The AMD Vega GPU Architecture Teaser: Higher IPC, Tiling, & More, Coming in H1’2017
by Ryan Smith on January 5, 2017 9:00 AM ESTHBM2 & “The World’s Most Scalable GPU Memory Architecture”
With the launch of the Fiji GPU and resulting Radeon R9 Fury products in 2015, AMD became the first GPU manufacturer to ship with first-generation High Bandwidth Memory (HBM). The ultra-wide memory standard essentially turned the usual rules of GPU memory on its head, replacing narrow, high clocked memory (GDDR5) with wide, low clocked memory. By taking advantage of Through Silicon Vias (TSVs) and silicon interposers, HBM could offer far more bandwidth than GDDR5 while consuming less power and taking up less space.
Now for Vega, AMD is back again with support for the next generation of HBM technology, HBM2. In fact this is the very first thing we ever learned about Vega, going back to AMD’s roadmap from last year where it was the sole detail listed for the architecture.
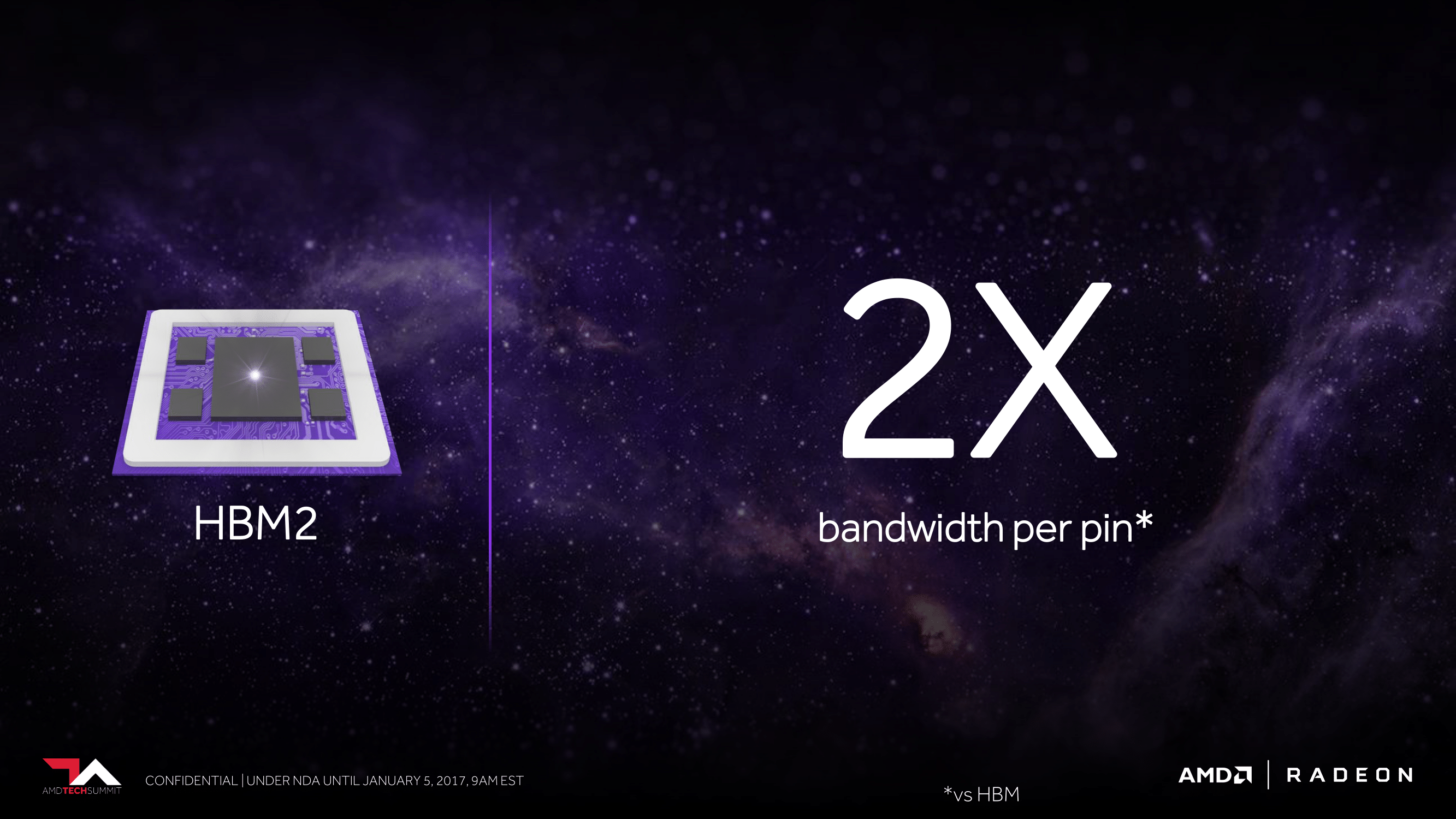
HBM2 builds off of HBM, offering welcome improvements in both bandwidth and capacity. In terms of bandwidth, HBM2 can clock at up to 2Gbps per pin, twice the rate of HBM1. This means that at those clockspeeds (and I’ll note that at least so far we haven’t seen any 2Gbps HBM2), AMD can either double their memory bandwidth or cut the number of HBM stacks they need in half to get the same amount of bandwidth. The latter point is of particular interest, as we’ll get to here in a bit.

