The AMD Vega GPU Architecture Teaser: Higher IPC, Tiling, & More, Coming in H1’2017
by Ryan Smith on January 5, 2017 9:00 AM ESTVega’s NCU: Packed Math, Higher IPC, & Higher Clocks
As always, I want to start at the heart of the matter: the shader core. In some respects AMD has not significantly altered their shader core since the launch of the very first GCN parts 5 years ago. Various iterations of GCN have added new instructions and features, but the shader core has remained largely constant, and IPC within the shader core itself hasn’t changed too much. Even Polaris (GCN 4) followed this trend, sharing its whole ISA with GCN 1.2.
With Vega, this is changing. By just how much remains to be seen, but it is clear that even with what we see today, AMD is already undertaking the biggest change to their shader core since the launch of GCN.

Meet the NCU, Vega’s next-generation compute unit. As we already learned from the PlayStation 4 Pro launch and last month’s Radeon Instinct announcement, AMD has been working on adding support for packed math formats for future architectures, and this is coming to fruition in Vega.
With their latest architecture, AMD is now able to handle a pair of FP16 operations inside a single FP32 ALU. This is similar to what NVIDIA has done with their high-end Pascal GP100 GPU (and Tegra X1 SoC), which allows for potentially massive improvements in FP16 throughput. If a pair of instructions are compatible – and by compatible, vendors usually mean instruction-type identical – then those instructions can be packed together on a single FP32 ALU, increasing the number of lower-precision operations that can be performed in a single clock cycle. This is an extension of AMD’s FP16 support in GCN 1.2 & GCN 4, where the company supported FP16 data types for the memory/register space savings, but FP16 operations themselves were processed no faster than FP32 operations.
And while previous announcements may have spoiled that AMD offers support for packed FP16 formats, what we haven’t known for today is that they will also support a high-speed path (analogous to packed FP16) for 8-bit integer operations. INT8 is a data format that has proven especially useful for neural network inference – the actual execution of trained neural networks – and is a major part of what has made NVIDIA’s most recent generation of Pascal GPUs so potent at inferencing. By running dot products and certain other INT8 operations along this path, INT8 performance can be greatly improved.
