Arm Announces Ethos-N78 NPU: Bigger And More Efficient
by Andrei Frumusanu on May 27, 2020 10:00 AM EST
Yesterday Arm released the new Cortex-A78, Cortex-X1 CPUs and the new Mali-G78 GPU. Alongside the new “key” IPs from the company, we also saw the reveal of the newest Ethos-N78 NPU, announcing Arm’s new second-generation design.
Over the last few years we’ve seen a literal explosion of machine learning accelerators in the industry, with a literal wild west of different IP solutions out there. On the mobile front particularly there’s been a huge amount of different custom solutions developed in-house by SoC vendors, this includes designs such as from Qualcomm, HiSilicon, MediaTek and Samsung LSI. For vendors who do not have the design ability to deploy their own IP, there’s the possibility of licensing something from an IP vendor such as Arm.
Arm’s “Ethos” machine learning IP is aimed at client-side inferencing workloads, originally described as “Project Trillium” and the first implementation seeing life in the form of the Ethos-N77. It’s been a year since the release of the first generation, and Arm has been working hard on the next iteration of the architecture. Today, we’re covering the “Scylla” architecture that’s being used in the new Ethos-N78.

From a very high-level view, what the N78 promises is a quite large boost both in performance and efficiency. The new design scales up much higher than the biggest N77 configuration, now being able to offer 2x the peak performance at up to 10TOPs of raw computational throughput.
