Arm Announces Armv9 Architecture: SVE2, Security, and the Next Decade
by Andrei Frumusanu on March 30, 2021 2:00 PM ESTIntroducing the Confidential Compute Architecture
Over the last few years, we’ve seen security, and security breaches of hardware be at the forefront of news, with many vulnerabilities such as Spectre, Meltdown, and all of their sibling side-channel attacks showcasing that there’s a fundamental need for a re-think of how to approach security. One way Arm wants to address this overarching issue is to re-architect how secure applications work with the introduction of the Arm Confidential Compute Architecture.
Before continuing, I want to warn that today’s disclosures are merely high-level explanations of how the new CCA operates, with Arm saying more details on how exactly the new security mechanism works will be unveiled later this summer.
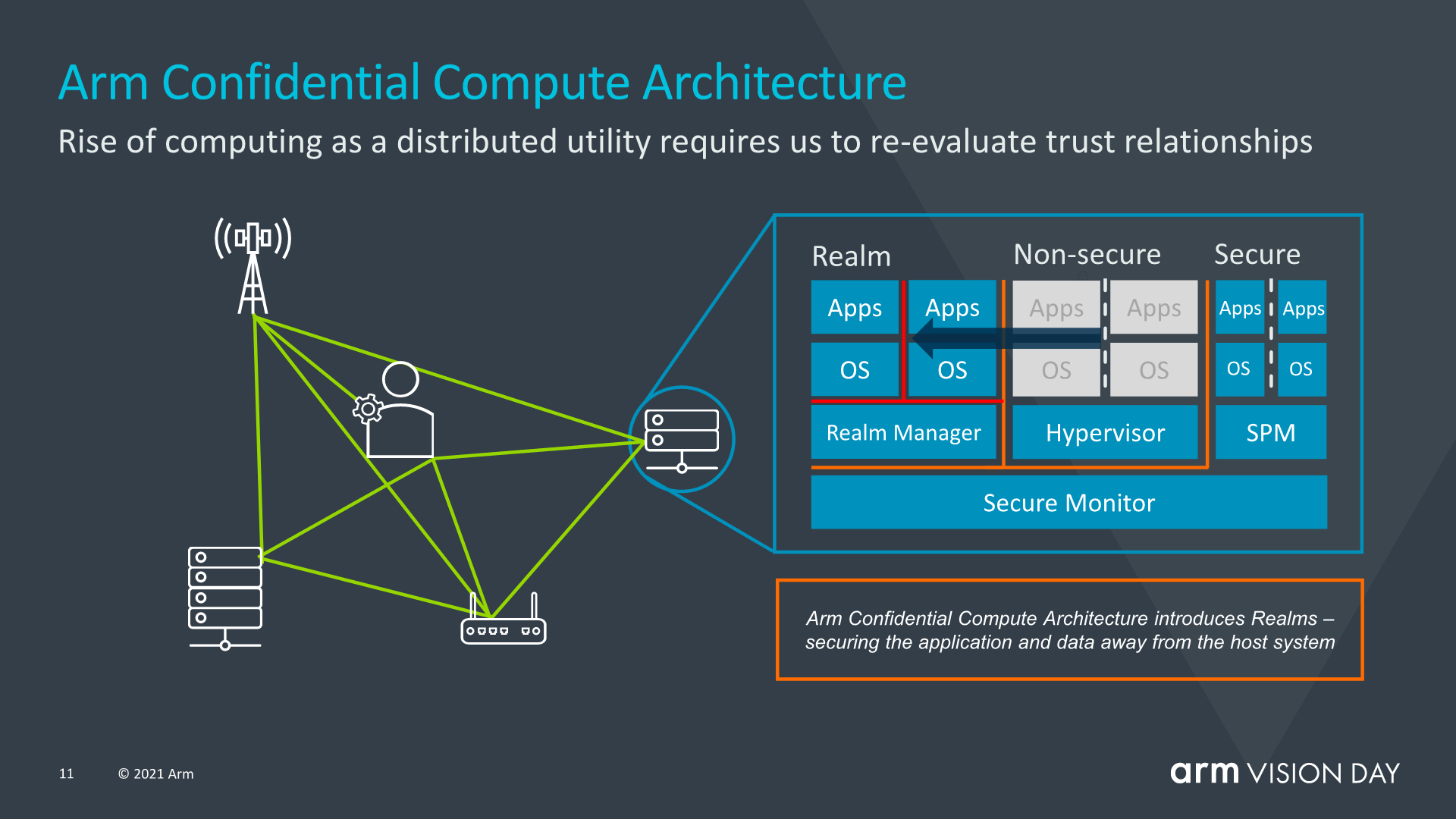
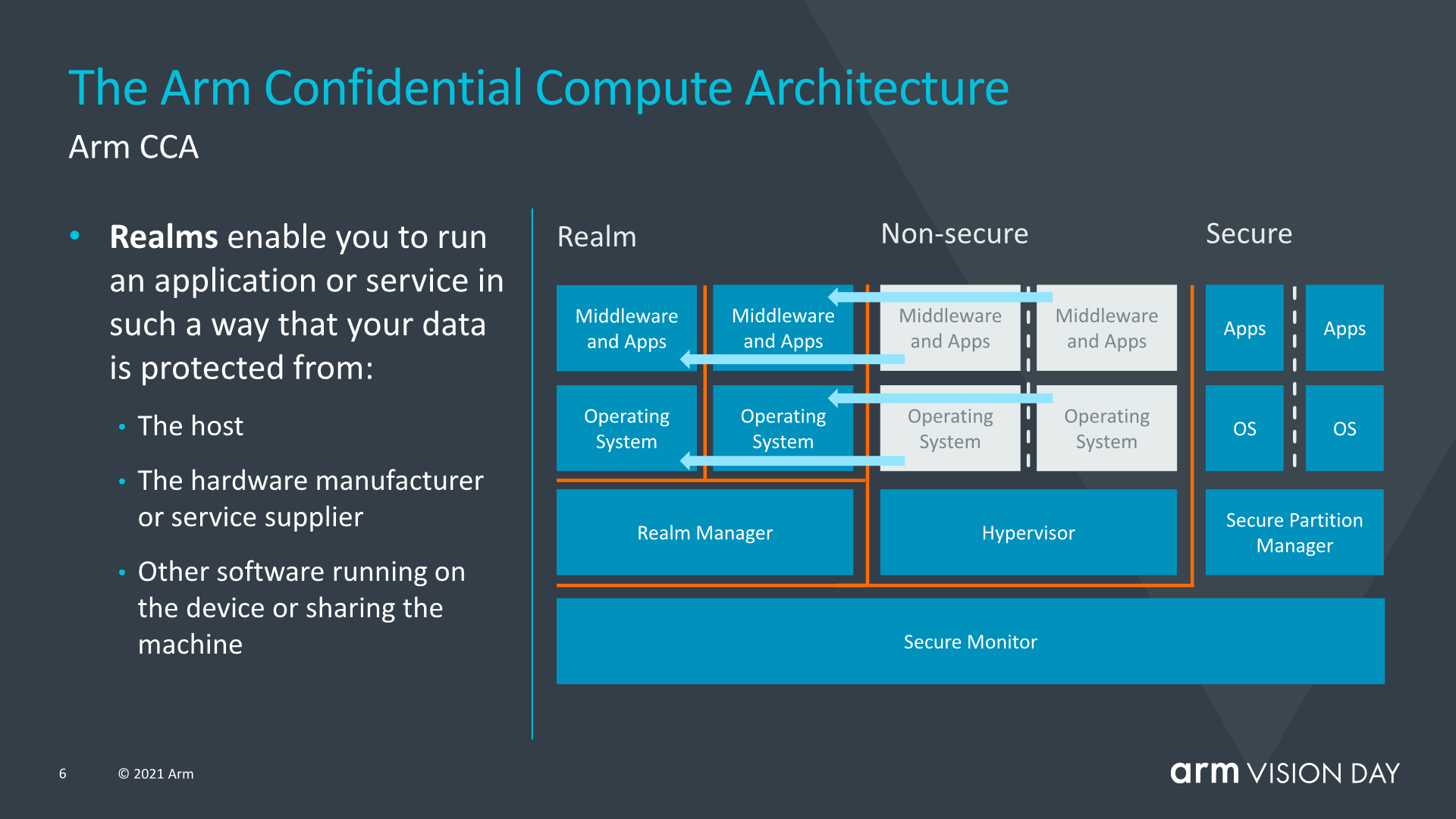
The goal of the CCA is to more from the current software stack situation where applications which are run on a device have to inherently trust the operating system and the hypervisor they are running on. The traditional model of security is built around the fact that the more privileged tiers of software are allowed to and are able to see into the execution of lower tiers, which can be an issue when the OS or the hypervisor is compromised in any way.