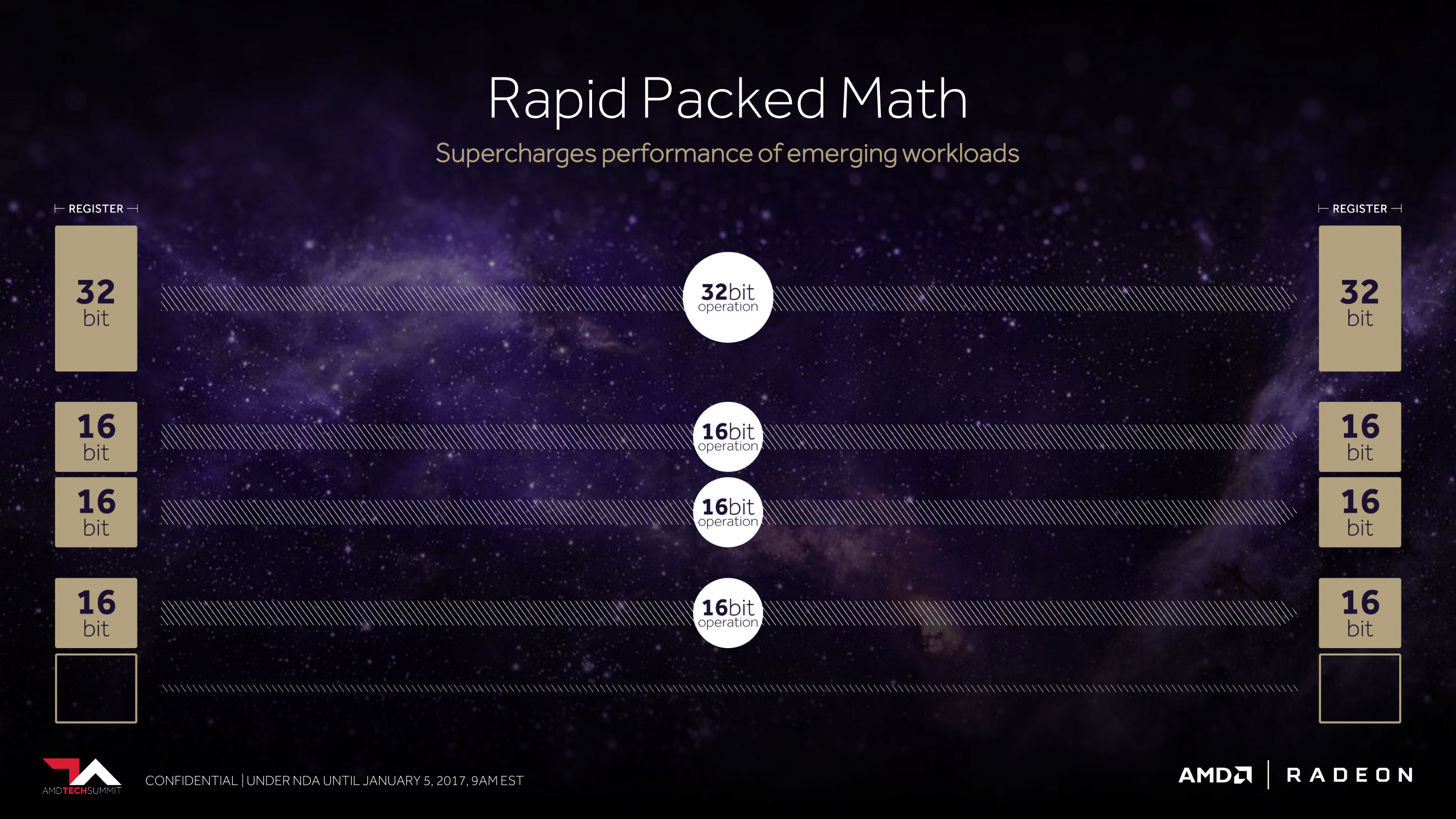
Though before we get too far – and this is a longer discussion to have closer to Vega’s launch – it’s always important to note when and where these faster operations can be used in consumer workloads, as the odds are most of you reading this are thinking gaming. While FP16 operations can be used for games (and in fact are in the mobile space), in the PC space they are virtually never used. When PC GPUs made the jump to unified shaders in 2006/2007, the decision was made to do everything at FP32 since that’s what vertex shaders typically required to begin with, and it’s only recently that anyone has bothered to look back. So while there is some long-term potential here for Vega’s fast FP16 math to become relevant for gaming, at the moment it wouldn’t do anything. Vega will almost certainly live and die in the gaming space based on its FP32 performance.
Moving on, the second thing we can infer from AMD’s slide is that a CU on Vega is still composed of 64 ALUs, as 128 FP32 ops/clock is the same rate as a classic GCN CU. Nothing here is said about how the Vega NCU is organized – if it’s still four 16-wide vector SIMDs – but we can at least reason out that the total size hasn’t changed.

Finally, along with outlining their new packed math formats, AMD is also confirming, at a high level, that the Vega NCU is optimized for both higher clockspeeds and a higher IPC. It goes without saying that both of these are very important to overall GPU performance, and it’s an area where, very broadly speaking, AMD hasn’t compared to NVIDIA too favorably. The devil is in the details, of course, but a higher clockspeed alone would go a long way towards improving AMD’s performance. And as AMD’s IPC has been relatively stagnant for some time here, improving it would help AMD put their relatively sizable lead in total ALUs to good use. AMD has always had a good deal more ALUs than a comparable NVIDIA chip, but getting those ALUs to all do useful work outside of corner cases has always been difficult.
That said, I do think it’s important not to read too much into this on the last point, especially as AMD has drawn this slide. It’s fairly muddled whether “higher IPC” means a general increase in IPC, or if AMD is counting their packed math formats as the aforementioned IPC gain.