But more important still are the capacity increases. HBM1 stacked topped out at 1GB each, which means Fiji could have no more than 4GB of VRAM. HBM2 stacks go much higher – up to 8GB per stack – which means AMD’s memory capacity problems when using HBM have for all practical purposes gone away. AMD could in time offer 8GB, 16GB, or even 32GB of HBM2 memory, which is more than competitive with current GDDR5 memory types.
Meanwhile it’s very interesting to note that with Vega, AMD is calling their on-package HBM stacks “high-bandwidth cache” rather than “VRAM” or similar terms as was the case with Fiji products.

This is a term that can easily be misread – and it’s the one area where perhaps it’s too much of a tease – but despite the name, there are no signals from AMD right now that it’s going to be used as a cache in the pure, traditional sense. Rather, because AMD has already announced that they’re looking into other ideas such as on-card NAND storage (the Radeon Pro SSG), they are looking at memory more broadly.
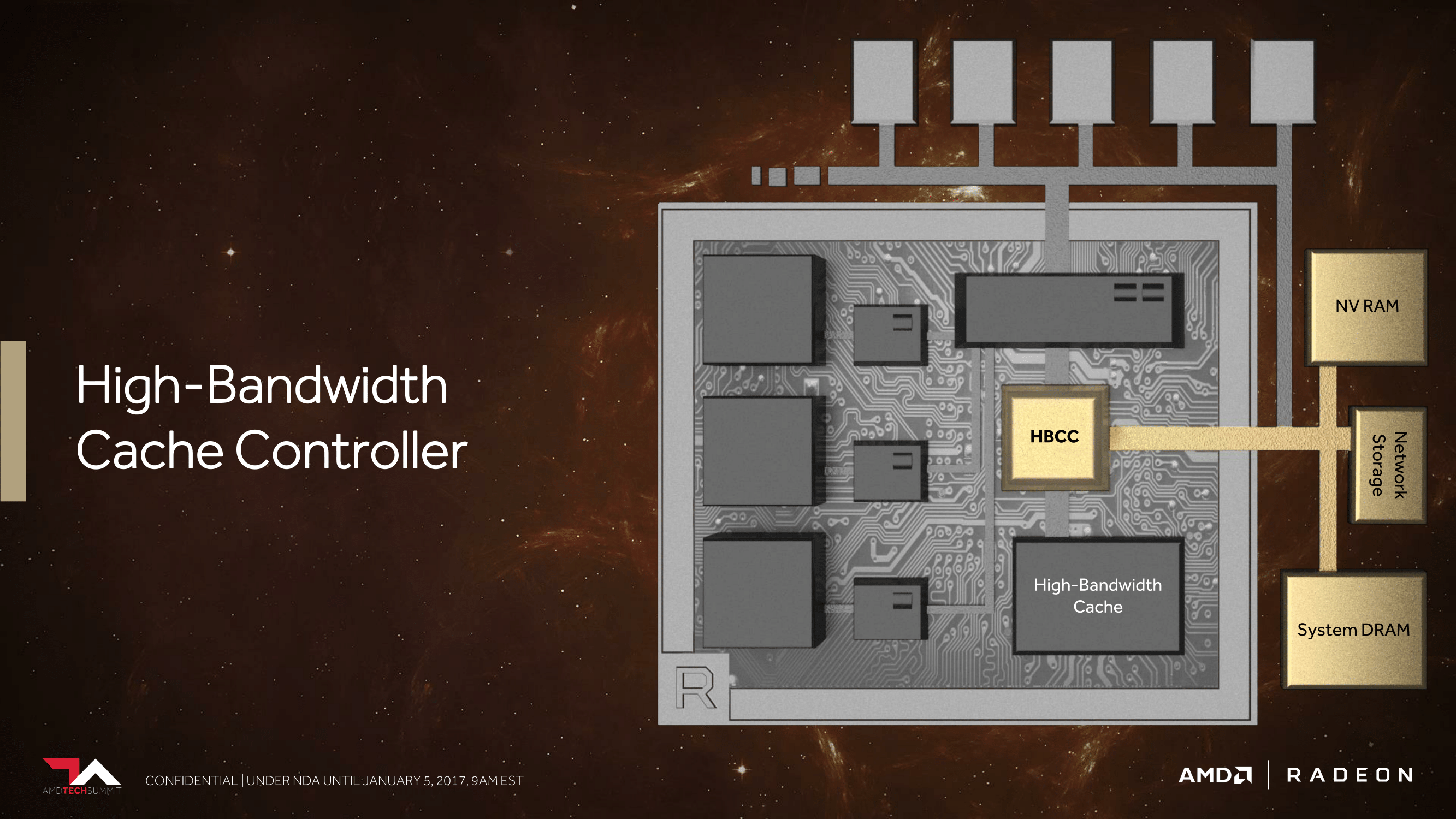
And this brings us to what AMD is calling “The World’s Most Scalable GPU Memory Architecture”. Along with supporting HBM, AMD has undertaken a lot of under-the-hood work to better support large dataset management between the high bandwidth cache (HBM2), on-card NAND, and even farther out sources like system RAM and network storage.

