Apple Announces The Apple Silicon M1: Ditching x86 - What to Expect, Based on A14
by Andrei Frumusanu on November 10, 2020 3:00 PM EST- Posted in
- Apple
- Apple A14
- Apple Silicon
- Apple M1

Today, Apple has unveiled their brand-new MacBook line-up. This isn’t an ordinary release – if anything, the move that Apple is making today is something that hasn’t happened in 15 years: The start of a CPU architecture transition across their whole consumer Mac line-up.
Thanks to the company’s vertical integration across hardware and software, this is a monumental change that nobody but Apple can so swiftly usher in. The last time Apple ventured into such an undertaking in 2006, the company had ditched IBM’s PowerPC ISA and processors in favor of Intel x86 designs. Today, Intel is being ditched in favor of the company’s own in-house processors and CPU microarchitectures, built upon the Arm ISA.
The new processor is called the Apple M1, the company’s first SoC designed with Macs in mind. With four large performance cores, four efficiency cores, and an 8-GPU core GPU, it features 16 billion transistors on a 5nm process node. Apple’s is starting a new SoC naming scheme for this new family of processors, but at least on paper it looks a lot like an A14X.
Today’s event contained a ton of new official announcements, but also was lacking (in typical Apple fashion) in detail. Today, we’re going to be dissecting the new Apple M1 news, as well as doing a microarchitectural deep dive based on the already-released Apple A14 SoC.
The Apple M1 SoC: An A14X for Macs
The new Apple M1 is really the start of a new major journey for Apple. During Apple’s presentation the company didn’t really divulge much in the way of details for the design, however there was one slide that told us a lot about the chip’s packaging and architecture:

This packaging style with DRAM embedded within the organic packaging isn't new for Apple; they've been using it since the A12. However it's something that's only sparingly used. When it comes to higher-end chips, Apple likes to use this kind of packaging instead of your usual smartphone POP (package on package) because these chips are designed with higher TDPs in mind. So keeping the DRAM off to the side of the compute die rather than on top of it helps to ensure that these chips can still be efficiently cooled.
What this also means is that we’re almost certainly looking at a 128-bit DRAM bus on the new chip, much like that of previous generation A-X chips.
On the very same slide, Apple also seems to have used an actual die shot of the new M1 chip. It perfectly matches Apple’s described characteristics of the chip, and it looks looks like a real photograph of the die. Cue what's probably the quickest die annotation I’ve ever made:
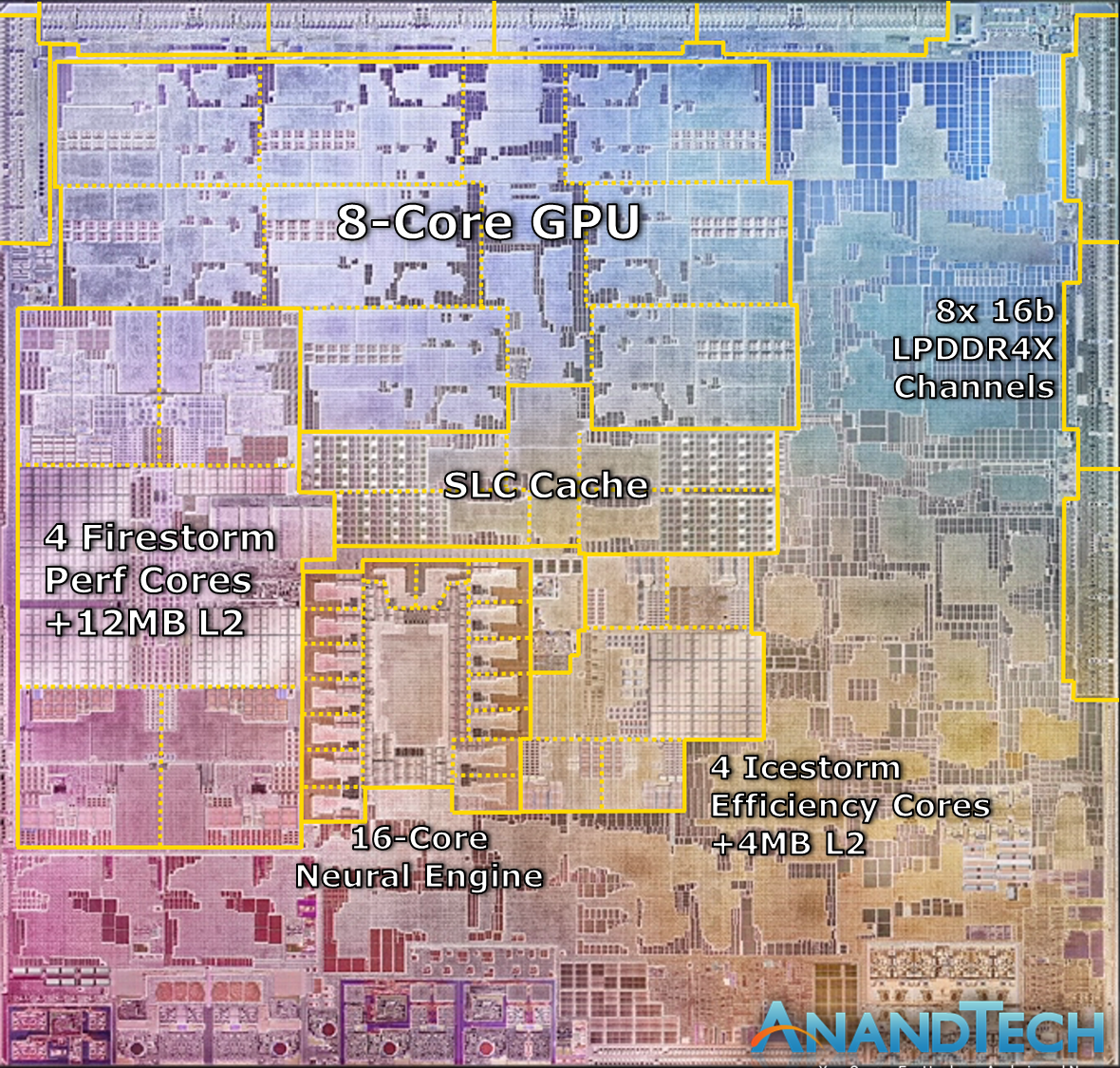