Geometry & Load Balancing: Faster Performance, Better Options
As some of our more astute readers may recall, when AMD launched the GCN 1.1 they mentioned that at the time, GCN could only scale out to 4 of what AMD called their Shader Engines; the logical workflow partitions within the GPU that bundled together a geometry engine, a rasterizer, CUs, and a set of ROPs. And when the GCN 1.2 Fiji GPU was launched, while AMD didn’t bring up this point again, they still held to a 4 shader engine design, presumably due to the fact that GCN 1.2 did not remove this limitation.
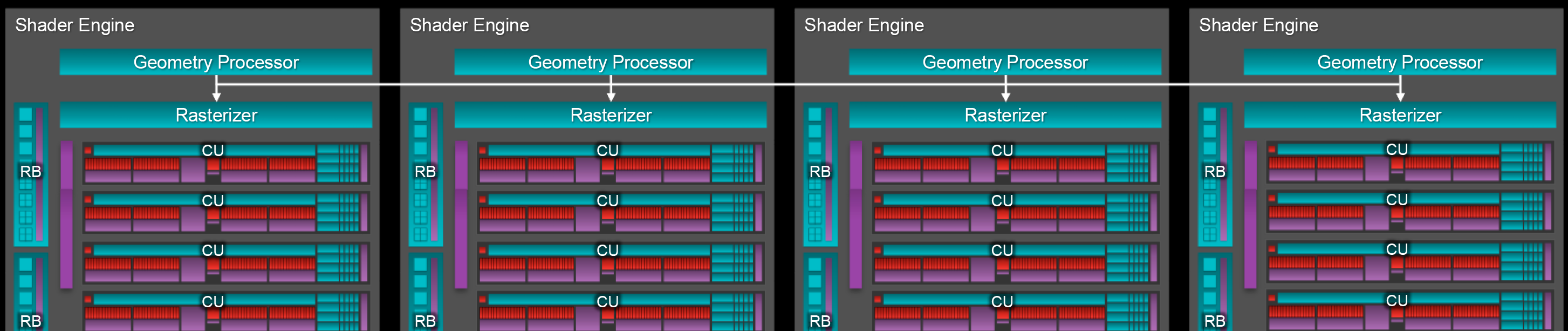
Fiji 4x Shader Engine Layout
But with Vega however, it looks like that limitation has finally gone away. AMD is teasing that Vega offers an improved load balancing mechanism, which pretty much directly hints that AMD can now efficiently distribute work over more than 4 engines. If so, this would represent a significant change in how the GCN architecture works under the hood, as work distribution is very much all about the “plumbing” of a GPU. Of the few details we do have here, AMD has told us that they are now capable of looking across draw calls and instances, to better split up work between the engines.

This in turn is a piece of the bigger picture when looking at the next improvement in Vega, which is AMD’s geometry pipeline. Overall AMD is promising a better than 2x improvement in peak geometry throughput per clock. Broadly speaking, AMD’s geometry performance in recent generations hasn’t been poor (it’s one of the areas where Polaris even further improved), but it has also hurt them at times. So this is potentially important for removing a bottleneck to squeezing more out of GCN.