CCA introduces a new concept of dynamically creates “realms”, which can be viewed as secured containerised execution environments that are completely opaque to the OS or hypervisor. The hypervisor would still exist, but be solely responsible for scheduling and resource allocation. The realms instead, would be managed by a new entity called the “realm manager”, which is supposed to be a new piece of code roughly 1/10th the size of a hypervisor.
Applications within a realm would be able to “attest” a realm manager in order to determine that it can be trusted, which isn’t possible with say a traditional hypervisor.
Arm didn’t go into more depth of what exactly creates this separation between the realms and the non-secure world of the OS and hypervisors, but it did sound like hardware backed address spaces which cannot interact with each other.
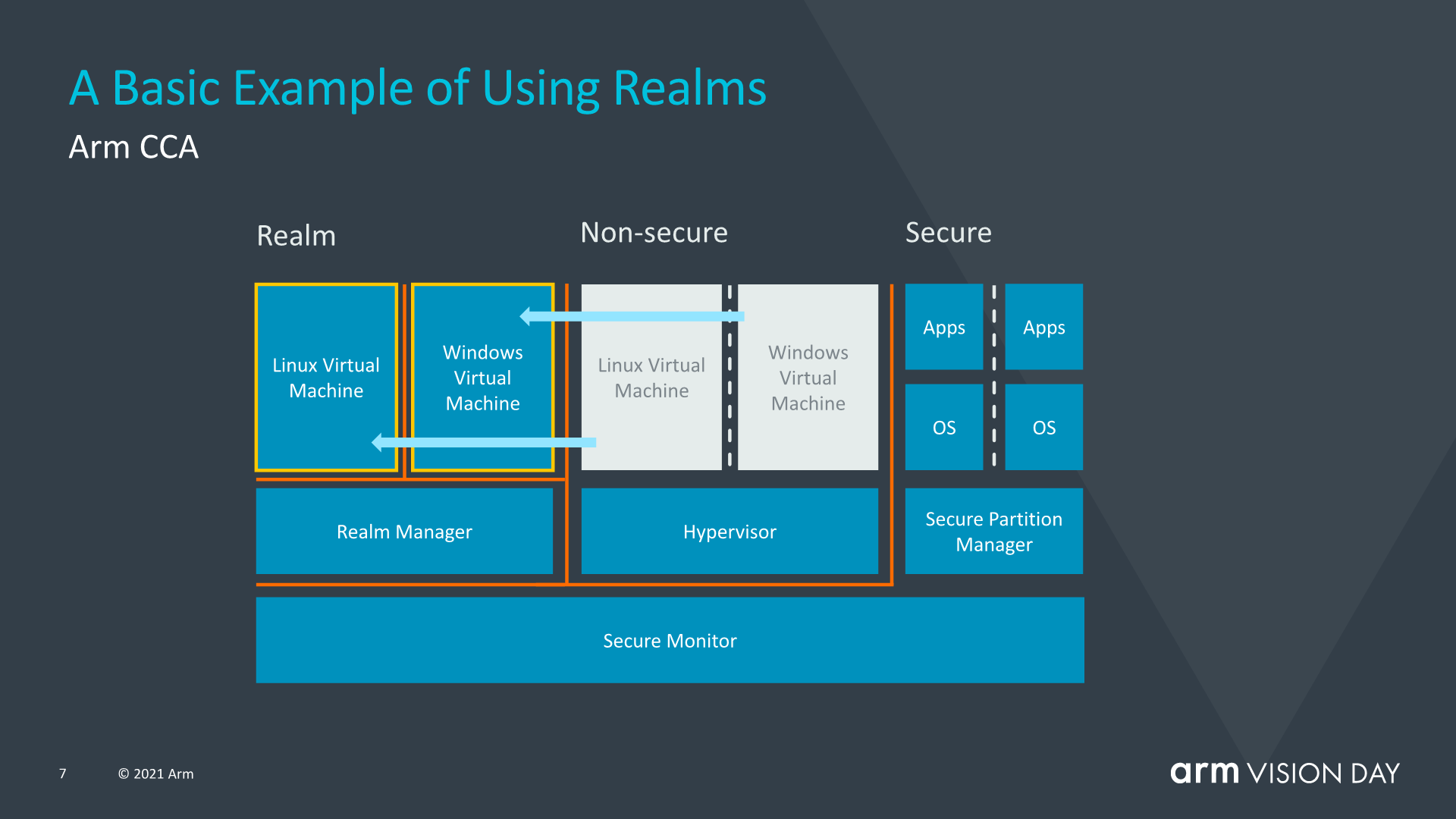
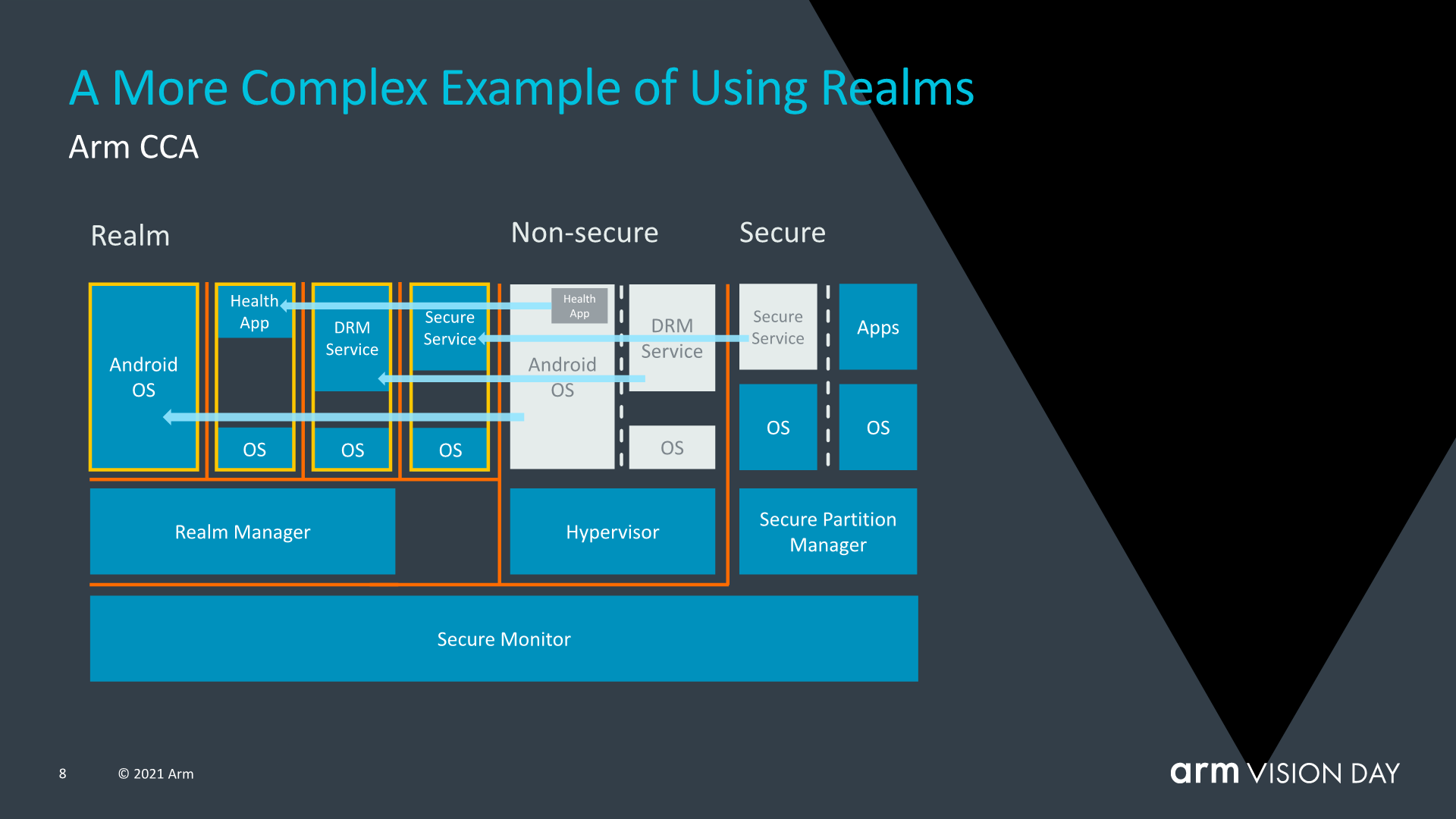
The advantage of the usage of realms is that it vastly reduces the chain of trust of a given application running on a device, with the OS becoming largely transparent to security issues. Mission-critical applications that require supervisory controls would be able to run on any device as say opposed to today’s situation where corporate or businesses require one to use dedicated devices with authorised software stacks.
