Russia’s Elbrus 8CB Microarchitecture: 8-core VLIW on TSMC 28nm
by Dr. Ian Cutress on June 1, 2020 8:00 AM EST
All of the world’s major superpowers have a vested interest in building their own custom silicon processors. The vital ingredient to this allows the superpower to wean itself off of US-based processors, guarantee there are no supplemental backdoors, and if needed add their own. As we have seen with China, custom chip designs, x86-based joint ventures, or Arm derivatives seem to be the order of the day. So in comes Russia, with its custom Elbrus VLIW design that seems to have its roots in SPARC.
Russia has been creating processors called Elbrus for a number of years now. For those of us outside Russia, it has mostly been a big question mark as to what is actually under the hood – these chips are built for custom servers and office PCs, often at the direction of the Russian government and its requirements. We have had glimpses of the design, thanks to documents from Russian supercomputing events, however these are a few years old now. If you are not in Russia, you are unlikely to ever get your hands on one at any rate. However, it recently came to our attention of a new programming guide listed online for the latest Elbrus-8CB processor designs.

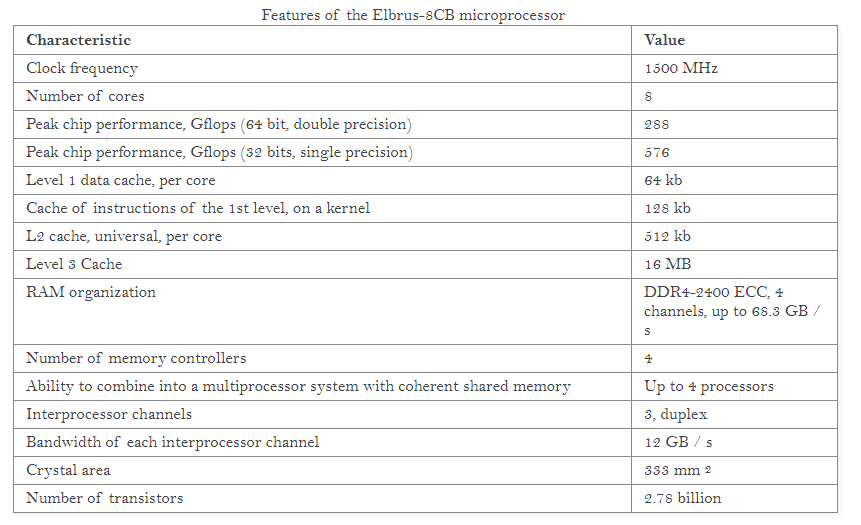
The latest Elbrus-8CB chip, as detailed in the new online programming guide published this week, built on TSMC’s 28nm, is a 333 mm2 design featuring 8 cores at 1.5 GHz. Peak throughput according to the documents states 576 GFLOPs of single precision, with the chip offering four channels of DDR4-2400, good for 68.3 GB/s. The L1 and L2 caches are private, with a 64 kB L1-D cache, a 128 kB L1-I cache, and a 512 kB L2 cache. The L3 cache is shared between the cores, at 2 MB/core for a total of 16 MB. The processor also supports 4-way server multiprocessor combinations, although it does not say on what protocol or what bandwidth.
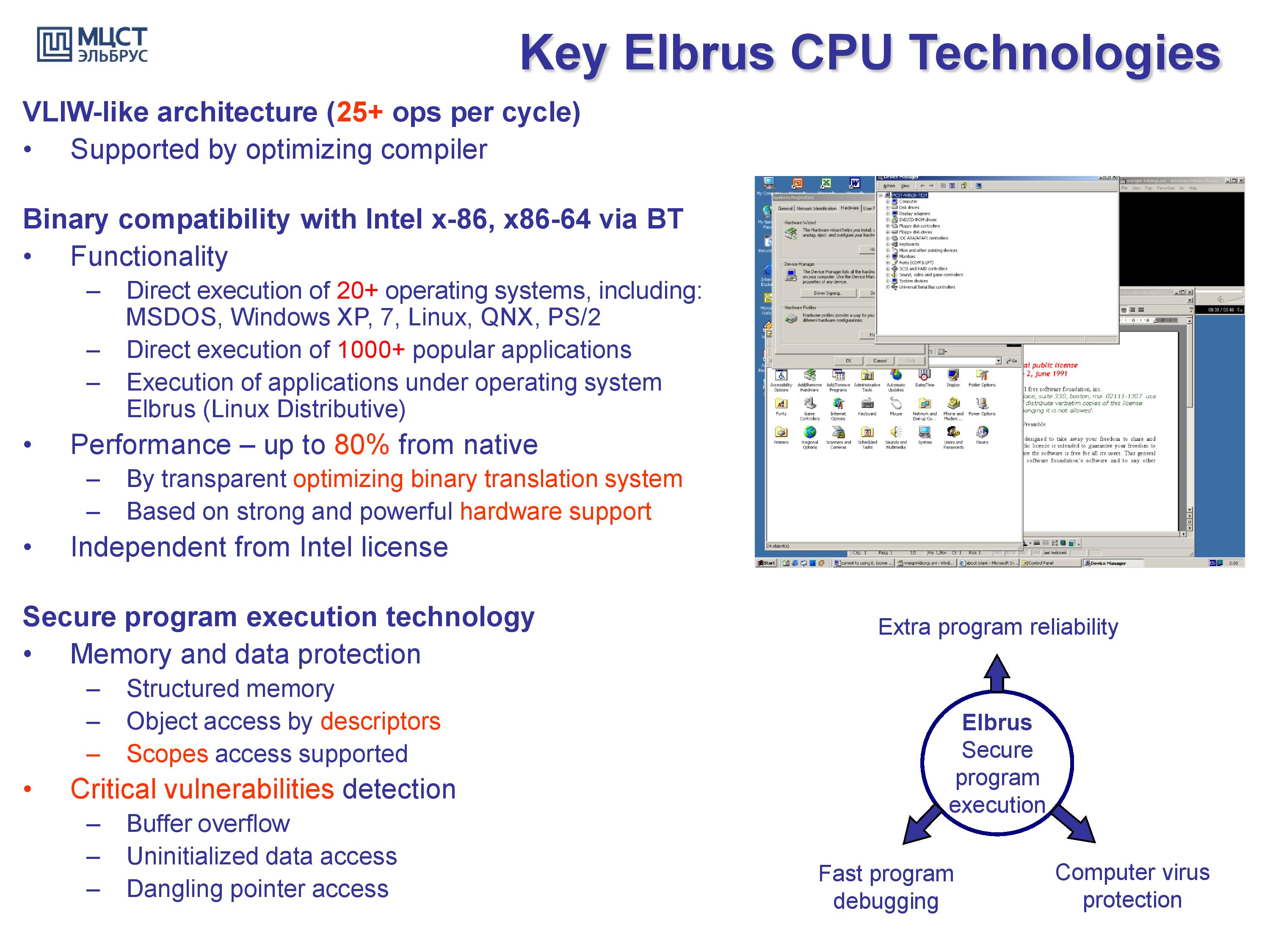
