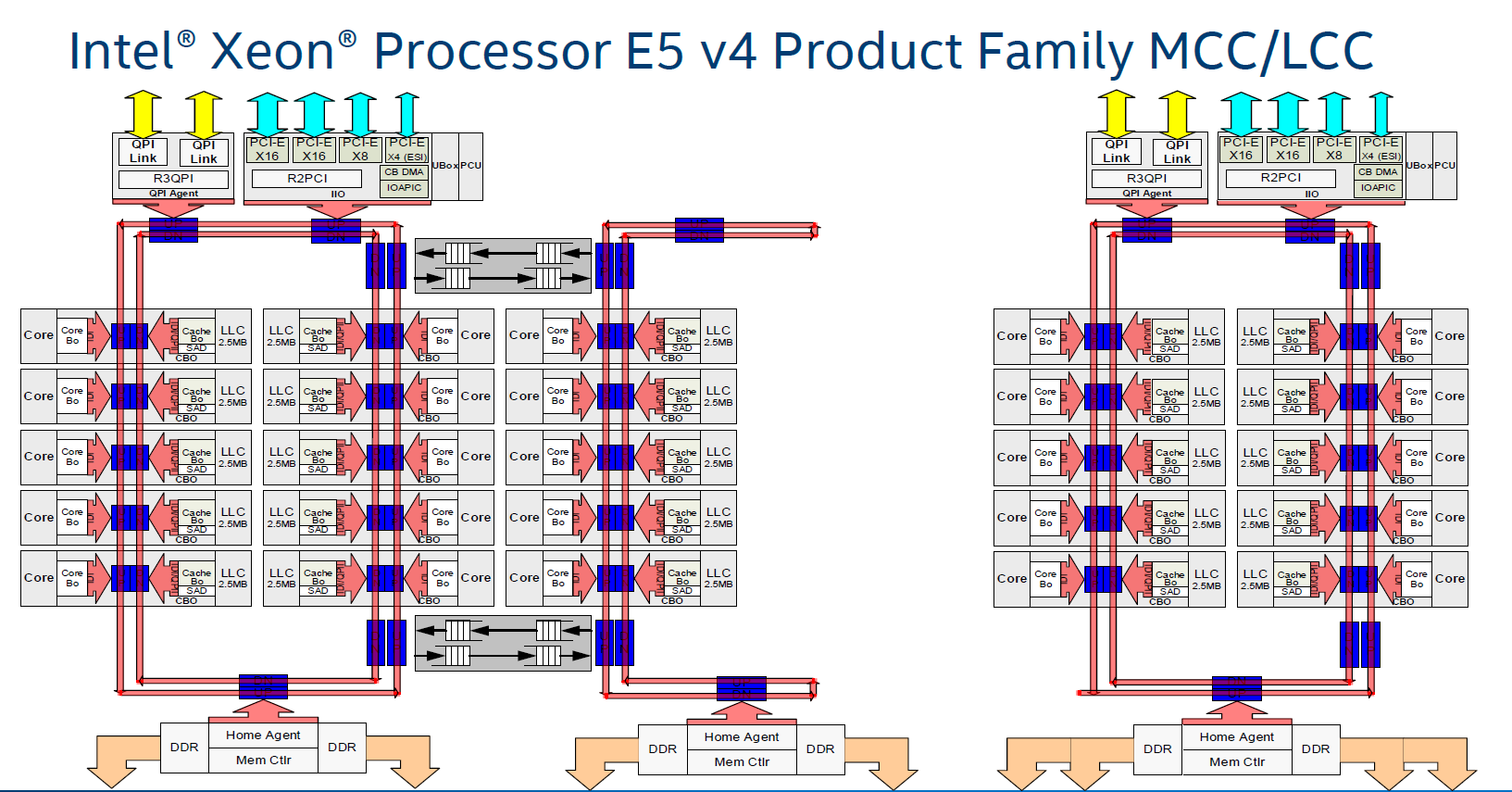
Otherwise the smallest 10 core die uses only one dual ring, two columns of cores, and only one memory controller. However, the memory controller drives 4 channels instead of 2, so there is a very small bandwidth penalty (5-10%) compared to the larger dies (HCC+MCC) with two memory controllers. The smaller die has a smaller L3-cache of course (25 MB max.). As the L3-cache gets smaller, latency is also a bit lower.
