HiSilicon Kirin 960: A Closer Look at Performance and Power
by Matt Humrick on March 14, 2017 7:00 AM EST- Posted in
- Smartphones
- Mobile
- SoCs
- HiSilicon
- Cortex A73
- Kirin 960

HiSilicon’s Kirin 950 proved to be a breakout product for the Huawei subsidiary, ultimately finding a home in many of Huawei’s flagship phones, including the Mate 8, P9, P9 Plus, and Honor 8. Its big.LITTLE combination of four A72 and four A53 CPU cores manufactured on TSMC’s 16nm FF+ FinFET process delivered excellent performance and efficiency. Somewhat surprisingly, it turned out to be one of the best, if not the best, implementation of ARM’s IP we’ve seen.
Because of the 950’s success, we were eager to see what improvements the Kirin 960 could offer. In our review of the Huawei Mate 9, the first device to use the new SoC, we saw gains in most of our performance and battery life tests relative to the Mate 8 and its Kirin 950 SoC. Now it’s time to dive a little deeper and answer some of our remaining questions: How does IPC compare between the A73, A72, and other CPU cores? How is memory performance impacted by the A73’s microarchitecture changes? Does CPU efficiency improve? How much more power do the extra GPU cores consume?
| HiSilicon High-End Kirin SoC Lineup | |||
| SoC | Kirin 960 | Kirin 955 | Kirin 950 |
| CPU | 4x Cortex-A73 @ 2.36GHz 4x Cortex-A53 @ 1.84GHz |
4x Cortex-A72 @ 2.52GHz 4x Cortex-A53 @ 1.81GHz |
4x Cortex-A72 @ 2.30GHz 4x Cortex-A53 @ 1.81GHz |
| GPU | ARM Mali-G71MP8 1037MHz |
ARM Mali-T880MP4 900MHz |
|
| Memory | 2x 32-bit LPDDR4 @ 1866MHz 29.9GB/s |
2x 32-bit LPDDR3 @ 933MHz (14.9GB/s) or 2x 32-bit LPDDR4 @ 1333MHz (21.3GB/s) (hybrid controller) |
|
| Interconnect | ARM CCI-550 | ARM CCI-400 | |
| Storage | UFS 2.1 | eMMC 5.0 | |
| ISP/Camera | Dual 14-bit ISP (Improved) |
Dual 14-bit ISP 940MP/s |
|
| Encode/Decode | 2160p30 HEVC & H.264 Decode & Encode 2160p60 HEVC Decode |
1080p H.264 Decode & Encode 2160p30 HEVC Decode |
|
| Integrated Modem | Kirin 960 Integrated LTE (Category 12/13) DL = 600Mbps 4x20MHz CA, 64-QAM UL = 150Mbps 2x20MHz CA, 64-QAM |
Balong Integrated LTE (Category 6) DL = 300Mbps 2x20MHz CA, 64-QAM UL = 50Mbps 1x20MHz CA, 16-QAM |
|
| Sensor Hub | i6 | i5 | |
| Mfc. Process | TSMC 16nm FFC | TSMC 16nm FF+ | |
The Kirin 960 is the first SoC to use ARM’s latest A73 CPU cores, which seems fitting considering the Kirin 950 was the first to use ARM’s A72. Its CPU core frequencies see a negligible increase relative to the Kirin 950: 1.81GHz to 1.84GHz for the four A53s and 2.30GHz to 2.36GHz for the four A73s. Setting the peak operating point for the A73 cores lower than the 2.52GHz used by Kirin 955’s A72 cores, and lower still than the 2.8GHz that ARM targets for 16nm, is an interesting and deliberate choice by HiSilicon to limit the CPU’s power envelope, allowing the bigger GPU to take a larger chunk.
We’ve already discussed the A73’s microarchitecture in depth, so I’ll just summarize a few of the highlights. For starters, the A73 stems from the A17 and does not belong to the A15/A57/A72 Austin family tree. This means the differences between the A72 and A73 are more substantial than the small change in product numbering would suggest, particularly in the CPU’s front end.
The biggest difference is a reduction in decoder width, which is now 2-wide instead of 3-wide like the A72. This sounds like a downgrade on paper; however, there’s likely some workloads where the A72’s instruction fetch block fails to consistently saturate the decoder, so the actual performance impact of the A73’s narrower decode stage may not be that severe.
In many cases, instruction dispatch throughput should actually improve relative to the A72. The A73’s shorter pipeline reduces front-end latency, including 1-2 fewer cycles for the decoder, which can decode most instructions in a single cycle, and 1 less cycle for the fetch stage. The L1 instruction cache doubles in size and is optimized for better throughput, and changes to the instruction fetch block reduce instruction bubbles. ARM also says the A73 includes a new, more accurate branch predictor, with a larger BTAC (Branch Target Address Cache) structure and a new 64-entry “micro-BTAC” for accelerating branch prediction.