It is a compiler focused design, much like some other complex chips, in that most of the optimizations happen at the compiler level. Based on compiler first designs in the past, that typically does not make for a successful product. Documents from 2015 state that a continuing goal of the Elbrus design is x86 and x86-64 binary translation with only a 20% overhead, allowing full support for x86 code as well as x86 operating systems, including Windows 7 (this may have been updated since 2015).
The core has six execution ports, with many ports being multi-capable. For example, four of the ports can be load ports, and two of the ports can be store ports, but all of them can do integer operations and most can do floating point operations. Four of the ports can do comparison operations, and those four ports can also do vector compute.
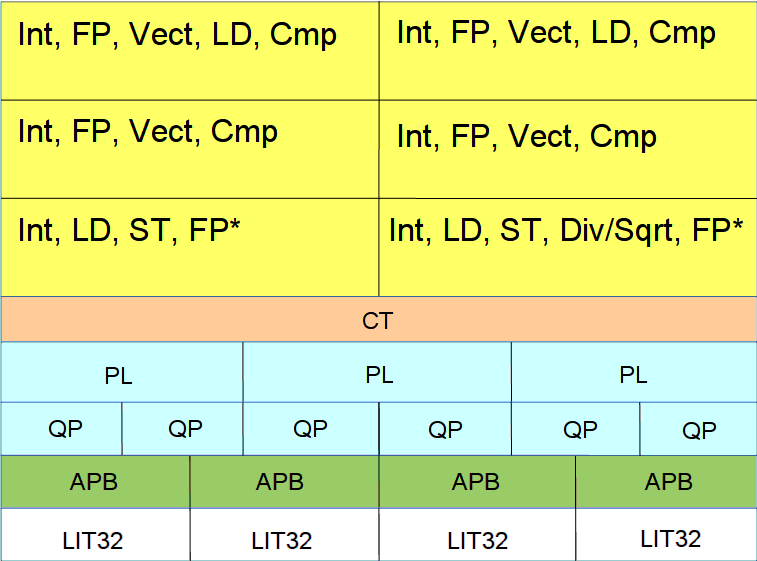
Elbrus 8CB Core
This short news post is not meant to be a complete breakdown of the Elbrus capabilities – we have amusingly joked internally at what frequency a Cortex X1 with x86 translation would match the capabilities of the 8-core Elbrus, however users who want to get to grips with the design can open and read the documentation at the following address:
http://ftp.altlinux.org/pub/people/mike/elbrus/docs/elbrus_prog/html/index.html
The bigger question is going to be how likely any of these state-funded processor development projects are going to succeed at scale. State-funded groups should, theoretically, be the best funded, however even with all the money in the world, engineers are still required to get things done. Even if there ends up being a new super-CPU for a given superpower, there will always be vested interests in an amount of security though obscurity, especially if the hardware is designed specifically to cater to state-secret levels of compute. There's also the added complication of the US government tightening its screws around TSMC and ASML to not accept orders from specific companies - any plans to expand those boundaries could occur, depending how good the products are or how threatened some nations involved feel.
