Intel Xe-HP Graphics: Early Samples Offer 42+ TFLOPs of FP32 Performance
by Dr. Ian Cutress on August 21, 2020 11:00 AM EST- Posted in
- GPUs
- Intel
- Enterprise
- Intel Arch Day 2020
- XeHP

One of the promises that Intel has made with its new Xe GPU family is that in its various forms it will cater to uses ranging from integrated graphics all the way up to the high performance compute models needed for super-dense supercomputers. This means support for the types of calculations involved in simple graphics, complex graphics, ray tracing, AI inference, AI training, and the compute that goes into molecular modelling, oil-and-gas, nuclear reactors, rockets, nuclear rockets, and all the other big questions where more compute offers more capabilities. Sitting near the top of Intel’s offerings is the Xe-HP architecture, designed to offer high performance GPUs for standard server and enterprise deployments.
Over the past couple of weeks Intel has offered some of the first technical details of Xe-HP, following Raja Koduri showing it off across his social media profiles. We know that it is designed to be a modular architecture, with different chiplets connected together using Intel’s Embedded Multi-Die Interconnect Bridge technology. We also know, due to disclosures made at Intel’s Architecture Day, that it is set to be built on Intel’s 10nm Enhanced SuperFin (10ESF, formerly 10++, formerly 10+++) manufacturing process, which we believe to be a late 2021 process. Raja Koduri promised during the Architecture Day presentation that Xe-HP (and Xe-HPG) will be available in 2021.

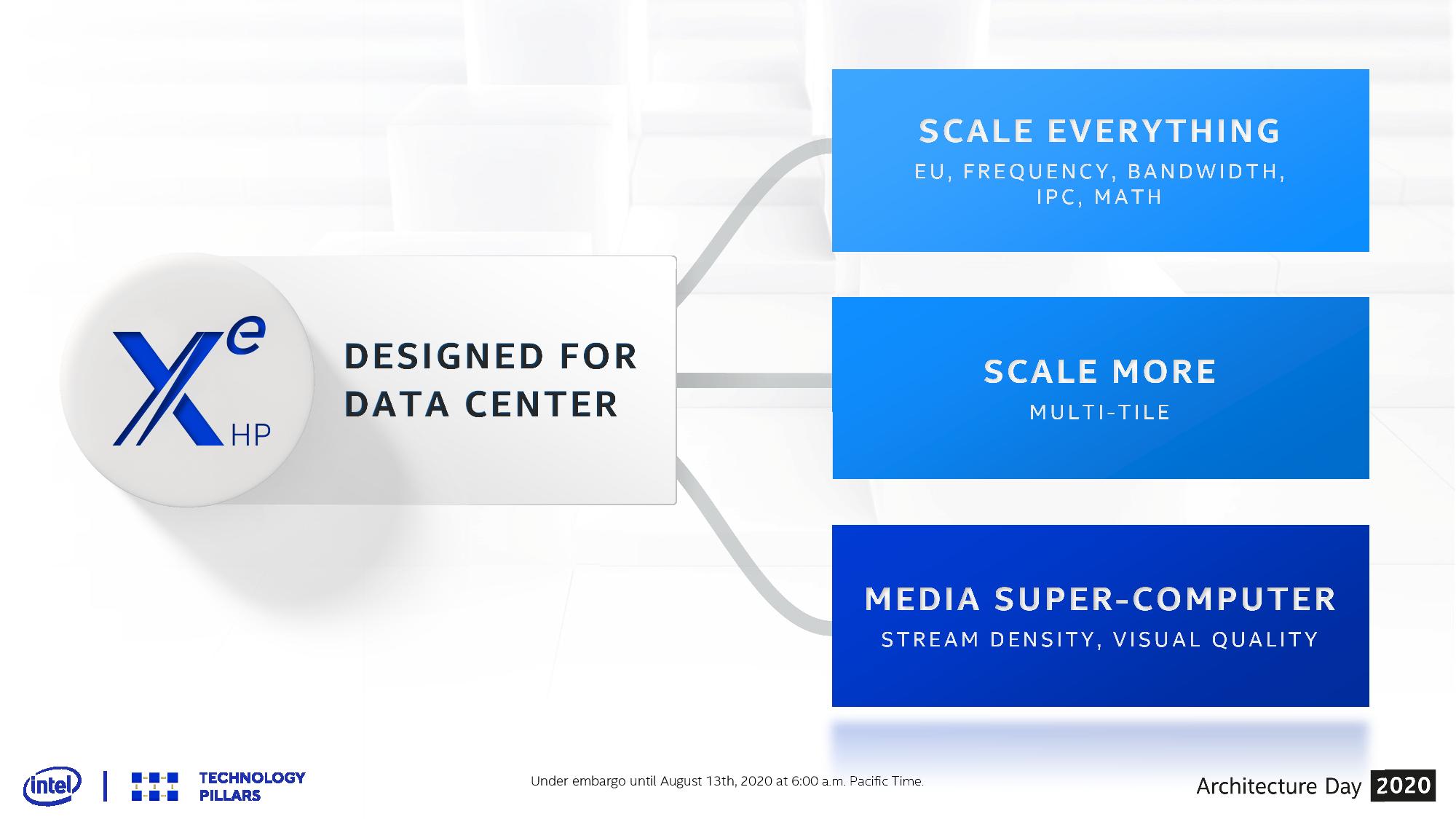
Intel explained that the modular Xe-HP design will scale from one to four tiles, and the concept of Xe-HP was to ‘scale everything’, such as execution units, frequency, bandwidth, IPC, and math capabilities. We assume that each tile will have direct access to some on-chip memory as well – truly scaling up every aspect of a chip – although how the chip's HBM2E is allocated hasn't been confirmed. The point of the product is that it is designed for the data-center, so there needs to be a mix of media compute as well as raw compute, covering all sorts of uses cases.