Arm has revamped the design of the NPU for better power efficiency, enabled through various new compression techniques as well as an improvement in external memory bandwidth per inference of up to 40%.

Strong points of the N78 are the IP’s ability to scale performance across different configuration options. The IP is available at 4 different performance points, or better said at four different distinct engine configurations, from the smallest config at 1TOPs, to 2, 5 and finally a maximum of 10TOPs. This corresponds to MAC configurations of 512, 1024, 2048 and 4096 units for the totality of the design.
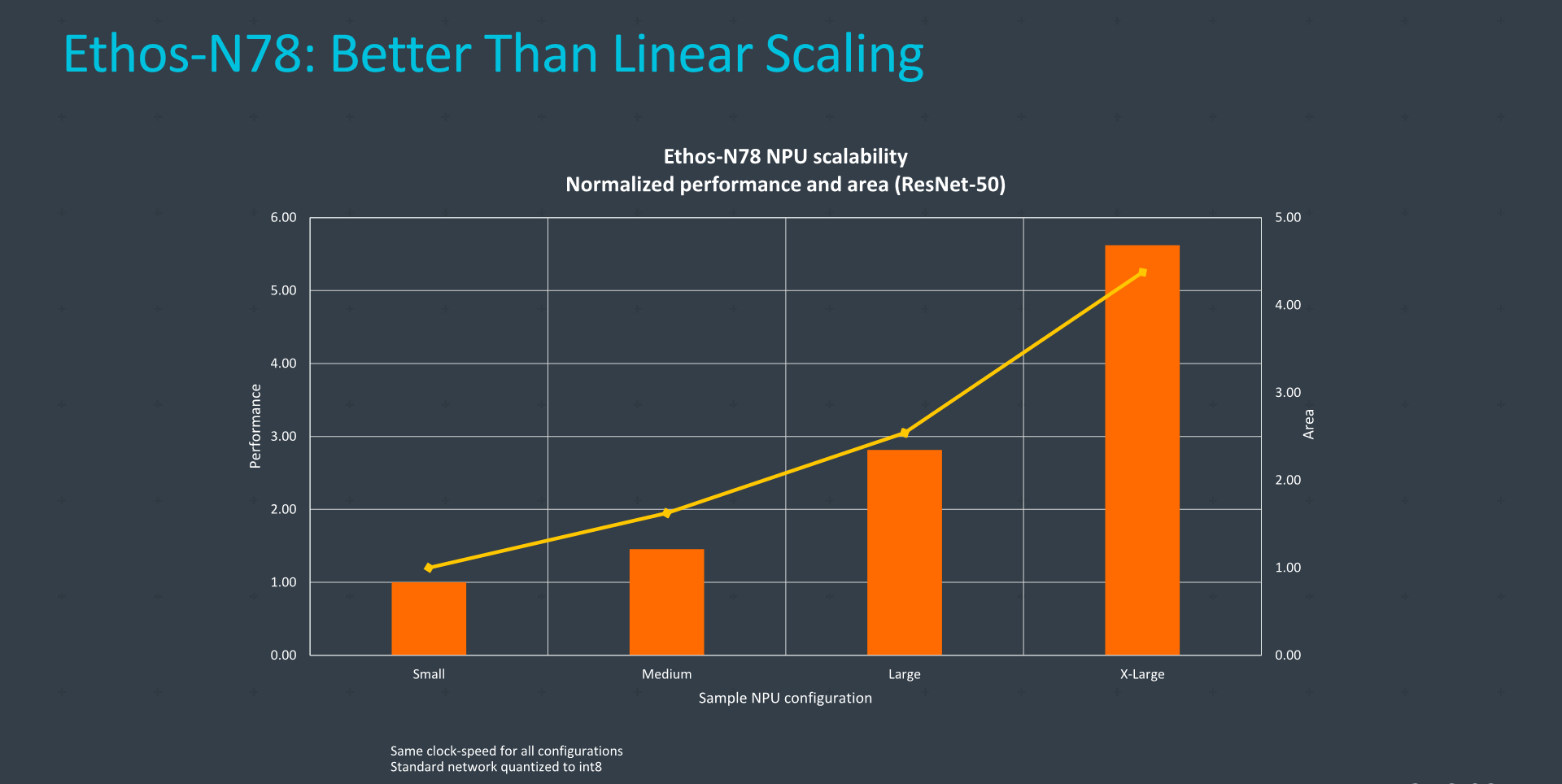
The interesting aspect of scaling bigger is that the area efficiency of the IP actually scales better the bigger the implementation, due to probably the fact that the unique fixed shared function blocks area percentage shrinks with the more computation engines the design has.
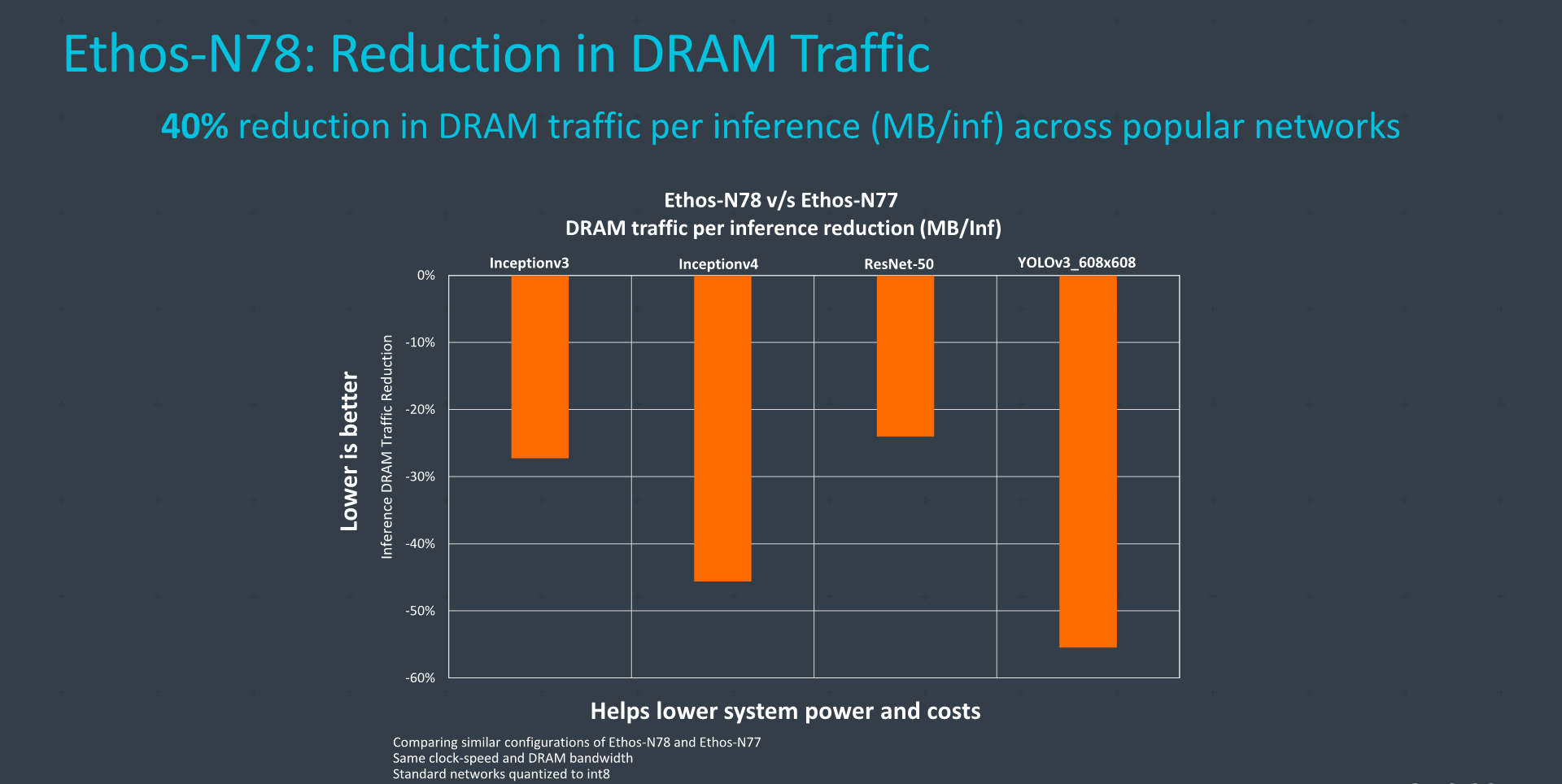
Architecturally, the biggest improvements of the new N78 were in the way it handles data around in the engines, enabling new compression methods for data that not only goes outside the NPU (DRAM bandwidth improvement), but also data movement within the NPU itself, improving efficiency for both performance and power.
