The NVIDIA GeForce GTX 750 Ti and GTX 750 Review: Maxwell Makes Its Move
by Ryan Smith & Ganesh T S on February 18, 2014 9:00 AM ESTMaxwell: Designed For Energy Efficiency
While Maxwell doesn’t come with a significant overhaul of its high level feature set, the same cannot be said for the low level design of Maxwell. In fact the consistency at a high level betrays just how much work NVIDIA has done under the hood in order to improve their efficiency for Maxwell. Maxwell isn’t a complete overhaul of NVIDIA’s designs, nor is it even as aggressive as Kepler was when it eliminated Fermi’s hot clocks in favor of a wider design, but it has a number of changes that are important to understanding the architecture and more importantly understanding how NVIDIA is achieving their efficiency goals.
Broadly speaking, with Maxwell NVIDIA is almost solely focused on improving energy efficiency and performance per watt. This extends directly from NVIDIA’s mobile first design strategy for Maxwell, where the company needs to maximize energy efficiency in order to compete and win within the mobile space. If NVIDIA can bring down their energy consumption, then due to the power limiting factor we mentioned earlier they can use that recovered power overhead to further improve their performance. This again being especially noticeable in SoC-class products and discrete mobile due to the low power budgets these platforms provide.
To a lesser extent NVIDIA is also focused on space efficiency. GPU production costs and space efficiency go hand-in-hand, so there’s an interest in improving the density of their designs with Maxwell. This is especially the case when the earlier power savings allow for a wider GPU with a larger number of functional units within the same power envelope. Denser designs allow for NVIDIA to offer similar performance as larger Kepler GPUs (e.g. GK106) with a smaller Maxwell GPU.
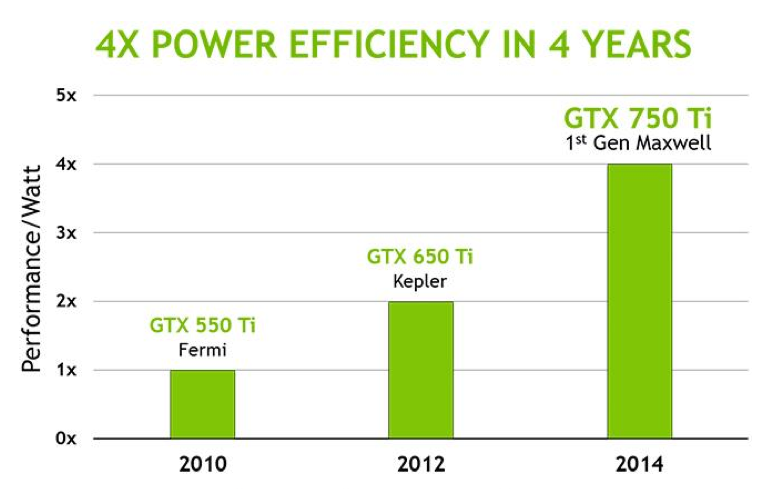
To achieve this NVIDIA has taken a number of steps, some of which they’ve shared with us at a high level and some of which they haven’t. NVIDIA is taking a bit of a “secret sauce” approach to Maxwell from a design level, so while we know a fair bit about its execution model we don’t know quite as much about the little changes that add up to Maxwell’s energy and space savings. However NVIDIA tells us that overall they’ve been able to outright double their performance-per-watt on Maxwell versus Kepler, which is nothing short of amazing given the fact that all of this is being done on the same 28nm process as Kepler.
We’ll go over execution flow and the other gritty details on the next page, but for now let’s start with a look at NVIDIA’s Streaming Multiprocessor designs for Kepler (SMX) and Maxwell (SMM).

Immediately we can see a significant difference in the layout between the SMX and the new SMM. Whereas the SMX was for all practical purposes a large, flat design with 4 warp schedulers and 15 different execution blocks, the SMM has been heavily partitioned. Physically each SMM is still one contiguous unit, not really all that different from an SMX. But logically the execution blocks which each warp scheduler can access have been greatly curtailed.
The end result is that in an SMX the 4 warp schedulers would share most of their execution resources and work out which warp was on which execution resource for any given cycle. But on an SMM, the warp schedulers are removed from each other and given complete dominion over a far smaller collection of execution resources. No longer do warp schedulers have to share FP32 CUDA cores, special function units, or load/store units, as each of those is replicated across each partition. Only texture units and FP64 CUDA cores are shared.