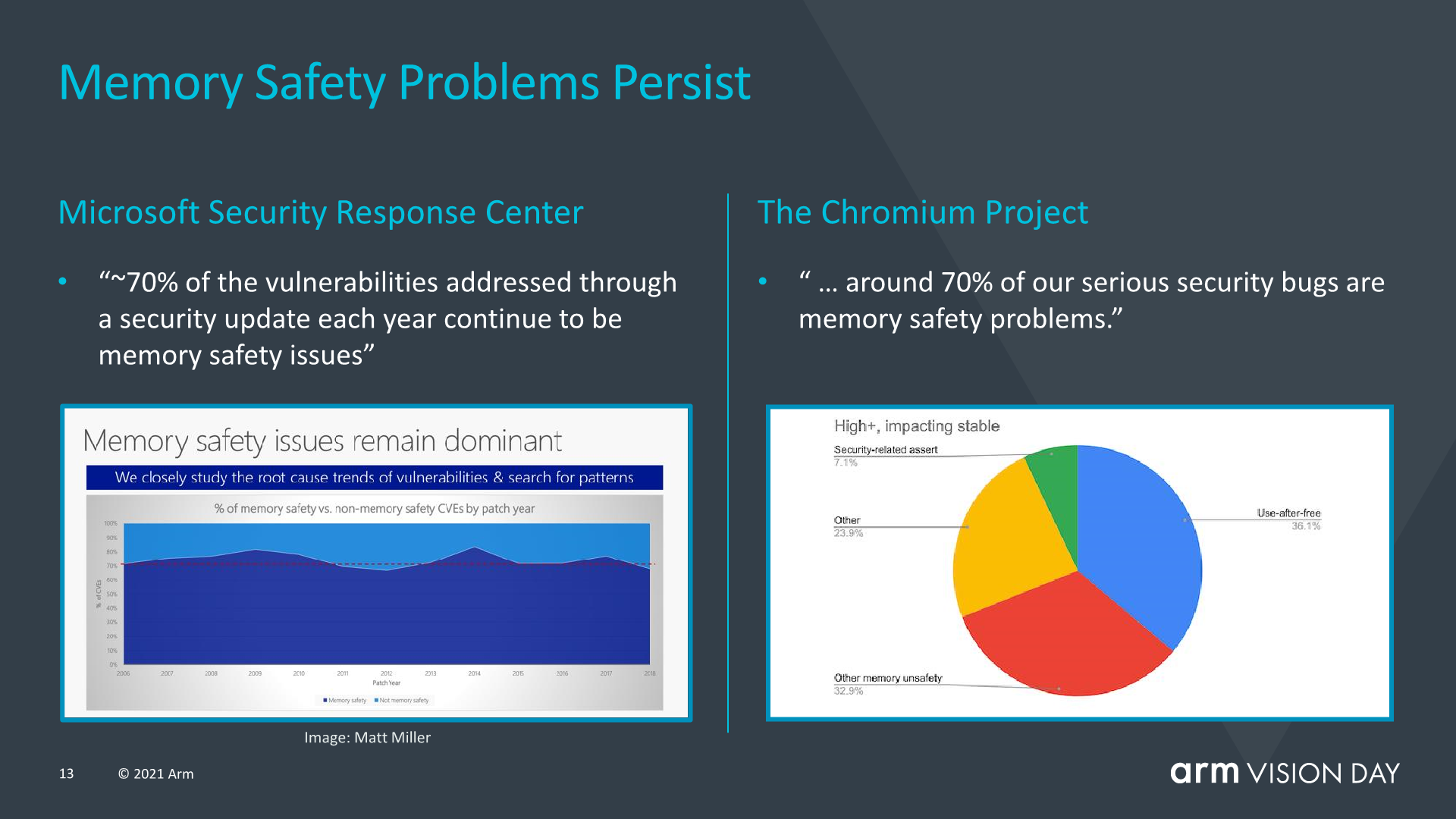
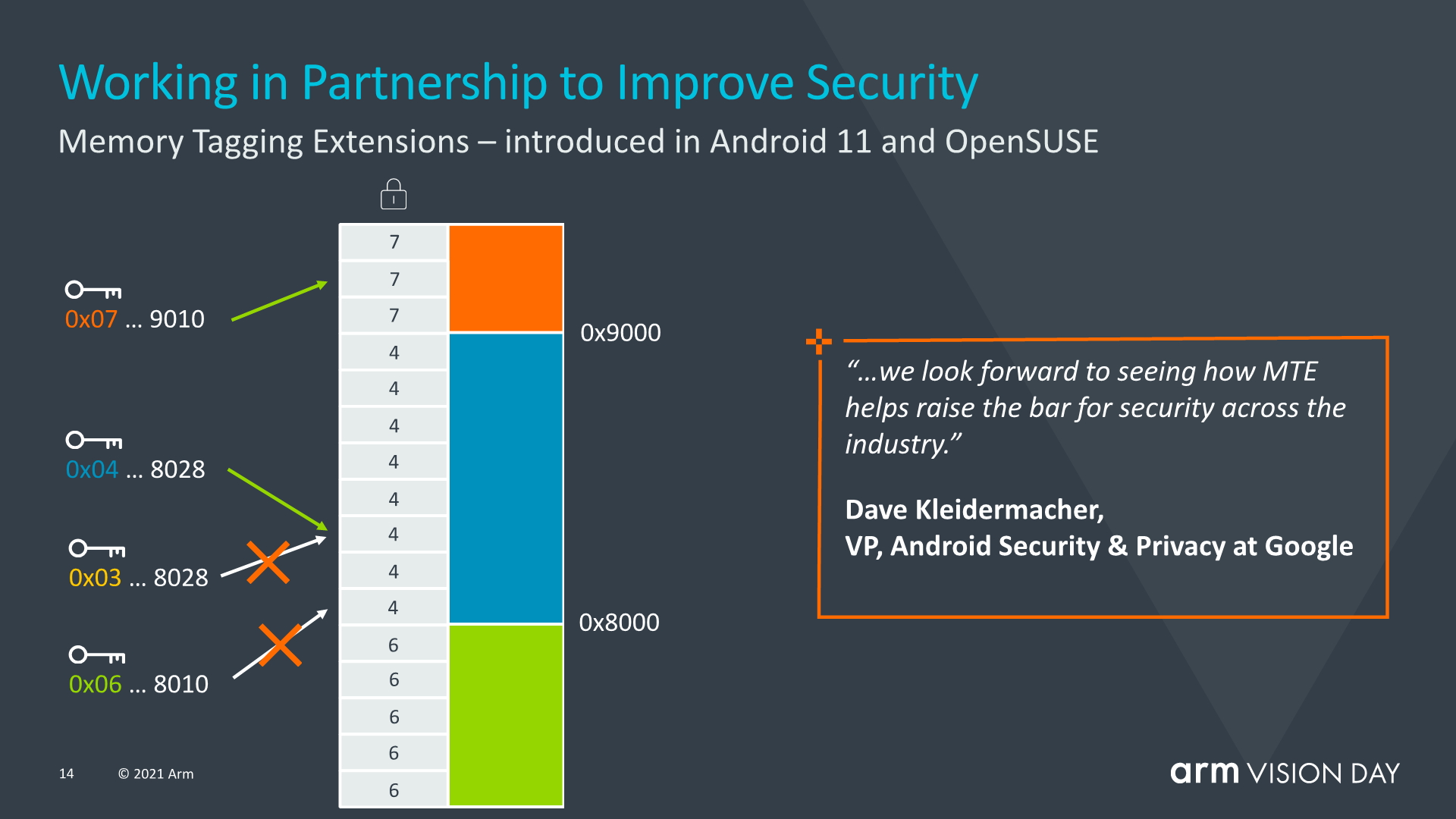
Not new to v9 but rather introduced with v8.5, MTE or memory tagging extensions are aimed to help with two of the most persistent security issues in the world’s software. Buffers overflows and use-after-free are continuing software design issues that have been part of software design for the past 50 years, and can take years for them to be identified or resolved. MTE is aimed at helping identify such issues by tagging pointers upon allocation and checking upon use.