We can see the M1’s four Firestorm high-performance CPU cores on the left side. Notice the large amount of cache – the 12MB cache was one of the surprise reveals of the event, as the A14 still only featured 8MB of L2 cache. The new cache here looks to be portioned into 3 larger blocks, which makes sense given Apple’s transition from 8MB to 12MB for this new configuration, it is after all now being used by 4 cores instead of 2.
Meanwhile the 4 Icestorm efficiency cores are found near the center of the SoC, above which we find the SoC’s system level cache, which is shared across all IP blocks.
Finally, the 8-core GPU takes up a significant amount of die space and is found in the upper part of this die shot.
What’s most interesting about the M1 here is how it compares to other CPU designs by Intel and AMD. All the aforementioned blocks still only cover up part of the whole die, with a significant amount of auxiliary IP. Apple made mention that the M1 is a true SoC, including the functionality of what previously was several discrete chips inside of Mac laptops, such as I/O controllers and Apple's SSD and security controllers.


The new CPU core is what Apple claims to be the world’s fastest. This is going to be a centre-point of today’s article as we dive deeper into the microarchitecture of the Firestorm cores, as well look at the performance figures of the very similar Apple A14 SoC.
With its additional cache, we expect the Firestorm cores used in the M1 to be even faster than what we’re going to be dissecting today with the A14, so Apple’s claim of having the fastest CPU core in the world seems extremely plausible.

The whole SoC features a massive 16 billion transistors, which is 35% more than the A14 inside of the newest iPhones. If Apple was able to keep the transistor density between the two chips similar, we should expect a die size of around 120mm². This would be considerably smaller than past generation of Intel chips inside of Apple's MacBooks.
Road To Arm: Second Verse, Same As The First
Section by Ryan Smith
The fact that Apple can even pull off a major architectural transition so seamlessly is a small miracle, and one that Apple has quite a bit of experience in accomplishing. After all, this is not Apple’s first-time switching CPU architectures for their Mac computers.
The long-time PowerPC company came to a crossroads around the middle of the 2000s when the Apple-IBM-Motorola (AIM) alliance, responsible for PowerPC development, increasingly struggled with further chip development. IBM’s PowerPC 970 (G5) chip put up respectable performance numbers in desktops, but its power consumption was significant. This left the chip non-viable for use in the growing laptop segment, where Apple was still using Motorola’s PowerPC 7400 series (G4) chips, which did have better power consumption, but not the performance needed to rival what Intel would eventually achieve with its Core series of processors.