Cache Coherency
As the core count goes up, it gets increasingly complex to keep cache coherency. Intel uses the MESIF (Modified, Exclusive, shared, Invalid and Forward) protocol for cache coherency. The Home Agents inside the memory controller and the caching agents inside the L3-cache slice implement the cache coherency. To maintain consistency, a snoop mechanism is necessary. There are now no less than 4 different snoop methods.
The first, Early Snoop, was available starting with Sandy Bridge-EP models. With early snoop, caching agents broadcast snoop requests in the event of an L3-cache miss. Early snoop mode offers low latency, but it generates massive broadcasting traffic. As a result, it is not a good match for high core count dies running bandwidth intensive applications.
The second mode, Home Snoop, was introduced with Ivy Bridge. Cache line requests are no longer broadcasted but forwarded to the home agent in the home node. This adds a bit of latency, but significantly reduces the amount of cache coherency traffic.
Haswell-EP added a third mode, Cluster on Die (CoD). Each home agent has 14 KB directory cache. This directory cache keeps track of the contested cache lines to lower cache-to-cache transfer latencies. In the event of a request, it is checked first, and the directory cache returns a hit, snoops are only sent to indicated (by the directory cache) agents.
On Broadwell-EP, the dice are indeed split along the rings: all cores on one ring are one NUMA node, all other cores on the other ring make the second NUMA node. On Haswell-EP, the split was weirder, with one core of the second ring being a member of the first cluster. On top of that, CoD splits the processor in two NUMA nodes, more or less one node per ring.