The basic idea here is that, especially in the professional space, data set size is vastly larger than local storage. So there needs to be a sensible system in place to move that data across various tiers of storage. This may sound like a simple concept, but in fact GPUs do a pretty bad job altogether of handling situations in which a memory request has to go off-package. AMD wants to do a better job here, both in deciding what data needs to actually be on-package, but also in breaking up those requests so that “data management” isn’t just moving around a few very large chunks of data. The latter makes for an especially interesting point, as it could potentially lead to a far more CPU-like process for managing memory, with a focus on pages instead of datasets.
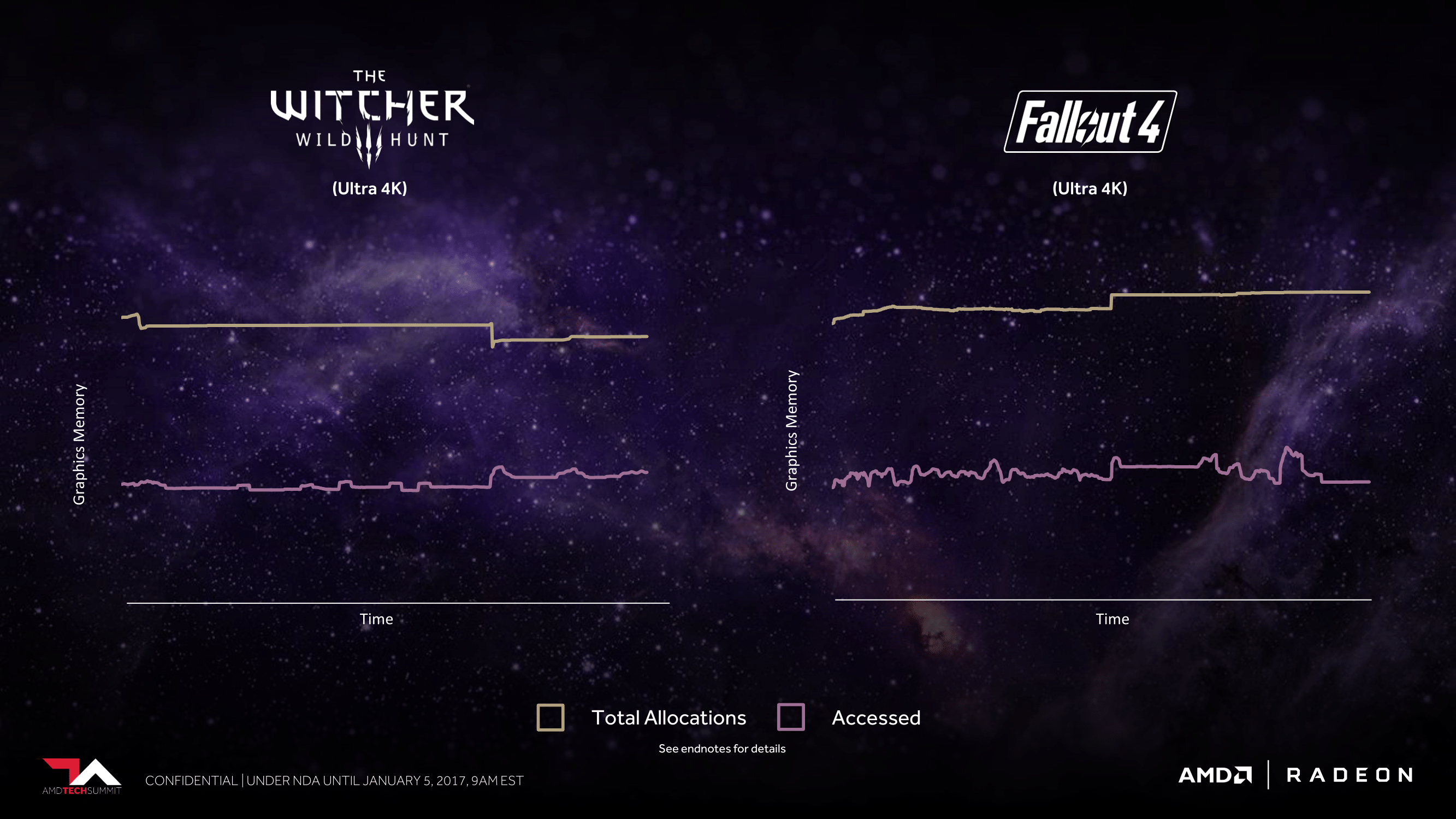
Interestingly, to drive this point home, AMD actually turned to games rather than professional applications. Plotting out the memory allocation and usage patterns of The Witcher III and Fallout 4, AMD finds that both games allocate far more memory than they actually use, by nearly a factor of 2x. Part of this is undoubtedly due to the memory management model of the DirectX 11 API used by both games, but a large factor is also simply due to the fact that this is traditionally what games have always done. Memory stalls are expensive and games tend to be monolithic use cases, so why not allocate everything you can, just to be sure you don’t run out?
The end result here is that AMD is painting a very different picture for how they want to handle memory allocations and caching on Vega and beyond. In the short term it’s professional workloads that stand to gain the most, but in the long run this is something that could impact games as well. And not to be ignored is virtualization; AMD’s foray into GPU virtualization is still into its early days, but this likely will have a big impact on virtualization as well. In fact I imagine it’s a big reason why AMD is giving Vega the ability to support a relatively absurd 512TB of virtual address space, many times the size of local VRAM. Multi-user time-sharing workloads are a prime example of where large address spaces can be useful.
ROPs & Rasterizers: Binning for the Win(ning)
We’ll suitably round-out our overview of AMD’s Vega teaser with a look at the front and back-ends of the GPU architecture. While AMD has clearly put quite a bit of effort into the shader core, shader engines, and memory, they have not ignored the rasterizers at the front-end or the ROPs at the back-end. In fact this could be one of the most important changes to the architecture from an efficiency standpoint.
