AMD Moves From Infinity Fabric to Infinity Architecture: Connecting Everything to Everything
by Dr. Ian Cutress on March 5, 2020 5:15 PM EST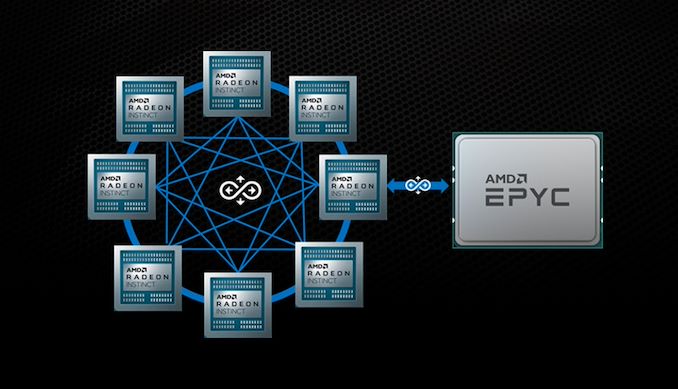
Another element to AMD’s Financial Analyst Day 2020 was the disclosure of how the company intends to evolve its interconnect strategy with its Infinity Fabric (IF). The plan over the next two generations of products is for the IF to turn into its own architectural design, no longer just between CPU-to-CPU or GPU-to-GPU, and future products will see a near all-to-all integration.
AMD introduced its Infinity Fabric with the first generation of Zen products, which was loosely described as a superset of Hypertransport allowing for fast connectivity between different chiplets within AMD’s enterprise processors, as well as between sockets in a multi-socket server. With Rome and Zen 2, the company unveiled its second generation IF, providing some more speed but also GPU-to-GPU connectivity.
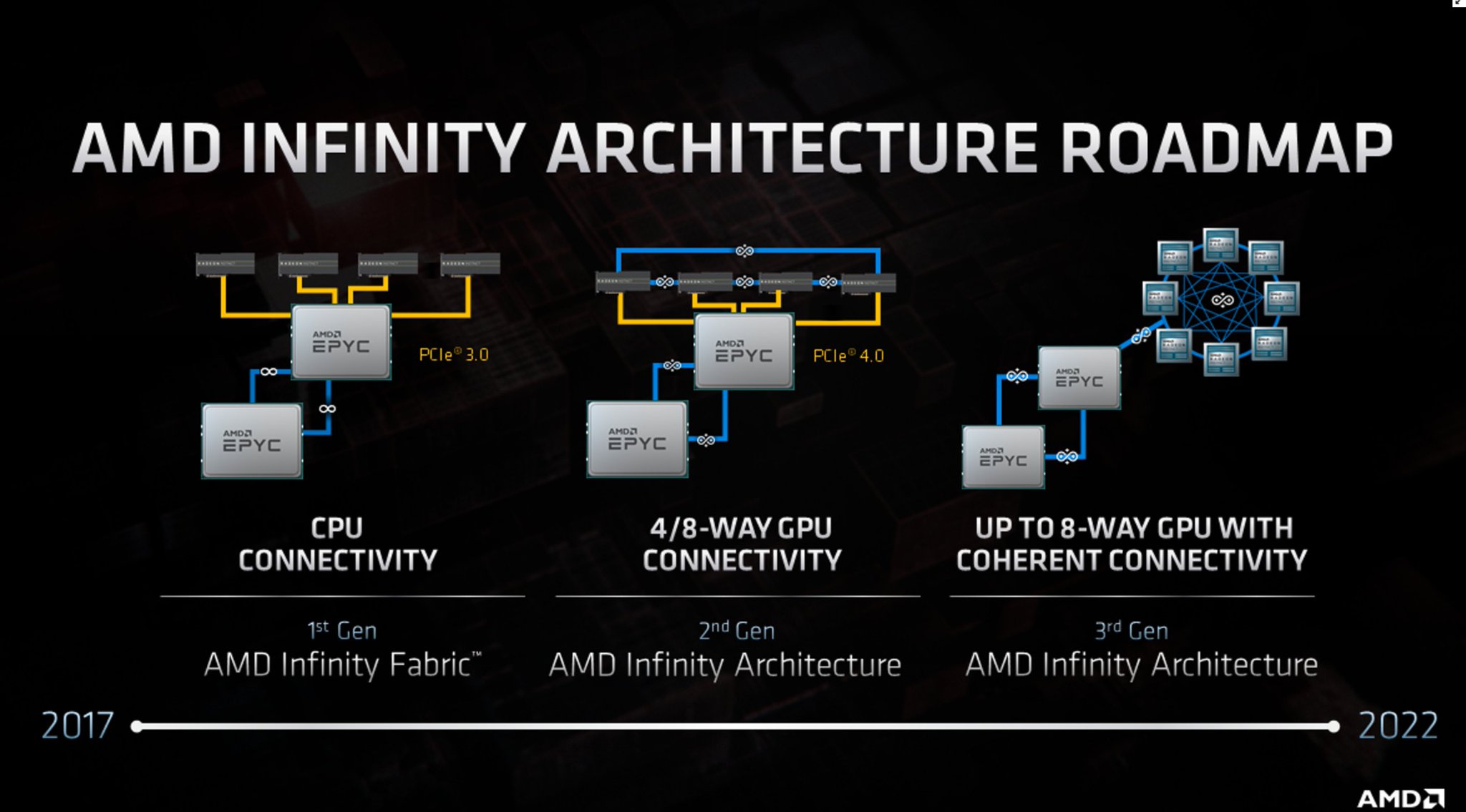
This second generation design allowed two CPUs to be connected, as well as four GPUs to be connected in a ring, however the CPU-to-GPU connection was still based in PCIe. With the next generation, now dubbed Infinity Architecture, the company is scaling it not only to allow for an almost all-to-all connection (6 links per GPU) for up to eight GPUs, but also for CPU-to-GPU connectivity. This should allow for a magnitude of improved operation between the two, such as unified memory spaces and the benefits to come with that. AMD is citing a considerable performance uplift with this paradigm.