Source: Blu (Twitter)








93 Comments
View All Comments
EntityFX - Monday, June 1, 2020 - link
Hi there, I've tested Elbrus 4C, 1C+, 8C, 8C2 (CB)Results here: https://github.com/EntityFX/anybench/tree/master/r...
And Excel results here: https://github.com/EntityFX/anybench/raw/master/do...
# E2K (Elbrus) compare table and some x86-64, arm
|Test |E8C2 |E8C |E2S |E1C+ |Xeon 6128 |Atom Z8350|Orange Pi PC2|
|---------------------|---------|---------|---------|---------|----------|----------|-------------|
|Dhrystone |8 974,78 |7779,40 |3 548,80 |4 302,53 |25 195,31 |4 677,30 |2 949,12 |
|Whetstone |2 037,62 |1 748,37 |970,80 |1 277,55 |5 850,41 |2 085,24 |980,26 |
|Whetstone MP |16 194,00|13 818,00|2 455,00 |1 312,00 |123 854,00|6 636,00 |3 798,00 |
|Coremark |5 510,19 |4 907,57 |2 364,24 |2 901,49 |28 210,73 |6 893,09 |3 869,72 |
|Coremark MP |39 941,90|35 395,62|9 078,68 |2 848,32 |335 312,61|23 814,68 |14 901,28 |
|Linpack |1 269,79 |1 075,27 |674,68 |814,76 |6 105,95 |1 021,44 |163,44 |
|Scimark 2 (Composite)|472,24 |511,43 |- |379,23 |2 427,42 |509,44 |191,59 |
|MP MFLOPS (32 ops/w) |378976 |139265 |35 782,00|15 676,00|343 556,00|10 665,00 |6 033,00 |
mode_13h - Monday, June 1, 2020 - link
Thanks for this.The last row really confuses me, though. The Xeon 6128 is way faster in everything else, how does the E8C2 manage that win?
EntityFX - Monday, June 1, 2020 - link
void triadplus2(int n, float a, float b, float c, float d, float e, float f, float g, float h, float j, float k, float l, float m, float o, float p, float q, float r, float s, float t, float u, float v, float w, float y, float *x){
int i;
for(i=0; i<n; i++)
x = (x+a)*b-(x+c)*d+(x+e)*f-(x+g)*h+(x+j)*k-(x+l)*m+(x+o)*p-(x+q)*r+(x+s)*t-(x+u)*v+(x+w)*y;
}
Compiles good for the e2k (VLIW).
mode_13h - Monday, June 1, 2020 - link
Thanks.Which compiler? ...or is it proprietary?
Do you have to do any profile-driven recompilation to get good performance on that?
Do you use an loop-unrolling or software-pipelining options or #pragrmas?
mshigorin - Tuesday, June 2, 2020 - link
lcc is proprietary unfortunately, and will likely stay this way -- just as icc :-(That's a major hurdle but I hear that modern gcc backend effort is also underway (but rather -O0 at the moment or so).
There's PGO (and LTO) already but I'd have to ask my fellow colleague to provide meaningful feedback on those (I'm a chemist after all, and he's a nuclear physics guy ;-).
See also these two chapters:
http://ftp.altlinux.org/pub/people/mike/elbrus/doc... (generic)
http://ftp.altlinux.org/pub/people/mike/elbrus/doc... (e2k)
EntityFX - Monday, June 1, 2020 - link
The e2k ASM example is here: https://github.com/EntityFX/anybench/blob/master/a...Wilco1 - Monday, June 1, 2020 - link
Woah, that's some serious code bloat there!The issue is that the compiler options don't enable fma, avx, avx2 or avx512 if available.
My 3700X gets 346372 with the prebuilt binary but with -mcpu=native -mavx2 -mfma I get 865520.
So assume all of these results are inaccurate.
Wilco1 - Monday, June 1, 2020 - link
The 32-bit Arm results are similar, while -mfpu=neon is used, they don't use -Ofast which you need to get FP vectorization. So the Arm results are way off too. Also, since everything is AArch64 today, why even use ancient 32-bit Arm?mode_13h - Monday, June 1, 2020 - link
The triadplus2() seems only about 2k lines, including brackets, labels, and blank lines. For highly-optimized code, I'd say it's not bad.The whole program code is only about 12k lines, if you include main(). And it clearly includes some timing code, results checking and file I/O.
Wilco1 - Tuesday, June 2, 2020 - link
On AArch64 the fully optimized version is just over 200 lines with the vectorized inner loop taking less than 30 lines: https://godbolt.org/z/Jjo2nj