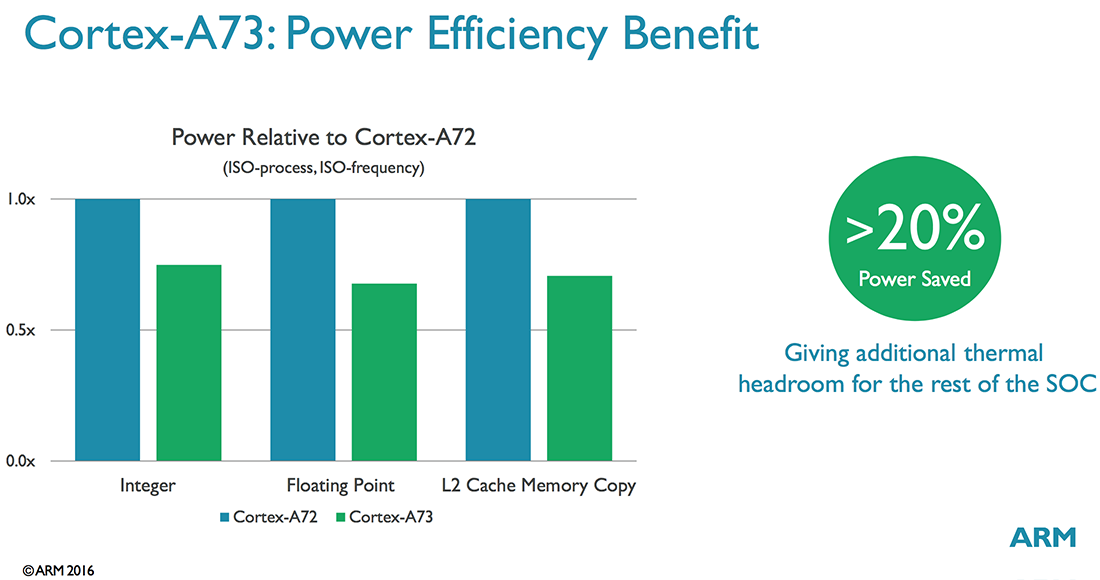
There are several other changes to the front end too, not to mention further along the pipeline, but it should be obvious by now that the A73 is a very different beast than the A72, grown from a different design philosophy. While the Austin family (A72) targeted industrial and low-power server applications in addition to mobile, the A73 focuses specifically on mobile, where power and area become an even higher priority. ARM says the A73 consumes 20%-30% less power than the A72 (same process, same frequency) and is up to 25% smaller (same process, same performance targets).
When it comes to Kirin 960’s GPU, however, HiSilicon is clearly chasing performance instead of efficiency. With its previous SoCs, the Kirin 950/955 in particular, HiSilicon was criticized for using four-core Mali configurations while Samsung packed in eight or twelve Mali cores in its Exynos SoCs and Qualcomm squeezed more ALU resources into its Adreno GPUs. This was not entirely justified, though, because the Kirin 950’s Mali-T880MP4 GPU was capable of playing nearly any game available at acceptable frame rates and the performance difference between the Mate 8 (Kirin 950), Samsung Galaxy S7 edge (Snapdragon 820), and Galaxy S7 (Exynos 8890) after reaching thermal equilibrium is minimal.
Whether in response to this criticism or to enable future use cases such as VR/AR, HiSilicon has significantly increased the Kirin 960’s peak GPU performance. Not only is it the first to use ARM’s latest Mali-G71 GPU, but it doubles core count to eight and boosts the peak frequency to 1037MHz, 15% higher than the 950’s smaller GPU.

The Mali-G71 uses ARM’s new Bifrost microarchitecture, which moves from an SIMD ISA that relied on Instruction Level Parallelism (ILP) to a scalar ISA designed to take advantage of Thread Level Parallelism (TLP) like modern desktop GPU architectures from Nvidia and AMD. I’m not going to explain the difference in depth here, but basically this change allows better utilization of the shader cores, increasing throughput and performance. ARM’s previous Midgard microarchitecture needed to extract 4 instructions from a single thread and execute them concurrently to achieve full utilization of a single shader core, which is not easy to do consistently. In contrast, Bifrost can group 4 separate threads together on a shader core and execute a single instruction from each one, which is more inline with modern graphics and compute workloads.
Now that we have a better understanding for Kirin 960’s design goals—better efficiency for the CPU and higher peak performance for the GPU—and a summary of the hardware changes HiSilicon made to achieve them, we’re ready to see how the performance and power consumption of the Kirin 960 compares to the 950/955 and other recent SoCs.








86 Comments
View All Comments
Eden-K121D - Tuesday, March 14, 2017 - link
Samsung onlyMeteor2 - Wednesday, March 15, 2017 - link
I think the 820 acquitted itself well here. The 835 could be even better.name99 - Tuesday, March 14, 2017 - link
"Despite the substantial microarchitectural differences between the A73 and A72, the A73’s integer IPC is only 11% higher than the A72’s."Well, sure, if you're judging by Intel standards...