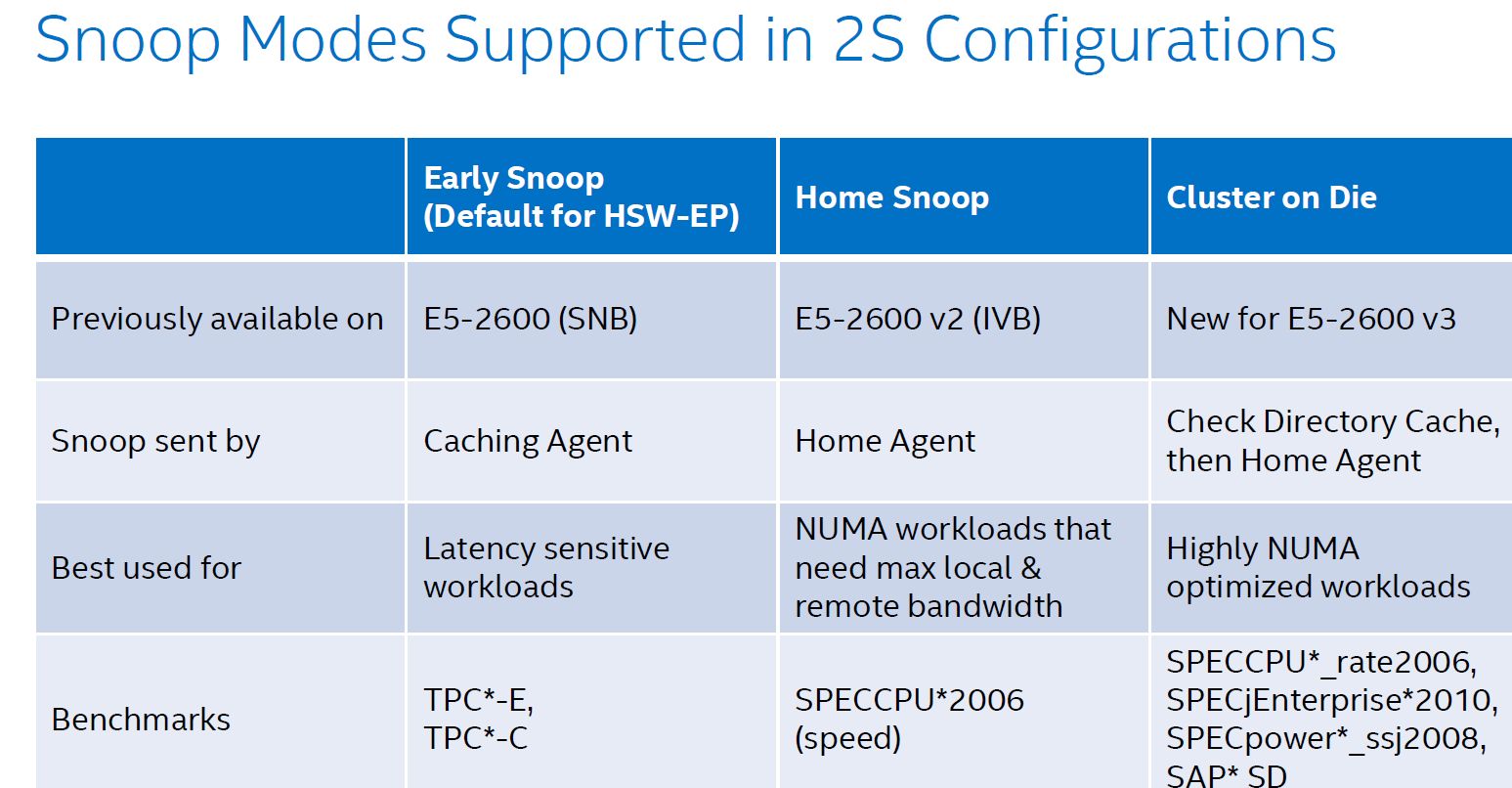
The fourth mode, introduced with Broadwell EP, is the "home snoop" method, but improved with the use of the directory cache and yet another refinement called opportunistic snoop broadcast. This mode already starts snoops to the remote socket early and does the read of the memory directory in parallel instead of waiting for the latter to be done. This is the default snoop method on Broadwell EP.
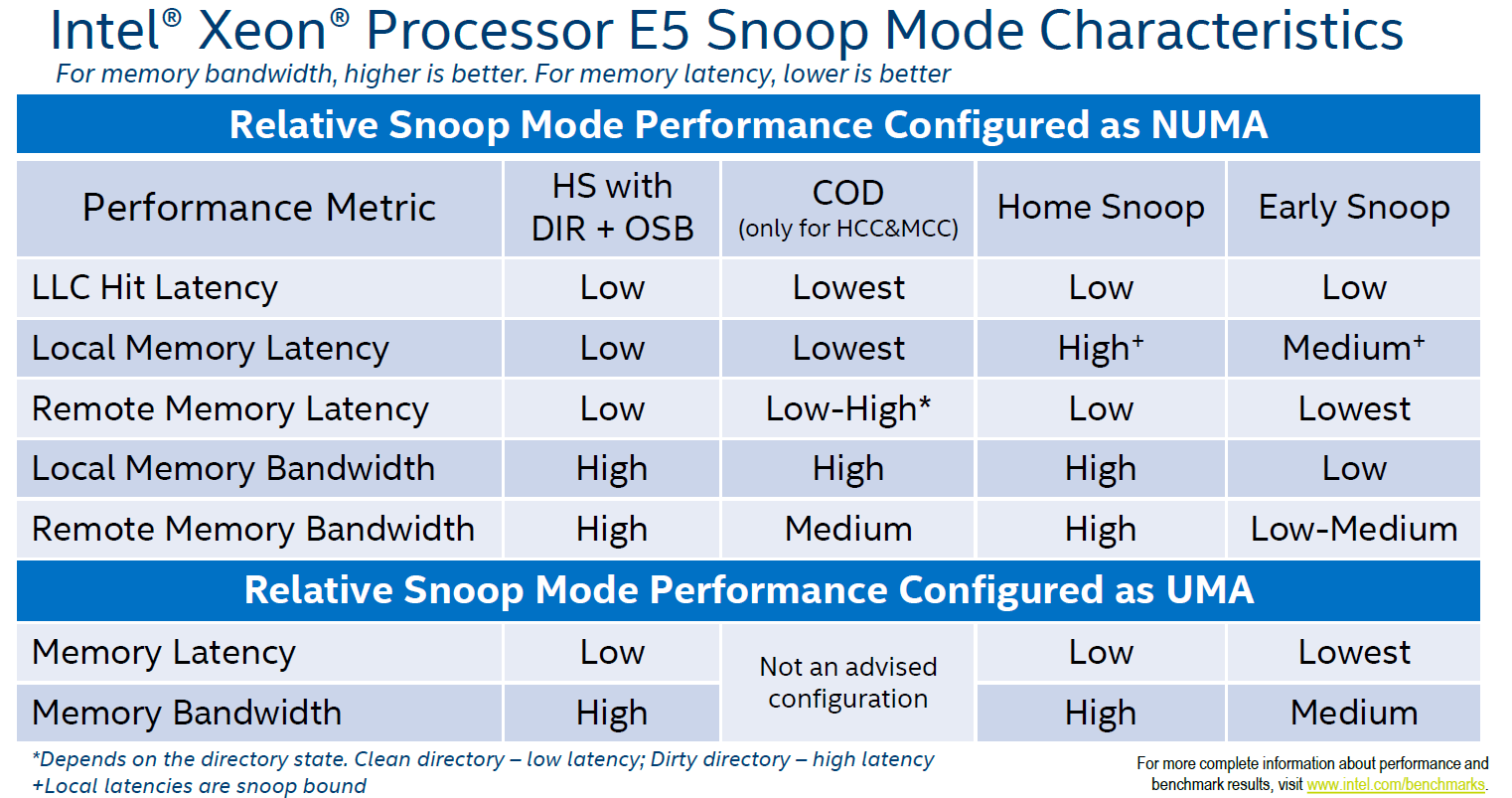
This opportunistic snooping lowers the latency to remote memory.
These snoop modes can be set in the BIOS as you can see above.








112 Comments
View All Comments
patrickjp93 - Friday, April 1, 2016 - link
Knight's Landing: 730 mm^2, also on the 14nm platformextide - Friday, April 1, 2016 - link
Is it really that big..? Wow, I knew it was big, but didn't know it was that big. Got a source on that?Kevin G - Friday, April 8, 2016 - link
I'll second a link for a source. I knew it'd be big but that big?extide - Friday, April 1, 2016 - link
I know you meant Reticle, but that was a pretty funny typo, heh.Kevin G - Friday, April 8, 2016 - link
Autocorrect has gotten the best of me yet again.extide - Friday, April 1, 2016 - link
And, I know how big GM200 and Fiji are, but I am talking about big GPU's on 14/16nm. All signs are currently pointing to <300mm^2 for the first round of 14/16nm GPU's.lorribot - Thursday, March 31, 2016 - link
