Intel to Offer Socketed 56-core Cooper Lake Xeon Scalable in new Socket Compatible with Ice Lake
by Dr. Ian Cutress on August 6, 2019 8:01 AM EST- Posted in
- CPUs
- Intel
- Xeon
- 14nm
- 10nm
- Xeon Platinum
- Ice Lake
- Xeon Scalable
- Cooper Lake

Today Intel is announcing some of its plans for its future Xeon Scalable platform. The company has already announced that after the Cascade Lake series of processors launched this year that it will bring forth another generation of 14nm products, called Cooper Lake, followed by its first generation of 10nm on Xeon, Ice Lake. Today’s announcement relates to the core count of Cooper Lake, the form factor, and the platform.
Today Intel is confirming that it will be bringing its 56-core Xeon Platinum 9200 family to Cooper Lake, so developers can take advantage of its new bfloat16 instructions with a high core count. On top of this, Intel is also stating that the new CPUs will be socketed, unlike the 56-core Cascade Lake CPUs which are BGA only. In order to necessitate the socketing of the product, this means that a new socket is required, which Intel has confirmed will also support Ice Lake in the same socket. According to one of our sources, this will be an LGA4189 product.
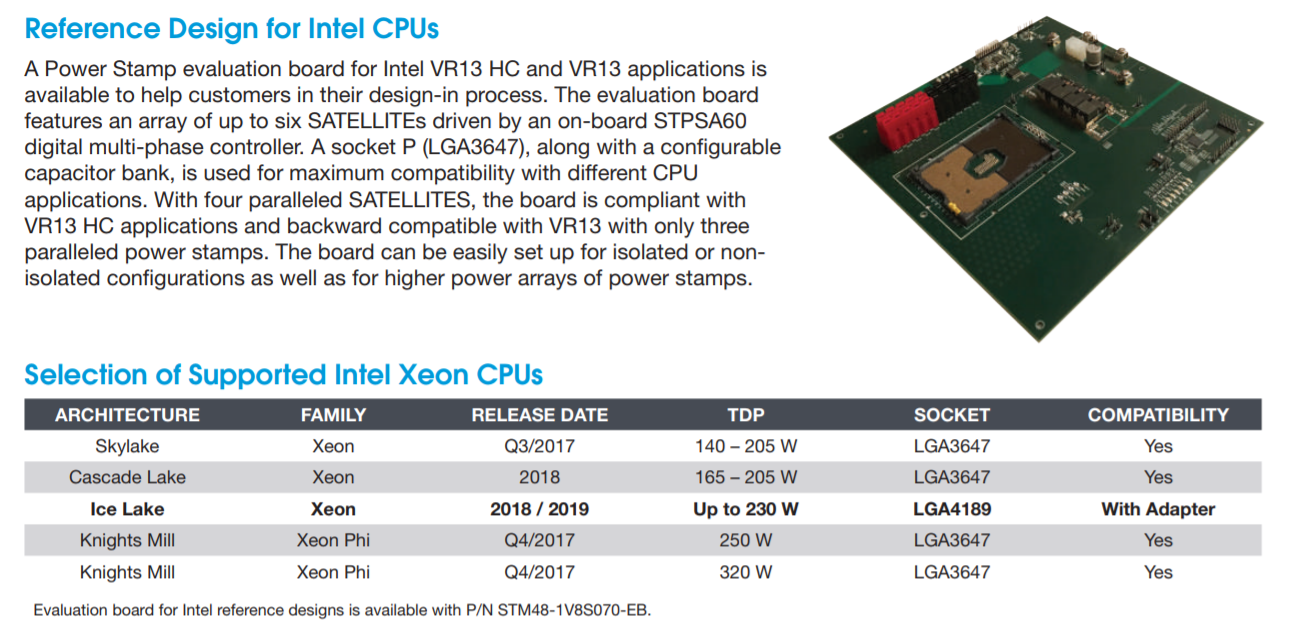
Based on our research, it should be noted that we expect bfloat16 support to only be present in Cooper Lake and not Ice Lake. Intel has stated that the 56-core version of Cooper Lake will be in a similar format to its 56-core Cascade Lake, which we take to mean that it is two dies on the same chip and limited to 2S deployments, however based on our expectations for Ice Lake Xeon parts, we have come to understand that there will be eight memory channels in the single chip design, and perhaps up to 16 memory channels with the dual-die 56-core version. (It will be interesting to see 16 channels at 2DPC on a 2S motherboard, given that 12 channels * 2DPC * 2S barely fits into a standard 19-inch chassis.)
Intel’s Lisa Spelman, VP of the Data Center Group and GM of Xeon, stated in an interview with AnandTech last year that Cooper Lake will be launched in 2019, with Ice Lake as a ‘fast follow-on’, expected in the middle of 2020. That’s not a confirmation that the 56-core version of Cooper will be in 2019, but this is the general cadence for both families that Intel is expected to run to.

At Intel’s Architecture Day in December 2018, Sailesh Kottapalli showed off an early sample of Ice Lake Xeon silicon. At the time I was skeptical, given that Intel’s 10+ process still looked like it was having yield issues with small quad-core chips, let alone large Xeon-like designs. Cooper Lake on 14nm should easily be able to be rolled into a dual-die design, like Cascade Lake, so it will be interesting to see where 10nm Ice Lake Xeon will end up.
Intel states that 56-core based Cascade Lake-AP Xeon Scalable systems are currently available as part of pre-built systems from major OEMs such as Atos, HPE, Lenovo, Penguin Computing, Megware, and authorized resellers. Given that Cooper Lake 56-core will be socketed, I would imagine that the design should ultimately be more widely available.
Related Reading
- Intel Xeon Update: Ice Lake and Cooper Lake Sampling, Faster Future Updates
- Power Stamp Alliance Exposes Ice Lake Xeon Details: LGA4189 and 8-Channel Memory
- Intel's Xeon Cascade Lake vs. NVIDIA Turing: An Analysis in AI
- Intel Architecture Manual Updates: bfloat16 for Cooper Lake Xeon Scalable Only?
- Some Cascade Lake Xeon Scalable Processor Specifications Exposed in SI Documents
- Cisco Documents Shed Light on Cascade Lake, Cooper Lake, and Ice Lake for Servers
- Intel's Architecture Day 2018: The Future of Core, Intel GPUs, 10nm, and Hybrid x86








42 Comments
View All Comments