As part of the demonstration during Architecture Day, Intel also showcased that they’ve been running some benchmarks on the early silicon in the labs. By early silicon, we mean that these aren’t running at the final frequencies, this isn’t final firmware, and the software stack still has a way to go, so undoubtedly there are optimizations at every level.

First, Intel showed that a single tile of Xe-HP can not only transcode one 4K60 video in real time, but ten. In the demonstration they had the FFmpeg output, showing that the demo was converting each video from 5332 kb/s overall down to 3000 kb/s average (6000 kb/s max).
For compute, Intel offered the following performance numbers, given as peak GFLOPs of FP32 math using the OpenCL-based CLPeak benchmark.
- One Tile: 10588 GFLOPs (10.6 TF) of FP32
- Two Tile: 21161 GFLOPs (21.2 TF) of FP32 (1.999x)
- Four Tile: 42277 GFLOPs (42.3 TF) of FP32 (3.993x)
We also get some additional information from the video of Xe-HP. The tests were done on Linux, and actually all done on a version of the quad-tile chip, but made to run in 1T/2T/4T modes. This is why when looking at the video we can see all three versions are running at 1300 MHz. The string used for the chip is ‘XeHP HD Graphics NEO’ as well.
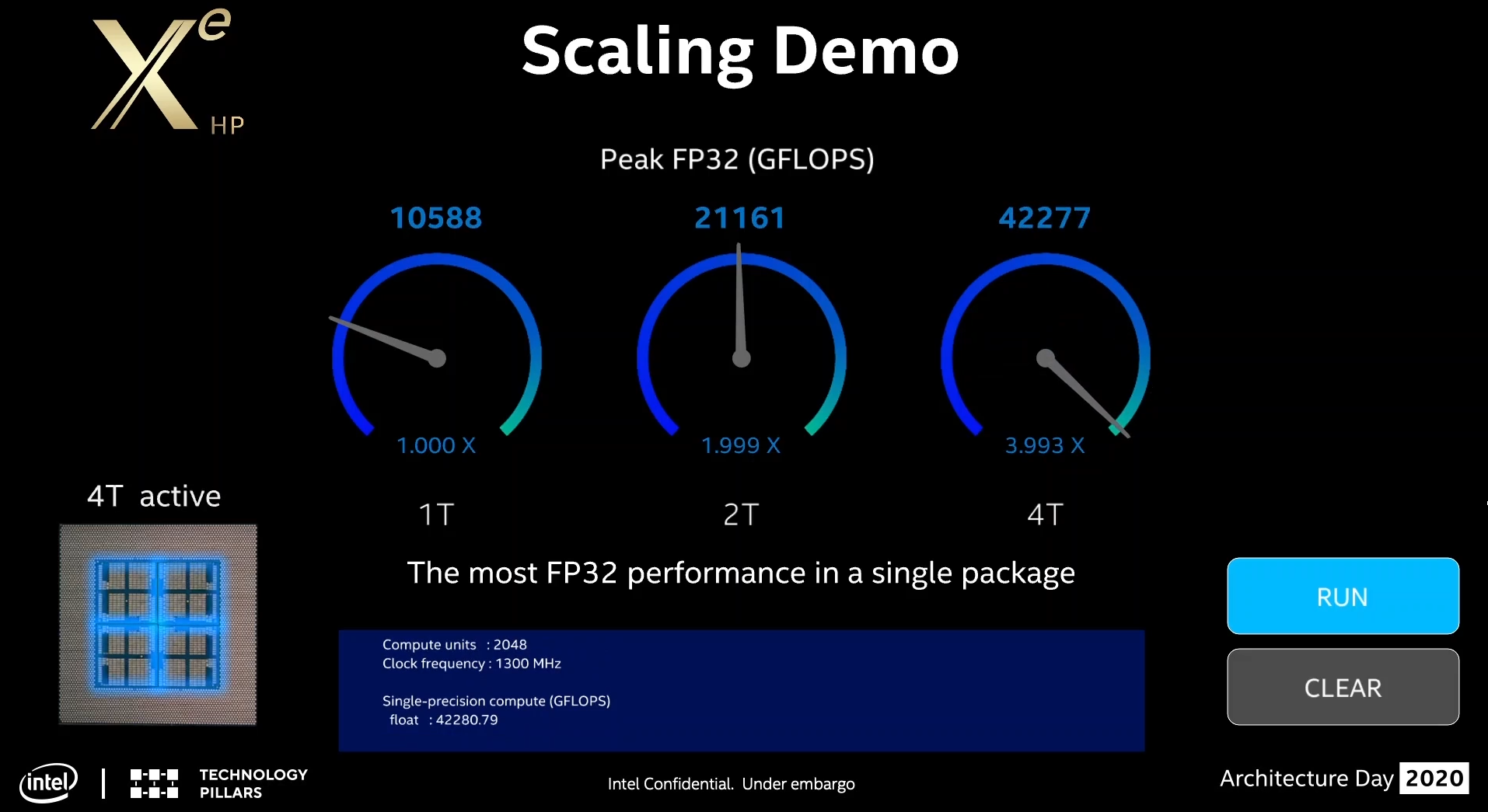
The video also shows that a single tile has 512 ‘compute units’, while the dual tile has 1024 compute units and the quad-tile has 2048 compute units. And while Intel hasn't officially claried what "compute units" mean in this context, the performance figures all but confirm that it's counting Intel's Execution Units. Based on the given GFLOPs, the stated clock speed, and the Xe architecture's 8 pipes per Execution unit with dual FMAs, Intel's performance figures map to 512/1024/2048 EUs respectively. That would mean that each one would have:
- One Tile: 512 EUs = 4096 ALUs (+ 1024 Extended Math ALUs)
- Two Tile: 1024 EUs = 8196 ALUs (+ 2048 Extended Math ALUs)
- Four Tiles: 2048 EUs = 16384 ALUs (+ 4096 Extended Math ALUs)
This is assuming that the Execution Unit structure of 8+2 from Xe-LP remains. We know that HP will support new XMX instructions for matrix math, as well as AI-related quantization levels and FP64 too. Which Intel's Hot Chips presentation has confirmed will be implemented within the EUs as additional physical blocks.



There was also a shot of the rear of an Xe-HP die, which Raja has shown off during his Hot Chips keynote as well. We can play a game of count the pins.