AMD and LLNL recently disclosed that the new El Capitan supercomputer will have the latest generation Infinity Architecture installed, with 1 Zen 4-based Genoa EPYC CPU to 4 GPUs. This puts the timeline for this feature in the ballpark of early 2022.

Interested in more of our AMD Financial Analyst Day 2020 Coverage? Click here.












18 Comments
View All Comments
basix - Friday, March 6, 2020 - link
About the 6 IF Links: Ins't it much more likely, that it will be 8 Links? Then you get a direct all to all connectivity with 7 links. The CPU would have a direct link to all GPUs as well (the 8th link). This would be true all to all connectivity with maximum bandwidth and minimum latency.With 8 IF links, the HPC / Super Computer configuration for Frontier and El Capitan makes much more sense. Again, with direct all to all connectivity you need 4 links for each CPU and GPU. But because it is a Super Computer you want to have more bandwidth. Now just double the IF width for each link and you get there. And again 8 links makes very much sense.
6 IF links would be possible, that is true. But you get an asymmetry of the network. With 8 links this asymmetry disappears. So I suspect, that the 6 links shown are just a artwork related reason.
Santoval - Friday, March 6, 2020 - link
6 IF links is probably the maximum they could manage per graphics card. Sure, with 6 IF links instead of an all-to-all interconnect you get a *near* all-to-all. It is not fully symmetric and it's less clean, but it might just be the most they could reach.basix - Friday, March 6, 2020 - link
Yeah, cost is an issue.But then, something like a NVLink switch would make very much sense as well, because you could reduce the number of links per GPU and at the same time increase overall bandwidth between all GPUs.
Brane2 - Friday, March 6, 2020 - link
IMO it's not about the links, but the cost of underlying coherence (MOESI etc) circuitry.Brane2 - Friday, March 6, 2020 - link
I wonder what will IF be able to achieve with CPU clusters at that point.Will it be similarly capable of connecting up to 6 dies on one chip ?
Or will they unfurl that "hypercube" and we'd get more silicon dies, some requiring one hop.
I know about star topology and I/O chiplet, but it could be interesting if one could get a chip with more CPU dies ( perhaps stacked ), with only some in the group being connected to the I/O complex directly.
JasonMZW20 - Saturday, March 7, 2020 - link
6 links is still good for 300GB/s bidirectionally (each link is 25GB*2). I think the fabric power consumption becomes a larger issue with more links, as does diminishing returns. If we assume each bidirectional link costs 12.5W (don't have actual figures, so hypothetically), that's 75W right off the bat. It makes sense, now, that Arcturus' GPU power consumption is a mere 200W. With 6 links, they push the GPU right up to 275W, and that's with display, graphics, and pixel engines completely gutted (rumored) for pure compute use in a server (or supercomputer).300GB/s is based on current PCIe 4.0. This could about double, via PCIe 5.0, by the time El Capitan is ready. That's quite a bit of bandwidth to keep those workloads moving, but still lagging behind 1TB/s+ of HBM2/HBM2e VRAM when using 4 modules and 4096-bit bus.
We may see 8 links and all-to-all for 8 GPUs if the power consumption can be tamed. That's probably the largest issue right now. I'm not totally sure if this is the case, but logically, it makes sense.
If we count all 6 IF links in all 8 GPUs (48 links * 50GB/s), that's an aggregate system bandwidth of 2.4TB/s bidirectionally. Looks pretty decent when examined as a whole cluster.
pogsnet - Thursday, March 12, 2020 - link
We needed updated OS perhaps Windows 11 so soon to compensate for this fast innovations.jaker788 - Saturday, May 23, 2020 - link
Pretty sure Microsoft said windows 10 was the last version at least for a long time. 10 is their evolving platform that gets major and incremental updates from time to time.