Apple has been able to sustainabout a 15% increase in IPC from A7 through A8, A9, and A10, while also ramping up frequency aggressively, maintaining power, and reducing throttling. But sure, not a BAD showing by ARM, the real issue is will they keep delivering this sort of improvement at least annually?
Of more technical interest:
- the largest jump is in mcf. This is a strongly memory-bound benchmark, which suggests a substantially improved prefetcher. In particular simplistic prefetchers struggle with it, suggesting a move beyond just next-line and stride prefetchers (or at least the smarts to track where these are doing more harm than good and switch them off.) People agree?
- twolf appears to have the hardest branches to predict of the set, with vpr coming up second. So it's POSSIBLE (?) that their relative shortcomings reflect changes in the branch/fetch engine that benefit
most apps but hurt specifically weird branching patterns?
One thing that ARM has not made clear is where instruction fusion occurs, and so how it impacts the two-decode limit. If, for example, fusion is handled (to some extent anyway) as a pre-decode operation when lines are pulled into L1I, and if fusion possibilities are being aggressively pursued [basically all the ideas that people have floated --- compare+branch, large immediate calculation, op+storage (?), short (+8) branch+op => predication like POWER8 (?)] there could be a SUBSTANTIAL fraction of fused instruction going through the system so that the 2-wide decode is basically as good as the 3-wide of A72?
fanofanand - Wednesday, March 15, 2017 - link
Once WinArm (or whatever they want to call it) is released, we will FINALLY be able to compare apples to apples when it comes to these designs. Right now there are mountains of speculation, but few people actually know where things are at. We will see just how performant Apple's cores are once they can be accurately compared to Ryzen/Core designs. I have the feeling a lot of Apple worshippers are going to be sorely disappointed. Time will tell.name99 - Wednesday, March 15, 2017 - link
We can compare Apple's ARM cores to the Intel cores in Apple laptops today, with both GeekBench and Safari. The best matchup I can find is this:https://browser.primatelabs.com/v4/cpu/compare/177...
(I'd prefer to compare against the MacBook 12" 2016 edition with Skylake, but for some reason there seem to be no GB4 results for that.)
This compares an iPhone (so ~5W max power?) against a Broadwell that turbo's up to 3.1 GHz (GB tends to run everything at the max turbo speed bcs it allows the core to cool between the [short] tests), and with TDP of 15W.
Even so, the performance is comparable. When you normalize for frequency, you get that A10 is about 20% better IPC, so drops down to maybe 15% better IPC for Skylake.
Of course that A10 runs at a lower (peak) frequency --- but also at much lower power.
There's every reason to believe that the A10X will beat absolutely the equivalent Skylake chip in this class (not just m-class but also U-class), running at a frequency of ?between 3 and 3.5GHz? while retaining that 15-20% IPC advantage over Skylake and at a power of ?<10W?
Hopefully we'll see in a few weeks --- the new iPads should be released either end March or beginning April.
Point is --- I don't see why we need to wait for WinARM server --- specially since MS has made no commitment to selling WinARM to the public, all they've committed to is using ARM for Azure.
Comparing GB4 or Safari on Apple devices gives us comparable compilers, comparable browsers, comparable OSs, comparable hardware design skill. I don't see what a Windows equivalent brings to the table that adds more value.
joms_us - Wednesday, March 15, 2017 - link
Bwahaha keep dreamin iTard, GB is your most trusted benchmark. =DWhy don't you run both machine with A10 and Celeron released in 2010. You will see how pathetic your A10 is in realworld apps.
name99 - Wednesday, March 15, 2017 - link
When I was 10 years old, I was in the car and my father and his friend were discussing some technical chemistry. I was bored with this professional talk of pH and fractionation and synthesis, so after my father described some particular reagent he'd mixed up, I chimed in with "and then you drank it?", to which my father said "Oh be quiet. Listen to the adults and you might learn something." While some might have treated this as a horrible insult, the cause of all their later failures in life, I personally took it as serious advice and tried (somewhat successfully) to abide by it, to my great benefit.Thanks Dad!
Relevance to this thread is an exercise left to the reader.
joms_us - Wednesday, March 15, 2017 - link
Even the latest Ryzen is just barely equal or faster than Skylake clock per clock so what makes you think a worthless low-powered mobile chip will surpass them? A10 is not even better than SD821 on real-world apps comparison. Again real-world apps not Antutu, not Geekbench.zodiacfml - Wednesday, March 15, 2017 - link
Intel's chips are smaller than Apple's. Apple also has the luxury to spend much on the SoC.Andrei Frumusanu - Tuesday, March 14, 2017 - link
Stamp of approval.