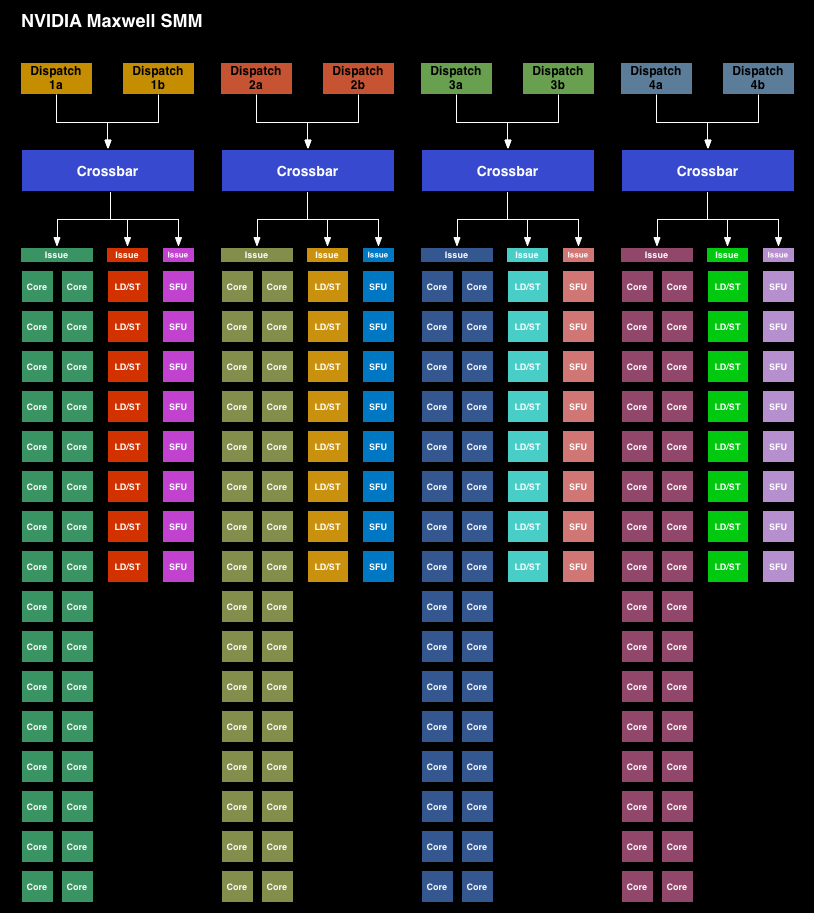
Among the changes NVIDIA made to reduce power consumption, this is among the greatest. Shared resources, though extremely useful when you have the workloads to fill them, do have drawbacks. They’re wasting space and power if not fed, the crossbar to connect all of them is not particularly cheap on a power or area basis, and there is additional scheduling overhead from having to coordinate the actions of those warp schedulers. By forgoing the shared resources NVIDIA loses out on some of the performance benefits from the design, but what they gain in power and space efficiency more than makes up for it.
NVIDIA hasn’t given us hard numbers on SMM power efficiency, but for space efficiency a single 128 CUDA core SMM can deliver 90% of the performance of a 192 CUDA core SMX at a much smaller size.
Moving on, along with the SMM layout changes NVIDIA has also made a number of small tweaks to improve the IPC of the GPU. The scheduler has been rewritten to avoid stalls and otherwise behave more intelligently. Furthermore by achieving higher utilization of their existing hardware, NVIDIA doesn’t need as many functional units to hit their desired performance targets, which in turn saves on space and ultimately power consumption.

While on the subject of performance efficiency, NVIDIA has also been working on memory efficiency too. From a performance perspective GDDR5 is very powerful, however it’s also very power hungry, especially in comparison to DDR3. With GM107 in particular being a 128-bit design that would need to compete with the likes of the 192-bit GK106, NVIDIA has massively increased the amount of L2 cache they use, from 256KB in GK107 to 2MB on GM107. This reduces the amount of traffic that needs to cross the memory bus, reducing both the power spent on the memory bus and the need for a larger memory bus altogether.