And thus, Apple played a card that they held in reserve: Project Marklar. Leveraging the flexibility of the Mac OS X and its underlying Darwin kernel, which like other Unixes is designed to be portable, Apple had been maintaining an x86 version of Mac OS X. Though largely considered to initially have been an exercise in good coding practices – making sure Apple was writing OS code that wasn’t unnecessarily bound to PowerPC and its big-endian memory model – Marklar became Apple’s exit strategy from a stagnating PowerPC ecosystem. The company would switch to x86 processors – specifically, Intel’s x86 processors – upending its software ecosystem, but also opening the door to much better performance and new customer opportunities.
The switch to x86 was by all metrics a big win for Apple. Intel’s processors delivered better performance-per-watt than the PowerPC processors that Apple left behind, and especially once Intel launched the Core 2 (Conroe) series of processors in late 2006, Intel firmly established itself as the dominant force for PC processors. This ultimately setup Apple’s trajectory over the coming years, allowing them to become a laptop-focused company with proto-ultrabooks (MacBook Air) and their incredibly popular MacBook Pros. Similarly, x86 brought with it Windows compatibility, introducing the ability to directly boot Windows, or alternatively run it in a very low overhead virtual machine.

The cost of this transition, however, came on the software side of matters. Developers would need to start using Apple’s newest toolchains to produce universal binaries that could work on PPC and x86 Macs – and not all of Apple’s previous APIs would make the jump to x86. Developers of course made the jump, but it was a transition without a true precedent.
Bridging the gap, at least for a bit, was Rosetta, Apple’s PowerPC translation layer for x86. Rosetta would allow most PPC Mac OS X applications to run on the x86 Macs, and though performance was a bit hit-and-miss (PPC on x86 isn’t the easiest thing), the higher performance of the Intel CPUs helped to carry things for most non-intensive applications. Ultimately Rosetta was a band-aid for Apple, and one Apple ripped off relatively quickly; Apple already dropped Rosetta by the time of Mac OS X 10.7 (Lion) in 2011. So even with Rosetta, Apple made it clear to developers that they expected them to update their applications for x86 if they wanted to keeping selling them and to keep users happy.
Ultimately, the PowerPC to x86 transitions set the tone for the modern, agile Apple. Since then, Apple has created a whole development philosophy around going fast and changing things as they see fit, with only limited regard to backwards compatibility. This has given users and developers few options but to enjoy the ride and keep up with Apple’s development trends. But it has also given Apple the ability to introduce new technologies early, and if necessary, break old applications so that new features aren’t held back by backwards compatibility woes.
All of this has happened before, and it will all happen again starting next week, when Apple launches their first Apple M1-based Macs. Universal binaries are back, Rosetta is back, and Apple’s push to developers to get their applications up and running on Arm is in full force. The PPC to x86 transition created the template for Apple for an ISA change, and following that successful transition, they are going to do it all over again over the next few years as Apple becomes their own chip supplier.
A Microarchitectural Deep Dive & Benchmarks
In the following page we’ll be investigating the A14’s Firestorm cores which will be used in the M1 as well, and also do some extensive benchmarking on the iPhone chip, setting the stage as the minimum of what to expect from the M1:








644 Comments
View All Comments
Spunjji - Friday, November 13, 2020 - link
@vais - Perhaps I should have clarified that my comment was indeed regarding the single-core results? But I sort-of assumed anybody reading it would have *read the article* and thus was aware of that context. 🤦♂️We won't get multi-core data until later, for sure, but your attempt to pretend that we therefore have *no idea* what's coming is mere sophistry. I'd advise you adjust your expectations accordingly, as you've already indicated a level of certainty in the outcome (mY i5 WiLl BeAt It) that you are simultaneously arguing nobody else is entitled to. That cognitive dissonance has been noted.
vais - Friday, November 13, 2020 - link
I had missed Graviton, thanks for the link!It seems very interesting and is a much more fair comparison as all 3 CPUs have similar TDPs. AMD are still some way from Zen3 based Epyc CPUs, but even if they have better performance than Graviton 2, they still could be far behind in the performance/$.
As for M1 all I'm saying is that comparing it to other laptop CPUs with similar TDP (of course higher too since it is more efficient) is one thing. But comparing it to the latest desktop CPUs is another story and reality might not reflect the synthetic benchmarks that well.