The new compression and data handling can significantly reduce the bandwidth of the system with an average 40% reduction across workloads – which is an extremely impressive figure to showcase between IP generations.
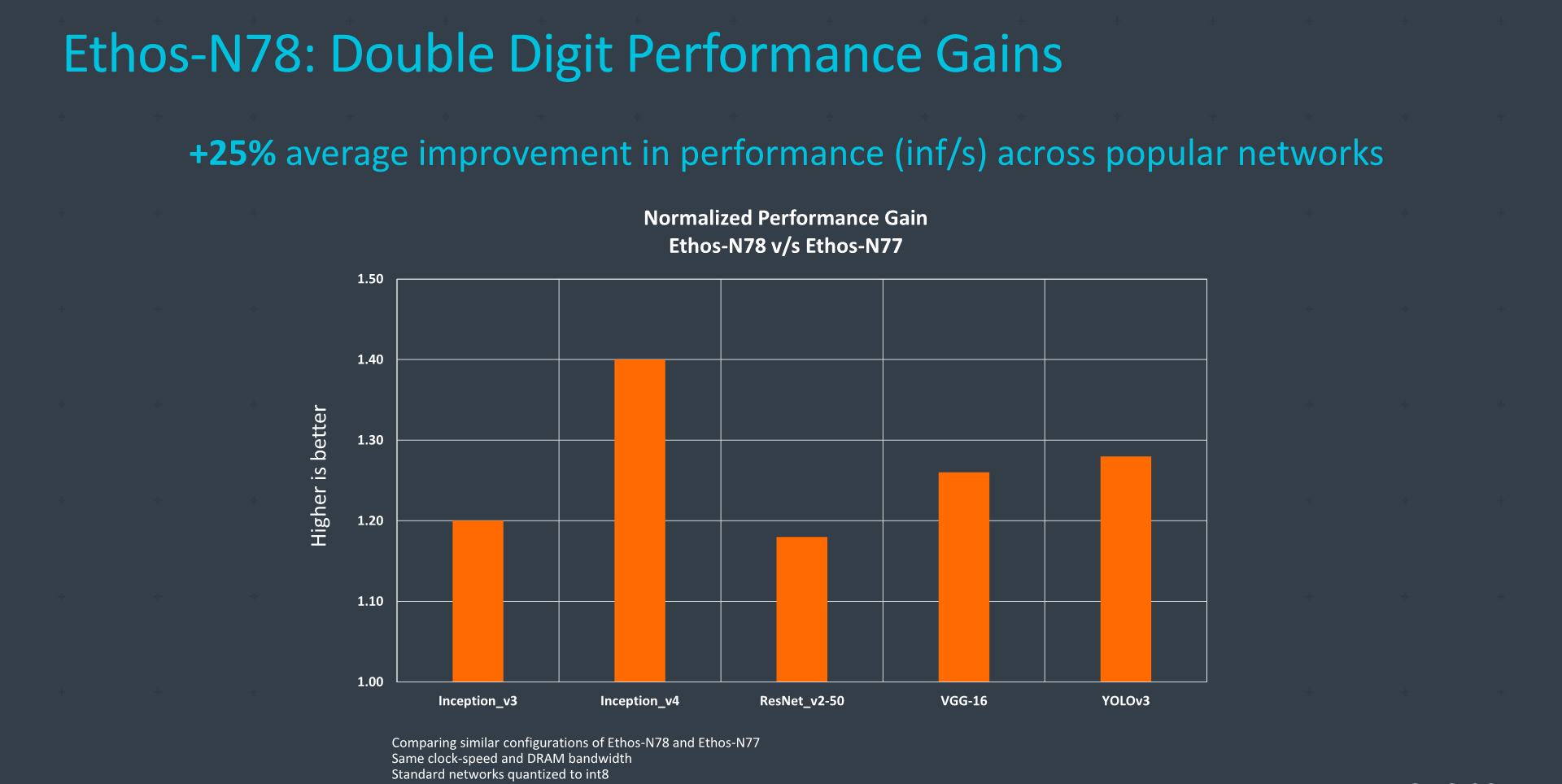
Generational performance uplifts, thanks to the higher performance density and power efficiency are on average 25%, which along with the doubled peak performance configuration means that it has the potential to represent a large boost in end devices.