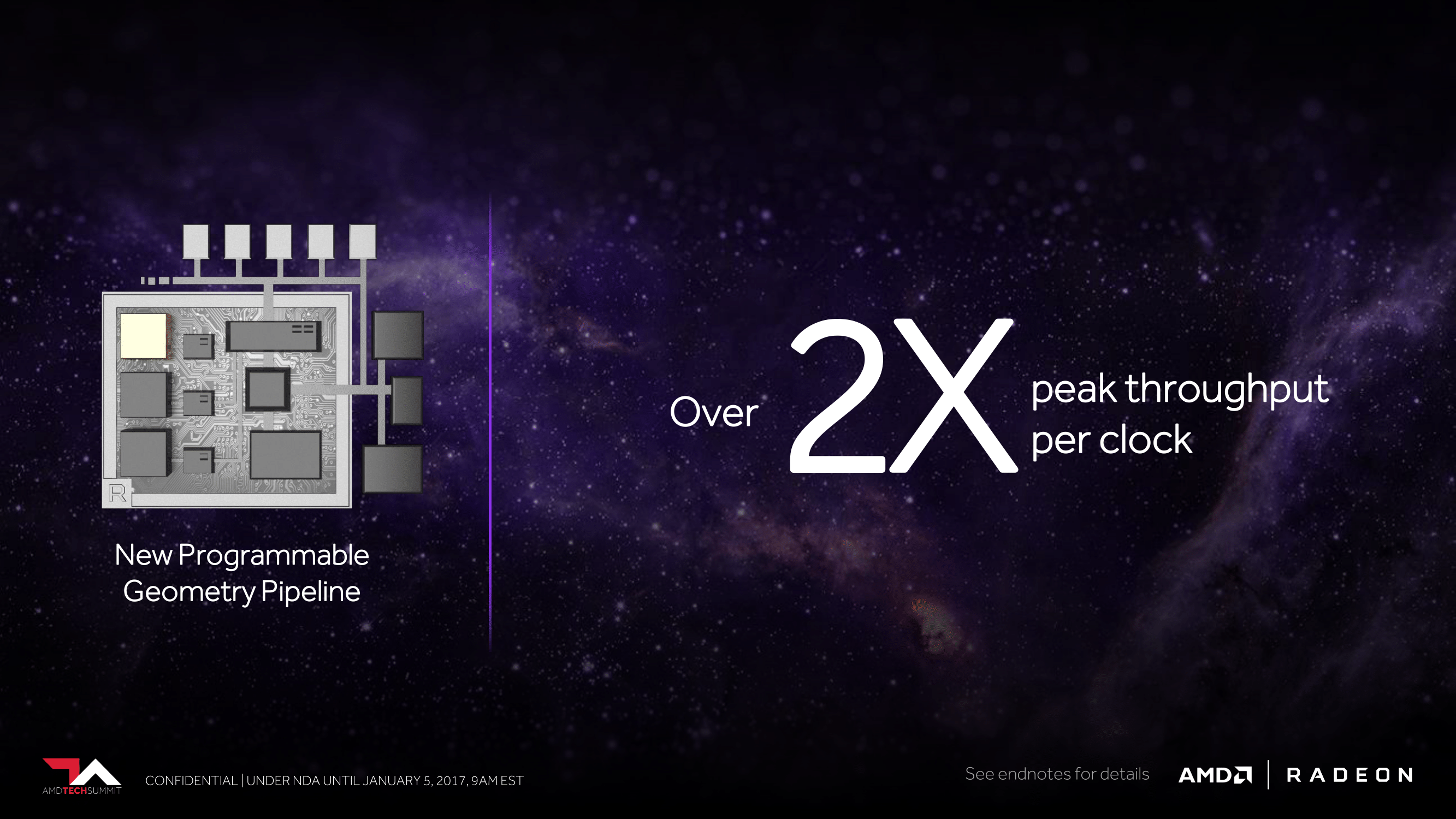
And while AMD's presentation and comments itself don't go into detail on how they achieved this increase in throughput, buried in the footnote for AMD's slide deck is this nugget: "Vega is designed to handle up to 11 polygons per clock with 4 geometry engines." So this clearly reinforces the idea that the overall geometry performance improvement in Vega comes from improving the throughput of the individual geometry engines, as opposed to simply adding more as the scalability improvements presumably allow. This is one area where Vega’s teaser paints a tantalizing view of future performance, but in the process raises further questions on just how AMD is doing it.