If say M2 was positioned for the Mac Pro at 50-60-70W TDP, then comparing it to 5950X would make sense and it really could have better performance - that is all.
misan - Thursday, November 12, 2020 - link
Dedicated silicon for compiling code? Or for doing scientific computation? Or for traversing linked lists? SPEC benchmark suite is extensively documented and the individual benchmark behavior is understood. This is all plain C code that targets the CPU.I understand that it might be hard to accept it, but the simple fact is that Apple has made a substantially better chip. They can do much more work per clock than anything else on general-purpose code, which allows them to be fast without needing very high clocks.
Spunjji - Thursday, November 12, 2020 - link
@Coldfriction - the "dedicated silicon" you refer to played no part in any of the tests in this article.Coldfriction - Thursday, November 12, 2020 - link
You mean all of the memory on package with the CPU doesn't make a difference? That's the "dedicated silicon" sort of thing I'm talking about. How fast was the SNES CPU was 3.58 Mhz. It took a massively more powerful intel, amd, or cyrix chip to do what the SNES could do. MASSIVELY more powerful. What Apple is doing here is making a console PC. The performance isn't all derived from their CPU cores independent of the rest of the system. Everything is tightly integrated with no flexibility on the users end. The Cell architecture boasted similar stuff back in the day. Yes, Apple has a strong ARM CPU here, but it's the tight integration that makes it so strong, not the core itself. There's a reason the memory is in the package and non-upgradable. The functions tested in this article may drastically favor the cache system of the M1, but once you go outside of that, you lose a lot.It's ALWAYS been the case that custom built systems have outperformed generic computing devices.
This article doesn't test very many things. It certainly doesn't test demanding workloads that saturate much of the systems capabilities.
I owned Amigas back in the day. I had access to a variety of computing devices. The IBM compatible PCs were the ugliest slowest machines around, but they succeeded where everyone else's prettier systems failed. Why? Compatibility and ability to swap the software and hardware from different vendors around. They became cheap and maintained by a variety of people due to that. The Apple Lisa I had as a kid blew away my first 386, but then Apple still nearly went bankrupt a decade later.
Custom build design is great for a very short term solution, but Apple's leash of leather is being swapped out for a leash of steel chain with this move.
daveedvdv - Thursday, November 12, 2020 - link
> You mean all of the memory on package with the CPU doesn't make a difference? That's the "dedicated silicon" sort of thing I'm talking about.That's quite the stretch. What exactly is that memory dedicated to? It's not like other manufacturers cannot package main memory with their chips either. It sounds like you're grasping at straws because you don't like the news.
Spunjji - Friday, November 13, 2020 - link
@daveedvdv - I think you nailed it there. There's a lot of that going on in these comments.Hell, I don't *like* the news. I'm a Windows guy and I don't buy Apple devices; if it turns out they'll have exclusive access to some of the best-performing mobile silicon on the planet it'll be kind of a bitch. But it is what it is.
daveedvdv - Friday, November 13, 2020 - link
@Spunjji:Thanks. And, FWIW, while I'm an Apple eco-system person, I'm under no illusion that others will be able to match the achievement relatively soon. There are lots of players in the ARM ISA world, and they each have some serious talent working for them.
Spunjji - Friday, November 13, 2020 - link
@coldfriction - On-package memory isn't "custom silicon". Either you're talking about "dedicated silicon" - i.e. the accelerators that Apple's chip has and others don't - or you're talking about shared caches and memory interfaces that every other chip out there has / can have.The SNES CPU thing is a weird flex - everybody knows that emulation requires more resources than the original system, but the SNES CPU wasn't remarkable in any way. A better example would have been the Amiga's video controllers, but then you'd run straight into what I pointed out, which is that such a comparison is irrelevant to what was actually tested in this article - the CPU architecture (including caches and, in some tests, memory performance).
You're right that it doesn't test demanding workloads or the entire system - that wasn't the remit of the article. We'll see that stuff when they have actual M1-based systems to test; running those tests on A14 in an iPhone would be worse than useless for estimating M1 performance.
magreen - Sunday, November 15, 2020 - link
Keep it up, Spunjji! Thanks for injecting rational discourse into these comments. I have no horse in this race, but I recognize measured statements and rational arguments based on evidence when I see them.