74 Comments
View All Comments
mdriftmeyer - Thursday, April 1, 2021 - link
You're deluded. The amount of Work in Clang on C/C++ should be clear these are the foundational languages. Apple made the mistake of listening to Lattner before he bailed and developed Swift. If they're smart the fully modernize ObjC and turn Swift into a training language.name99 - Tuesday, March 30, 2021 - link
"The benefit of SVE and SVE2 beyond addition various modern SIMD capabilities is in their variable vector size, ranging from 128b to 2048b, allowing variable 128b granularity of vectors, irrespective of what the actual hardware is running on"Not you too, Andrei :-(
This is WRONG! This increased width is a minor benefit outside a few specialized use cases. If you want to process 512 bits of vector data per cycle, you can do that today on an A14/M1 (4 wide NEON).
The primary value of SVE/2 is the introduction of new types of instructions that are a much better match to compilers, and to non-regular algorithms.
Variable width matters, but NOT in the sense that I can build a 128 bit or a 512 bit implementation; it matters in that I can write a single loop (without prologue or epilogue) targeting an arbitrary width array, without expensive overhead. Along with variable-width adjacent functionality like predicate and scatter/gather.
eastcoast_pete - Tuesday, March 30, 2021 - link
Could these properties of SVE2 make Armv9 designs more attractive for, for example, AV1 (and, to come AV2) video encoding?I could see some customer interest there, at least if hosted by AWS or Azure.
name99 - Tuesday, March 30, 2021 - link
I don't know what's involved with AV1 and AV2 encoding. With the older codecs that I do know, most of the encoding algorithm is in fact extremely regular, so there's limited win from providing support for non-regularity.My point is that SVE/2 is primarily a win for types of code that, today, do not benefit much from vectors. It's much less of a win for code that's already strongly improved by vectors.
Andrei Frumusanu - Tuesday, March 30, 2021 - link
That's literally what I meant, in a just less explicit way.Over17 - Thursday, April 8, 2021 - link
What is the "expensive overhead" in question? If you're writing a loop which processes 4 floats, then the tail is no longer than 3 floats. Even if you manually unroll it 4x, then it's 15 floats max to process in the epilogue. For SIMD to give any benefit, you should be processing large amounts of data so even 15 scalar operations is nothing comparing to the main loop.If we're talking about the size of code, then it's true; the predicates in SVE2 are making the code look smaller. So the overhead is more about the maintenance costs, isn't it?
eastcoast_pete - Tuesday, March 30, 2021 - link
Maybe it's just me, but did anyone else notice that Microsoft was prominently mentioned in several slides in ARM's presentation? To me, it means that both companies are very serious about Windows on ARM, including on the server side. I guess we'll see soon enough if the custom-ARM processor MS is apparently working on has Armv9 baked into it already. I would be surprised if it doesn't.And, here my standard complaint about the LITTLE cores: Quo usque tandem, ARM? When will we see a LITTLE core design with out-of-order execution, so that stock ARM designs aren't 2-3 times worse anymore on Perf/W vs Apple's LITTLE cores. That does matter for smartphones, because staying on the LITTLE cores longer and more often improves battery longevity. I know today was about the next big ISA, but some mentioning of "we're working on it" would have been nice.
SarahKerrigan - Tuesday, March 30, 2021 - link
Wouldn't surprise me if the ARMv9 little core looks more like the A65 - narrow OoO.BillBear - Tuesday, March 30, 2021 - link
I wonder if the Matrix Multiplication implementation currently shipping on Apple's M1 chip is just an early implementation of this new spec?https://medium.com/swlh/apples-m1-secret-coprocess...
Apple certainly had an ARM v8 implementation shipping well in advance of anyone else.
name99 - Thursday, April 1, 2021 - link
Seems unlikely.The ARMv8.6 matrix multiply instructions use the NEON or SVE registers
https://community.arm.com/developer/ip-products/pr...
and so can provide limited speedup;
the Apple scheme uses three totally new (and HUGE) registers, the X, Y, and Z registers. It runs within the CPU but "parallel" to the CPU, there are interlocks to ensure that the matrix instructions are correctly sequenced relative to the non-matrix instructions, but overall the matrix instructions run like an old-style (80s or so) coprocessor, not like part of the SIMD/fp unit.
The Apple scheme feels very much like they appreciate it's a stop-gap solution, an experiment that's being evolved. As such they REALLY don't want you to code directly to it, because I expect they will be modifying it (changing register sizes, register layout, etc) every year, and they can hide that behind API calls, but don't want to have to deal with legacy code that uses direct AMX instructions.