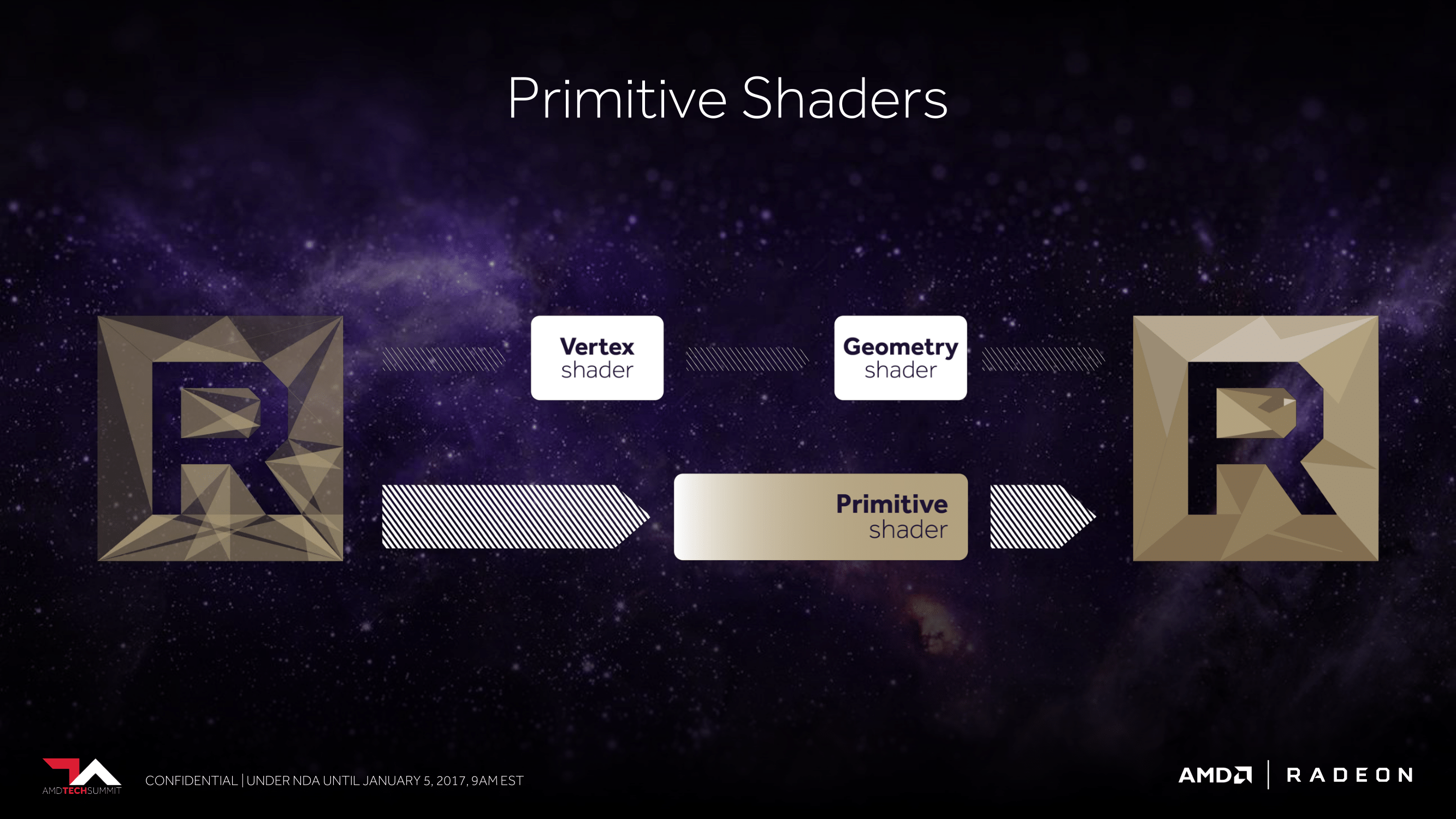
In any case, however AMD is doing it, the updated geometry engines will also feature one more advancement, which AMD is calling the primitive shader. A new shader stage that runs in place of the usual vertex and geometry shader path, the primitive shader allows for the high speed discarding of hidden/unnecessary primitives. Along with improving the total primitive rate, discarding primitives is the next best way to improve overall geometry performance, especially as game geometry gets increasingly fine, and very small, overdrawn triangles risk choking the GPU.