Given the way Microsoft and others are now licensing by the core and in large non splitable packages (Windows 2016 Datacenter is in blocks of 16 cores, a dual socket server with 44 cores would need 48 core licences) the increasing core count has limited appeal over small numbers of faster cores when looking at virtualised environments.Those still in the physical world will still have to pay per core but may have to buy 4 std Windows licenses.
when it comes to doing your testing, it should reflect these costs and compare total bang per buck when dealing with performance.
Red Hat still licences per socket but don't be surprised if they go per core too.
JohanAnandtech - Friday, April 1, 2016 - link
Back in 2008, I had a sales person explaining the license models of Microsoft to me in our lab. From that point on, we have invested most of our time and resources in linux server software. :-Dextide - Friday, April 1, 2016 - link
Enterprise linux isn't free, either ya knowrahvin - Friday, April 1, 2016 - link
Support isn't free on the FOSS side but the software is. Redhat is never going to charge more per "cores" for support, that's ridiculous and would result in rivals stealing their support contracts. If licensing costs are that bad that you are dumping hardware you really should be looking at moving services to Linux and Visualizing the windows servers so you can limit the core count and provide more horsepower.Anyone putting Microsoft on bare hardware these days is nuts. Although the consolation is that they get to pay MS's exorbitant tax on software. Linux should be the core component of any IT services and virtualized servers where you need proprietary server software.