Intel Xe-HP 4-Tile Rear
Intel believes it is achieving near linear scaling in compute performance across its multi-tile strategy – at least up to 4T using CLPeak, a benchmark designed to measure a GPU's maximum compute throughput. There’s nothing here to say about tile-to-tile bandwidth scaling, or if this multi-tiling strategy and NUMA arrangement of tiles has knock-on effects for memory-limited or sparse math – Intel’s goal was simply to show that the hardware is running and what kind of peak compute performance it can offer. There’s also no word on power consumption either, or cost, however in the presentation Intel says that the goal here is to offer the equivalent of a rack-scale transcoding system in a single chip with best-in-class TCO, winning on performance-per-watt-per-dollar.
Xe-HP is set to be available in 2021 for the Enterprise market.
Related Reading
- The Intel Xe-LP GPU Architecture Deep Dive: Building Up The Next Generation
- Intel’s Xe-HPG GPU Unveiled: Built for Enthusiast Gamers, Built at a Third-Party Fab
- Intel Xe-HPC GPU Status Update: 4 Process Nodes Make 1 Accelerator
- Spotted At Hot Chips: Quad Tile Intel Xe-HP GPU
- Hot Chips 2020 Live Blog: Intel's Xe GPU Architecture (5:30pm PT)








41 Comments
View All Comments
MonkeyPaw - Friday, August 21, 2020 - link
I wonder how this compares to the Afterburner Accelerator card? Apple claims that card can handle 23 4K streams at once.SirDragonClaw - Saturday, August 22, 2020 - link
Those things are not comparable, also the Accelerator card is just a cheap fpga.Santoval - Friday, August 21, 2020 - link
Since these are early engineering samples running at 1300 MHz we can assume that gaming graphics cards will contain either a single high clocked tile or two lower clocked tiles. If Intel can achieve a peak/turbo clock of 1900 - 1950 MHz at a reasonable TDP with their single tile variant (for a peak FP32 performance of 15.5 to 16 TFLOPs) they might not need a dual tile gaming variant to compete with AMD and Nvidia*, at least for the first generation of cards.*except the cutting edge xx80 Ti / xx90 card from Nvidia.
Ryan Smith - Friday, August 21, 2020 - link
Xe-HPG will be a monolithic chip. Intel has already confirmed that it won't use any advanced packaging techniques (e.g. EMIB).Spunjji - Monday, August 24, 2020 - link
I'm expecting Xe HPG to take up roughly the role in the GPU market that RDNA played for this generation - not remarkable in any respect, but performant enough at the right price. I'm sincerely hopeful that they'll be at least moderately competitive just to end this absurd price inflation that Nvidia have been pushing in the mid-range.SethNW - Saturday, August 22, 2020 - link
Yeah, except no... :-D nVidia and AMD are preparing next gen. Plus Teraflops are meaningless for gaming, because it really doesn't scale and you can't really compare it between different architectures. Plus AMD and nVidia have decades of gaming optimizations behind them, I ntel doesn'tSethNW - Saturday, August 22, 2020 - link
I hit submit by mistake, don't see edit option, sorry for multi post.Anyway, I just don't see them coming on to for gaming. Or coming on top for bang for the buck. Maybe work wise, they will do better though.
Spunjji - Monday, August 24, 2020 - link
Bang for buck is the easiest area to compete, because if you're desperate enough for market share then you can just sell at whatever price your performance enables. The performance per area / performance per watt side of the equation are the hard parts, as they dictate your profit margins and your performance ceiling.To summarise: PP$ is the most likely place for Intel to actually be competitive. Based on the projections for Xe from Tiger Lake, they're almost certainly not going to be particularly competitive on any other front.
JayNor - Monday, August 24, 2020 - link
Tiger Lake will have support for lpddr5, which could give the GPU a further bump.Also, the recent slides indicate the new Xe-DG1 10nm SuperFin process enables clocking up to 1.7 GHz, which is higher than I've seen leaked in early benchmarks.
Spunjji - Friday, August 28, 2020 - link
Both of those "further bumps" are already baked into their performance projections. The first batch of devices won't have LPDDR5, which means they'll be running at a deficit compared with Intel's projections.Basically they're playing fast-and-loose with their marketing and selling Jam Tomorrow, as per usual.