It’s quite hard to analyse NPUs on how they perform in the competitive landscape – particularly here in Arm’s case given that we haven’t yet seen the first generation NPU designs in silicon. One interesting remark that Arm has made, is that in this space, software matters more than anything else, and a bad software stack can possibly ruin what otherwise would be a good hardware design. Arm mentioned they’ve seen vendors adopt their own Ethos IP and dropping competitor designs because of this – Arm says they invest a very large amount of resources into software in order to facilitate customers to actually properly make use of their hardware designs.
Arm’s new Ethos-N78 has already been licensed out to customers and they’re taping in their designs with it, with likely the first products seeing the light of day in 2021 at the earliest.
Related Reading:
- Arm Announces New Ethos-N57 and N37 NPUs, Mali-G57 Valhall GPU and Mali-D37 DPU
- ARM Details "Project Trillium" Machine Learning Processor Architecture
- Imagination Goes Further Down the AI Rabbit Hole, Unveils PowerVR Series3NX Neural Network Accelerator
- CEVA Announces NeuPro-S Second-Generation NN IP
- Cadence Announces Tensilica Vision Q7 DS








34 Comments
View All Comments
Stochastic - Wednesday, May 27, 2020 - link
Also, the word "veritable" works in this context.Valantar - Thursday, May 28, 2020 - link
I hope nobody got hurt! Also, I wonder where that "literal wild west" is. Western... China? Or is it a subtle reference about Silicon Valley and its general "go fast and break things" attitude? I mean, that's in the western US, and it's pretty wild in many ways (few of them good, just like the wild west of old).On a more serious note: please don't use "literal" when you are using words in a metaphorical manner. I get that that's a thing these days, and I suppose one could claim it is some sort of ironic postmodernist satire (a few decades too late if that is the case), but generally it just makes you look like you don't understand what words mean.
Spunjji - Friday, May 29, 2020 - link
100% on the above. I felt a little bit like I was being trolled with the use of "literal" to mean "figurative" twice in two consecutive sentences 😅surt - Wednesday, June 3, 2020 - link
You may not be aware, but literally now literally means figuratively. It's in the dictionary.www.merriam-webster.com/dictionary/literally
"2: in effect : VIRTUALLY —used in an exaggerated way to emphasize a statement or description that is not literally true or possible"
eastcoast_pete - Wednesday, May 27, 2020 - link
Thanks Andrei! As a request: could you do a deep dive into what neural PUs are useful for, especially in mobile? I know about photography, but I understand that learning/deep learning is also used for 5G telephony for such tasks as constantly adjusting beam forming. If someone here knows of a good review (overview), I'd appreciate it also. Might help with separating marketing hype from actual requirements.brucethemoose - Wednesday, May 27, 2020 - link
^ this.TBH, I would'nt be suprised if its mostly used for data mining, in which case we're *never* going to find a good overview.
soresu - Wednesday, May 27, 2020 - link
They are used for a lot of things, including image/video processing, face detection, voice recognition, handwriting recognition.Basically anything that requires pattern recognition works well for NN/ML/AI accelerating hardware.
It's more than likely used in the "inside out" tracking for modern standalone VR devices too.
Mind you most of these accelerators work best for running the NN's (also called inference) rather than training them, especially on mobile platforms which are energy constrained.
PeterCollier - Sunday, May 31, 2020 - link
So no practical uses?Image and video processing such as stacked HDR, fake bokeh, all worked fine on the pre-NPU S8 and even on various low end phones like the Moto G6 with sideloaded Google camera app.
Face detection works fine even in digital cameras from 2003.
Handwriting recognition... Maybe on an iPad?
Voice recognition? Why doesn't my S10 ever seen to pick up my voice over music?
Deicidium369 - Wednesday, May 27, 2020 - link
"OK Google" or "Siri ..." for oneValantar - Thursday, May 28, 2020 - link
Aren't 99% of voice assistant tasks still handled by cloud servers?