AMD's Graphics Core Next Preview: AMD's New GPU, Architected For Compute
by Ryan Smith on December 21, 2011 9:38 PM ESTPrelude: The History of VLIW & Graphics
Before we get into the nuts & bolts of Graphics Core Next, perhaps it’s best to start at the bottom, and then work our way up.
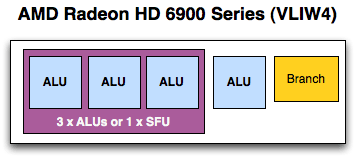
The fundamental unit of AMD’s previous designs has been the Streaming Processor, previously known as the SPU. In every modern AMD design other than Cayman (6900), this is a Very Long Instruction Word 5 (VLIW5) design; Cayman reduced this to VLIW4. As implied by the architectural name, each SP would in turn have 5 or 4 fundamental math units – what AMD now calls Radeon cores – which executed the individual instructions in parallel over as many clocks as necessary. Radeon cores were coupled with registers, a branch unit, and a special function (transcendental) unit as necessary to complete the SP.
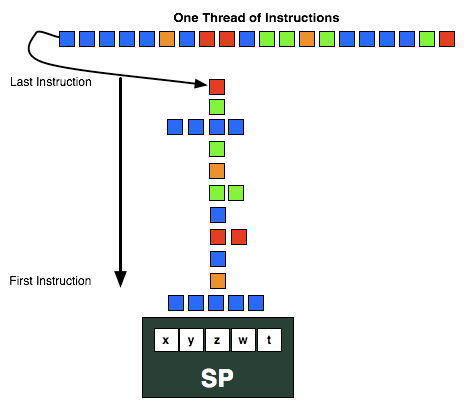
VLIW designs are designed to excel at executing many operations from the same task in parallel by breaking it up into smaller groupings called wavefronts. In AMD’s case a wavefront is a group of 64 pixels/values and the list of instructions to be executed against them. Ideally, in a wavefront a group of 4 or 5 instructions will come down the pipe and be completely non-interdependent, allowing every Radeon core to be fed. When dependent instructions would come down however, fewer instructions could be scheduled at once, and in the worst case only a single instruction could be scheduled. VLIW designs will never achieve perfect efficiency in this regard, but the farther real world utilization is from ideal efficiency, the weaker the benefits of VLIW.
The use of VLIW can be traced back to the first AMD DX9 GPU, R300 (Radeon 9700 series). If you recall our Cayman launch article, we mentioned that AMD initially used a VLIW design in those early parts because it allowed them to process a 4 component dot product (e.g. w, x, y, z) and a scalar component (e.g. lighting) at the same time, which was by far the most common graphics operation. Even when moving to unified shaders in DX10 with R600 (Radeon HD 2900), AMD still kept the VLIW5 design because the gaming market was still DX9 and using those kinds of operations. But as new games and GPGPU programs have come out efficiency has dropped over time, and based on AMD’s own internal research at the time of the Cayman launch the average shader program was utilizing only 3.4 out of 5 Radeon cores. Shrinking from VLIW5 to VLIW4 fights this some, but utilization will always be a concern.
Finally, it’s worth noting what’s in charge of doing all of the scheduling. In the CPU world we throw things at the CPU and let it schedule actions as necessary – it can even go out-of-order (OoO) within a thread if it will be worth it. With VLIW, scheduling is the domain of the compiler. The compiler gets the advantage of knowing about the full program ahead of time and can intelligently schedule some things well in advance, but at the same time it’s blind to other conditions where the outcome is unknown until the program is run and data is provided. Because of this the schedule is said to be static – it’s set at the time of compilation and cannot be changed in-flight.
So why in an article about AMD Graphics Core Next are we going over the quick history of AMD’s previous designs? Without understanding the previous designs, we can’t understand what is new about what AMD is doing, or more importantly why they’re doing it.








83 Comments
View All Comments
mariush - Thursday, December 22, 2011 - link
Last paragraph, last page....It’s clear that 2011 is shaping up to be a big year for GPUs, and we’re not even half-way through. So stay tuned, there’s much more to come.
Say what?
ajp_anton - Thursday, December 22, 2011 - link
It's an old article (I'm guessing June 17th based on first comment), but bumped to the top because of the "launch". Don't know why the article's date is new...AbheekG - Friday, August 9, 2019 - link
2019 and still an article worth studying and referring to. Amazing job with this, it's a prime example of quality tech journalism!