Back in August, our pal David Kanter discovered one of the important ingredients of the secret sauce that is NVIDIA’s efficiency optimizations. As it turns out, NVIDIA has been doing tile based rasterization and binning since Maxwell, and that this was likely one of the big reasons Maxwell’s efficiency increased by so much. Though NVIDIA still refuses to comment on the matter, from what we can ascertain, breaking up a scene into tiles has allowed NVIDIA to keep a lot more traffic on-chip, which saves memory bandwidth, but also cuts down on very expensive accesses to VRAM.
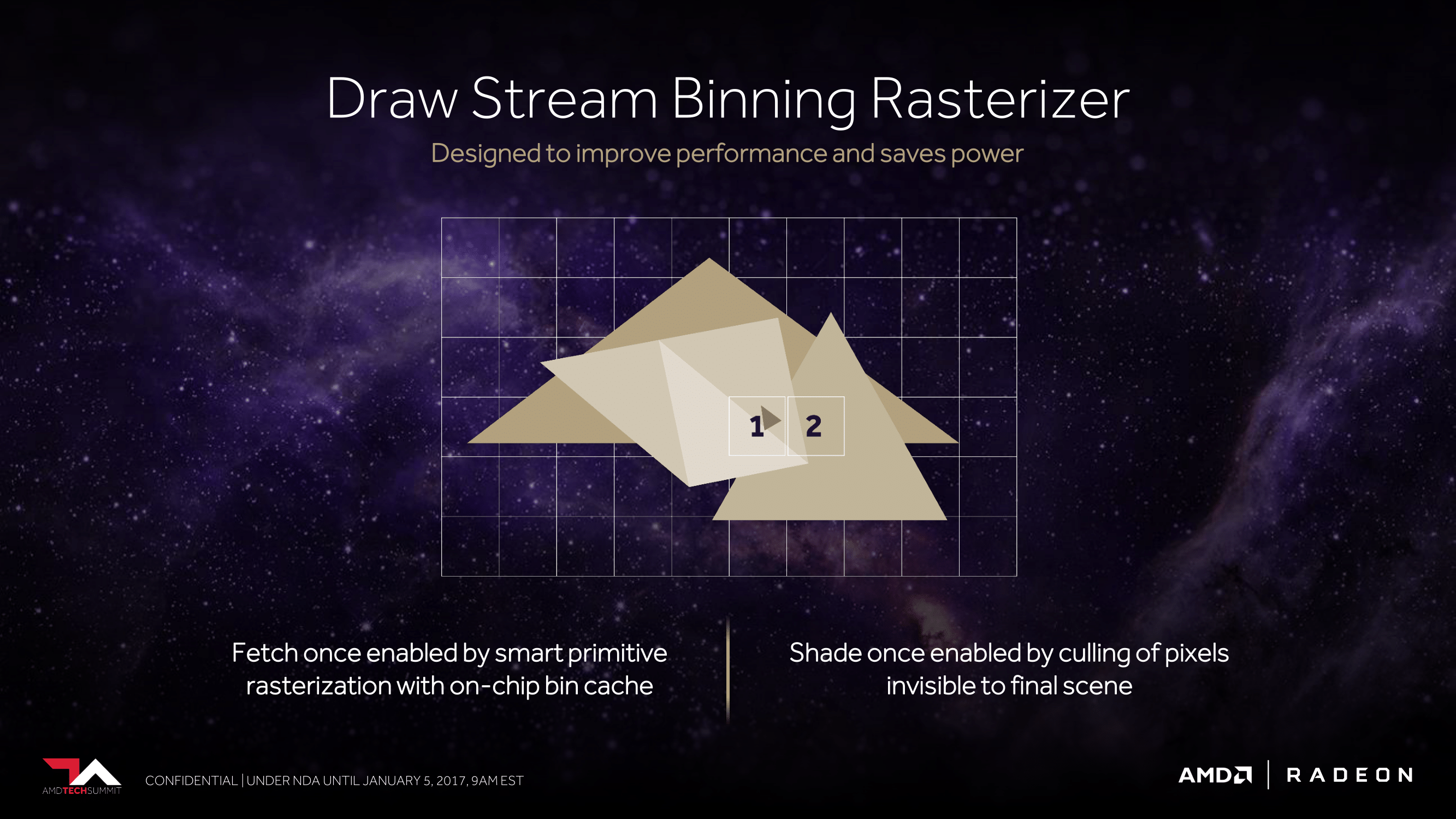
For Vega, AMD will be doing something similar. The architecture will add support for what AMD calls the Draw Stream Binning Rasterizer, which true to its name, will give Vega the ability to bin polygons by tile. By doing so, AMD will cut down on the amount of memory accesses by working with smaller tiles that can stay-on chip. This will also allow AMD to do a better job of culling hidden pixels, keeping them from making it to the pixel shaders and consuming resources there.