Increasing the amount of cache always represents an interesting tradeoff since cache is something of a known quantity and is rather dense, but it’s only useful if there are memory stalls or other memory operations that it can cover. Consequently we often see cache implemented in relation to whether there are any other optimizations available. In some cases it makes more sense to use the transistors to build more functional units, and in other cases it makes sense to build the cache. After staying relatively stagnant on their cache sizes for so long, it looks like the balance has finally shifted and the cache increase makes the most sense for NVIDIA.
Of course even these changes are relatively high level from an ASIC perspective. There’s always the possibility for low-level changes and NVIDIA has followed through on these too. Case in point, both NVIDIA and AMD have been steadily improving their clock gating capabilities, and with Maxwell NVIDIA has taken another step in their designs. NVIDIA isn’t telling us just how fine grained their gating is now for Maxwell, but it’s a finer granularity than it was on Kepler. Given the new SM design, the most likely change was likely the ability to control the individual partitions and/or the functional units within those partitions, but this is just supposition on our part.
Finally there’s the lowest of low level optimizations, which is transistor level optimizations. Again NVIDIA hasn’t provided a ton of details here, but they tell us they’ve gone through at the transistor level to squeeze out additional energy efficiency as they could find it. Given that TSMC 28nm is now a very mature process with well understood abilities and quirks, NVIDIA should be able to design and build their circuits to a tighter tolerance now than they would have been able to when working on GK107 over 2 years ago.








177 Comments
View All Comments
texasti89 - Tuesday, February 18, 2014 - link
http://media.bestofmicro.com/4/R/422667/original/F...texasti89 - Tuesday, February 18, 2014 - link
Also I was referring to the 750ti (60w) not the 750 (55w) in my comment. Words in the article reflect reviewers opinions. Benchmark results from various tech websites give same conclusion.texasti89 - Tuesday, February 18, 2014 - link
Another one to look at : http://www.techpowerup.com/reviews/NVIDIA/GeForce_...tspacie - Tuesday, February 18, 2014 - link
[Coming soon to a flu near you]This is a caching error or similar on page 4, right?
mindbomb - Tuesday, February 18, 2014 - link
Hello Ryan and Ganesh. I'd like to point out for your video tests that there is no luma upscaling or image doubling for a 1080p video on a 1080p display, since luma is already scaled. You need to test those with a 720p video, and they are mutually exclusive, since image doubling will convert 1280x720 to 2560x1440, where you will need to downscale rather than upscale.ganeshts - Tuesday, February 18, 2014 - link
Luma upscaling is present for 480i / 576i / 720p videos and downscaling for the 4Kp30 video. We have nine different sample streams.jwcalla - Tuesday, February 18, 2014 - link
I'd like to see AT adopt some OpenGL benchmarks in the future.Us OpenGL consumers are out here. :)
Ryan Smith - Thursday, February 20, 2014 - link
So would I. But at the moment there aren't any meaningful games using OpenGL that are suitable for benchmarking. After Wolfenstein went out of date and Rage was capped at 60fps, we ended up stuck in that respect.Roland00Address - Tuesday, February 18, 2014 - link
Feel better Ryan, don't let the flu get you down! (Or is it Ganesh T S?)Looks like Nvidia has a 8800gt/9800gt on its hands (for different reasons than the original 8800gt)
Hrel - Tuesday, February 18, 2014 - link
Seriously impressive performance/watt figures in here. Makes me wonder when we're going to see this applied to their higher end GPU's.Looking at TSMC's site they are already producing at 20nm in 2 fabs. Starting in May of this year they'll have a 3rd up. Do you think it's likely May/June is when we'll see Maxwell make it's way into higher end GPU's accompanied by a shift to 20nm?
That approach would make sense to me, they'd have new product out in time for Summer Sales and have enough time to ramp production and satiate early adopters before back to school specials start up.
On a personal note: I'm still running a GTX460 and the GTX750ti seems to be faster in almost every scenario at lower power draw in a smaller package. So that's pretty cool. But since TSMC is already producing 20nm chips I'm going to wait until this architecture can be applied at a smaller manufacturing process. That GPU is in a media PC, so gaming is a tertiary concern anyway.