AMD isn’t offering any real detail here in how the primitive shader operates, and as a result I’m curious here whether this is something that AMD’s shader compiler can automatically add, or if it requires developers to specifically call it (like they would vertex and geometry shaders).








155 Comments
View All Comments
silverblue - Thursday, January 5, 2017 - link
Formerly Videologic, changed in 1999 to Imagination Technologies.I had a Kyro II. The first Kyro was clocked at a mere 115MHz for both core and memory, but Kyro II was a whole 60MHz faster. It really worked well in UT when paired with my XP 1700+. :) There was a Kyro II SE with 200MHz clocks but was as rare as rocking horse excrement. I was also very excited about its supposed TnL, DDR-powered successor, but it never launched, which meant bye-bye on the desktop for PowerVR, rather than the bloody nose that ATi and NVIDIA deserved at that time.
wumpus - Friday, January 6, 2017 - link
If my poor memory is remotely accurate (don't bet on it), the chip to run Unreal Tournament was the S3 chip (probably the last they made). Not sure if the "TnL" it supposedly had was fraudulent or defective, but the texture compression (probably only used in Unreal Tournament before S3 died and it became a standard feature) gave the S3 the best visuals in the game.I know I had one of those boards (simply because it was cheap, long after its day) but can't remember how it performed on Unreal Tournament (I may not have bothered putting windows on that box. In those days the best way to connect windows to the internet was to connect a Linux machine to a DSL modem, then connect windows to Linux. Connecting Windows to DSL was asking to get it to blindly reset all your configuration files at random intervals).
BrokenCrayons - Friday, January 6, 2017 - link
You're probably thinking about S3's Savage video card series with the S3 MeTaL API. It's been ages, but I'm pretty sure UT supported MeTaL out of the box. Epic was pretty good about that back when there was a plethora of competing APIs before we settled into DirectX and OpenGL. When I tried to diversify my PC shop by adding an after-hours LAN arcade, we used those graphics cards because they were good for the multiplayer stuff we wanted to run. I do recall they were a bit glitchy under Descent Freespace. There were artifacts around ship engine glow effects and I think it was due to poor DirectX suport, but don't quote me on that, it's been years.silverblue - Friday, January 6, 2017 - link
Yeah, MeTaL was there at retail, as long as you installed the texture pack from the second disc. I had a Savage 4 (Diamond S540) which worked flawlessly... until I flashed the BIOS one day, thereafter it would hang during every session at a random point, thus requiring a reboot. That was a stupid idea, especially considering it looked excellent. Luckily, somebody got the OpenGL mode to work with those textures.I believe the T&L on the Savage 2000 was unfit for purpose; it was broken in hardware so you couldn't coax its true performance out.
silverblue - Friday, January 6, 2017 - link
Sorry, to clarify, you could use MeTaL without the texture pack, but what would be the point? :)Threska - Friday, January 6, 2017 - link
And for the time it was a very nice card. Shame Kyro didn't take offhttps://en.wikipedia.org/wiki/PowerVR
eldakka - Friday, January 6, 2017 - link
I always liked the infinite planes concept (no polygons!) of the PowerVR 1 series. I remember being disappointed at the time, and still am, that infinite planes never caught on. The entire paradigm gave many operations 'for free' that today require a lot of hardware and software support to implement.Threska - Saturday, January 7, 2017 - link
Could have been a patent issue.tarqsharq - Friday, January 6, 2017 - link
I remembering excitedly reading about TBR with an article about the Kyro II on this very website oh so many years ago like you're saying. http://www.anandtech.com/show/735Funny enough, it didn't do well in the market because the APIs at the time weren't very flexible and required a lot of tweaking to it working in each engine pretty much.
The games that it did work well in, the card punched WAY above its cost bracket if I remember correctly.
Jtaylor1986 - Thursday, January 5, 2017 - link
This design has probably been in the works for 3+ years. Nvidia just beat them to market it had nothing to do with David Kanter.