As we have almost no detail on how AMD or NVIDIA are doing tiling and binning, it’s impossible to say with any degree of certainty just how close their implementations are, so I’ll refrain from any speculation on which might be better. But I’m not going to be too surprised if in the future we find out both implementations are quite similar. The important thing to take away from this right now is that AMD is following a very similar path to where we think NVIDIA captured some of their greatest efficiency gains on Maxwell, and that in turn bodes well for Vega.
Meanwhile, on the ROP side of matters, besides baking in the necessary support for the aforementioned binning technology, AMD is also making one other change to cut down on the amount of data that has to go off-chip to VRAM. AMD has significantly reworked how the ROPs (or as they like to call them, the Render Back-Ends) interact with their L2 cache. Starting with Vega, the ROPs are now clients of the L2 cache rather than the memory controller, allowing them to better and more directly use the relatively spacious L2 cache.

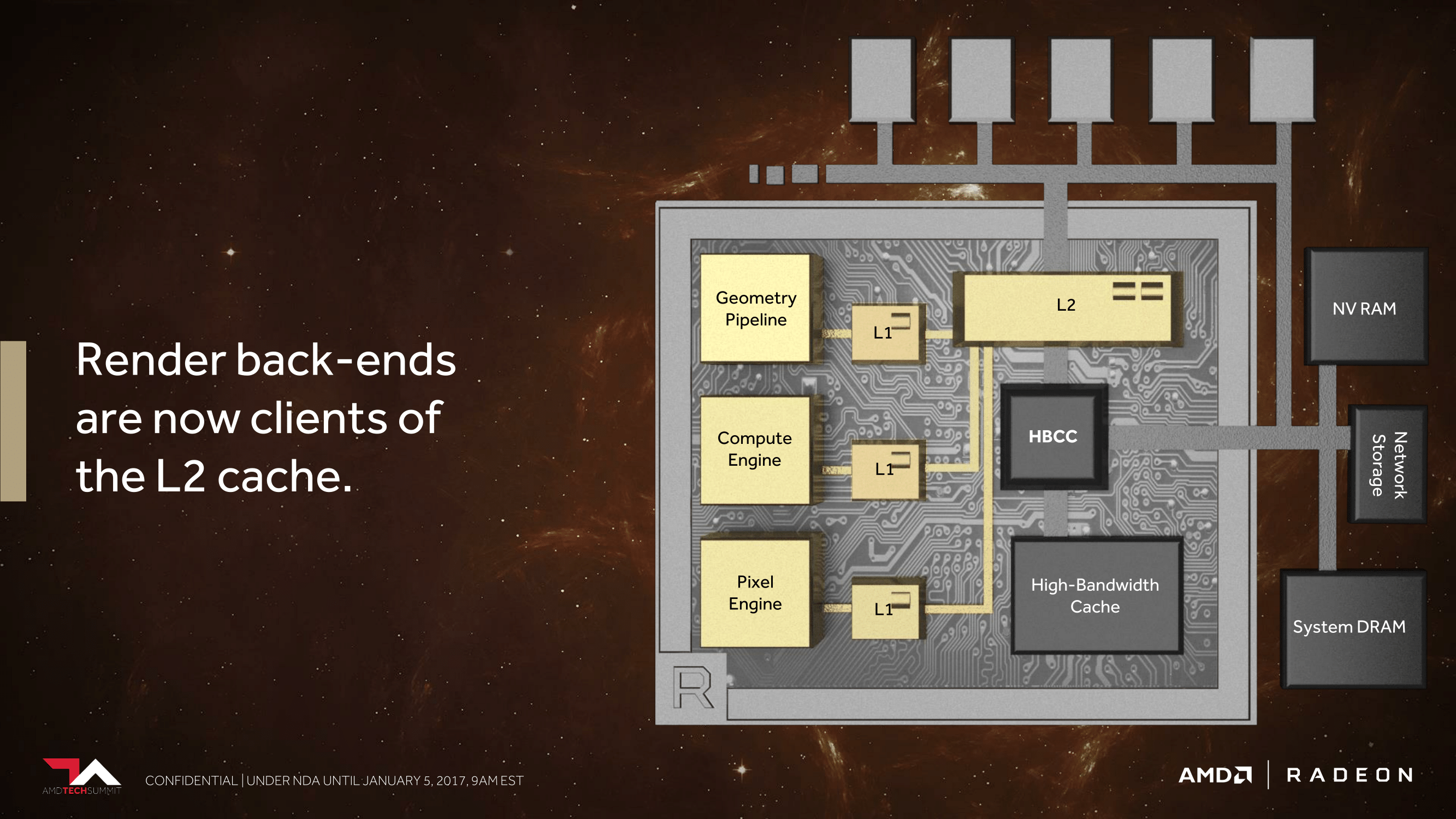
This is especially significant for a specific graphics task, which is rendering to a texture (as opposed to a frame buffer to be immediately displayed). Render to texture is an especially common operation for deferred shading, and while deferred shading itself isn’t new, its usage is increasing. With this change to Vega, the ROPs can now send a scene rendered to a texture to the L2 cache, which can in turn be fetched by the texture units for reuse in the next stage of the rendering process. Any potential performance improvements from this change are going to be especially game-specific since not every game uses deferred shading, but it’s one of those corner cases that is important for AMD to address in order to ensure more consistent performance.








155 Comments
View All Comments
Michael Bay - Friday, January 6, 2017 - link
Here`s your pity comment.Outlander_04 - Thursday, January 5, 2017 - link
Not sure why you think "the desktop graphics game is lost" . In the market segemnts AMD decided to compete in they are winning . Taking market share and out performing nvidia on price and performance.If that scales into the top end then perhaps its nvidia who should consider becoming a maker of mobile graphics chips and abandoning the desktop graphics market ?
