Imagination's PowerVR Rogue Architecture Explored
by Ryan Smith on February 24, 2014 3:00 AM EST- Posted in
- GPUs
- Imagination Technologies
- PowerVR
- PowerVR Series6
- SoCs
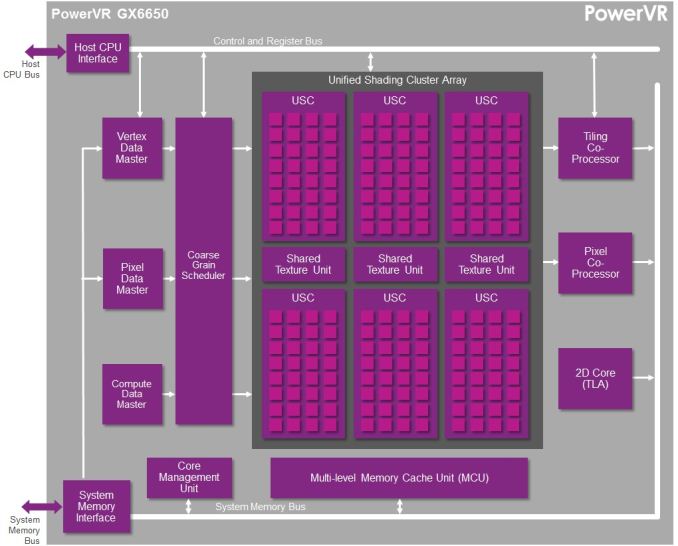
When it comes to our coverage of SoCs, one aspect we’ve been trying to improve on for some time now is our coverage and understanding of the GPU portion of those SoCs. In the PC space we’re fortunate that there are just three major players – Intel, NVIDIA, and AMD – and that all three of them have over the years learned how to become very open and forthcoming about their GPU architectures. As a result we’ve had a level of access that has allowed us to better understand PC GPUs in a way that in earlier times simply wasn’t possible.
In the SoC space however we haven’t been so fortunate. Our understanding of most SoC GPU architectures has not been nearly as deep due to the fact that SoC GPU designers have been less willing to come forward with public details about their architectures and how those architectures have evolved over the years. And this has been for what’s arguably a good reason – unlike the PC GPU space, where only 2 of the 3 players compete in either the iGPU or dGPU markets, in the SoC GPU space there are no fewer than 7 players, all of whom are competing in one manner or another: NVIDIA, Imagination Technologies, Intel, ARM, Qualcomm, Broadcom, and Vivante.
Some of these players use their designs internally while others license out their designs as IP for inclusion in 3rd party SoCs, but all these players are in a much more competitive market that is in a younger place in its life. All the while SoC GPU development still happens at a relatively quick pace (by GPU standards), leading to similarly quick turnarounds between GPU generations as GPU complexity has not yet stretched out development to a 3-4 year process. As a result of SoC GPUs still being a young and highly competitive market, it’s a foregone conclusion that there is still a period of consolidation ahead of us – not unlike what has happened to SoC integrators such as TI – which provides all the more reason for SoC GPU players to be conservative about providing public details about their architectures.
With that said, over the years we have made some progress in getting access to the technical details, due in large part to the existing openness policies of NVIDIA and Intel. Nevertheless, as two of the smaller players in the mobile GPU space this still leaves us with few details on the architectures behind the majority of SoC GPUs. We still want more.
This brings us to today. In what should prove to be an extremely eventful and important day for our coverage and understanding of SoC GPUs, we’d like to welcome Imagination Technologies to the “open architecture” table. Imagination chosen to share more details about the inner workings of their Rogue Series 6 and Series 6XT architectures, thereby giving us our first in-depth look at the architecture that’s powering a number of high-end products (not the least of which is all of Apple’s current-gen products) and descended from some of the most widely used SoC GPU designs of all time.

Now Imagination is not going to be sharing everything with us today. The bulk of the details Imagination is making available relate to their Unified Shading Cluster (USC) shading block, the heart of the Series 6/6XT GPUs. They aren’t discussing other aspects of their designs such as their geometry processors, cache structure, or Tile Based Deferred Rendering system – the company’s secret sauce and most potent weapon for SoC efficiency – but hopefully one day we’ll get there. In the meantime we will have our hands full just taking our first look at the Series 6/6XT USCs.
Finally, before we begin we’d like to thank Imagination for giving us this opportunity to evaluate their architecture in such great detail. We’ve been pushing for this for quite some time, so we’re pleased that this is coming to pass.
Imagination is publishing a pair of blogs and pseudo whitepapers on their website today: Graphics cores: trying to compare apples to apples, and PowerVR GX6650: redefining performance in mobile with 192 cores. Along with this they have also been answering many of our deepest technical questions, so we should have a good handle on the Rogue USC. So with that in mind, let’s dive in.








95 Comments
View All Comments
errorr - Sunday, March 2, 2014 - link
Re tile based rendering the Mali guys on their blog outlined their thought process on why they chose tile based rendering.Ultimately it is all about power. TBR allows them to avoid memory reads and writes by keeping the color and z-buffer on chip. They also keep the multisample buffer on chip Which allows them to do 16x msaa at very low power cost.
The biggest power hog though is textures which still reside in memory. This means that complex or large textures will basically overwhelm Amy power savings. Basically TBR becomes less efficient when pushed to the max of its capabilities like in many benchmarks.
http://community.arm.com/groups/arm-mali-graphics/...
errorr - Sunday, March 2, 2014 - link
Oh, I also wanted to note that the ARM Mali blog announced that they were going to talk about their shader architecture in an upcoming blog post. The last part in a series about the latest Mali and openGL ES compliance. The previous part talked about tile based rendering and how to get power savings from it.The interesting things I've learned.from the blog include some great stuff not even discussed by imagination.
Mali has a way of comparing the current state of the frame buffer with incoming tiles, if they are identical then the new tile is discarded instead of taking power to write to the frame buffer.
Also, texture compression can save a lot of memory.
The biggest eye opener though was that the way Android handles draw calls means that both CPU and GPU are starved for work and dvfs isn't responsive enough or granular enough to allow for power gating. It seems the problem has to do with screen orientation and android preventing ideal asynchronous Possessing of work.
RAYBOYD44 - Monday, March 3, 2014 - link
uptil I looked at the receipt which had said $9859 , I did not believe that...my... sister had been actualie receiving money in there spare time at their computer. . there aunts neighbour had bean doing this for only about fifteen months and just now took care of the morgage on there appartment and purchased a great Porsche 911 .MrPoletski - Monday, March 10, 2014 - link
DAFUQ?hi.wonjoon - Sunday, May 4, 2014 - link
does this post say that rogue architecture doing some stuff like HyperThreading in Intel? I just wondering I understood in right way.