Michael Bay - Friday, January 6, 2017 - link
Sure, garbage bin can be seen as some kind of a market too, if you`re desperate enough.negusp - Friday, January 6, 2017 - link
Yeah, no. AMD is actually pretty successful with their current mid-range cards- especially with DX12 and newer drivers the RX 470 kicks 1060 ass.You sound like a butthurt nVidia fanboy scared as hell of Vega DGPs and Ryzen IGPs.
Outlander_04 - Tuesday, January 17, 2017 - link
If the "garbage" is beating nVidia so handily then I think you are agreeing with my original statementLG25 - Friday, July 14, 2017 - link
Watch this video (all of it), and you will see what a sheep you've been.https://www.youtube.com/watch?v=uN7i1bViOkU
IUU - Tuesday, January 10, 2017 - link
Well, maybe you are right, but if desktop/laptop gaming dies completely, your solutions to professionals will be fucked up, and no longer evolve properly. In fact, it is in the interest of the "professionals" to not let this gaming die; if they are smart enough.Not only every new solution will be far more expensive, but it will be much more incremental, to the level of complete stalling. Gaming market, offers from the one hand the economies of scale and from the other the most demanding playground for researchers to develop new solutions.
If you have complerely bought the myth, "that there's the serious computing for every day problems and the amater one for gaming ", think again. It may not seem like this right now, but gaming trends towards simulating reality, albeit with small steps everytime. Believe me, there's nothing more computationally demanding than simulating reality, and gaming is the ideal platform for it.
If those who are in charge don't get it, and let it degrade only to get a tiny and insignificant competitive edge, they will regret it exponentially later.
Gastec - Thursday, January 12, 2017 - link
Aha, it's clear then! This is what gamers are supposed to do now:1. Buy graphics cards from Nvidia, no matter the price.
2. Stop gaming.
Or better yet we should just lay down and die and let the trolls rule the World.
LG25 - Friday, July 14, 2017 - link
Gee. Yet another NVidia sheep. Baaa-a-a-awaltsmith - Thursday, January 5, 2017 - link
So, lets talk pricing already!! lol