Imagination's PowerVR Rogue Architecture Explored
by Ryan Smith on February 24, 2014 3:00 AM EST- Posted in
- GPUs
- Imagination Technologies
- PowerVR
- PowerVR Series6
- SoCs
When it comes to our coverage of SoCs, one aspect we’ve been trying to improve on for some time now is our coverage and understanding of the GPU portion of those SoCs. In the PC space we’re fortunate that there are just three major players – Intel, NVIDIA, and AMD – and that all three of them have over the years learned how to become very open and forthcoming about their GPU architectures. As a result we’ve had a level of access that has allowed us to better understand PC GPUs in a way that in earlier times simply wasn’t possible.
In the SoC space however we haven’t been so fortunate. Our understanding of most SoC GPU architectures has not been nearly as deep due to the fact that SoC GPU designers have been less willing to come forward with public details about their architectures and how those architectures have evolved over the years. And this has been for what’s arguably a good reason – unlike the PC GPU space, where only 2 of the 3 players compete in either the iGPU or dGPU markets, in the SoC GPU space there are no fewer than 7 players, all of whom are competing in one manner or another: NVIDIA, Imagination Technologies, Intel, ARM, Qualcomm, Broadcom, and Vivante.
Some of these players use their designs internally while others license out their designs as IP for inclusion in 3rd party SoCs, but all these players are in a much more competitive market that is in a younger place in its life. All the while SoC GPU development still happens at a relatively quick pace (by GPU standards), leading to similarly quick turnarounds between GPU generations as GPU complexity has not yet stretched out development to a 3-4 year process. As a result of SoC GPUs still being a young and highly competitive market, it’s a foregone conclusion that there is still a period of consolidation ahead of us – not unlike what has happened to SoC integrators such as TI – which provides all the more reason for SoC GPU players to be conservative about providing public details about their architectures.
With that said, over the years we have made some progress in getting access to the technical details, due in large part to the existing openness policies of NVIDIA and Intel. Nevertheless, as two of the smaller players in the mobile GPU space this still leaves us with few details on the architectures behind the majority of SoC GPUs. We still want more.
This brings us to today. In what should prove to be an extremely eventful and important day for our coverage and understanding of SoC GPUs, we’d like to welcome Imagination Technologies to the “open architecture” table. Imagination chosen to share more details about the inner workings of their Rogue Series 6 and Series 6XT architectures, thereby giving us our first in-depth look at the architecture that’s powering a number of high-end products (not the least of which is all of Apple’s current-gen products) and descended from some of the most widely used SoC GPU designs of all time.

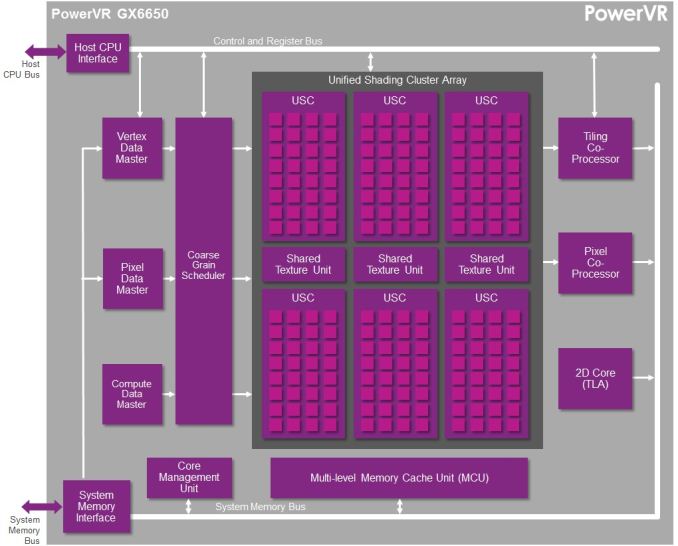
Now Imagination is not going to be sharing everything with us today. The bulk of the details Imagination is making available relate to their Unified Shading Cluster (USC) shading block, the heart of the Series 6/6XT GPUs. They aren’t discussing other aspects of their designs such as their geometry processors, cache structure, or Tile Based Deferred Rendering system – the company’s secret sauce and most potent weapon for SoC efficiency – but hopefully one day we’ll get there. In the meantime we will have our hands full just taking our first look at the Series 6/6XT USCs.
Finally, before we begin we’d like to thank Imagination for giving us this opportunity to evaluate their architecture in such great detail. We’ve been pushing for this for quite some time, so we’re pleased that this is coming to pass.
Imagination is publishing a pair of blogs and pseudo whitepapers on their website today: Graphics cores: trying to compare apples to apples, and PowerVR GX6650: redefining performance in mobile with 192 cores. Along with this they have also been answering many of our deepest technical questions, so we should have a good handle on the Rogue USC. So with that in mind, let’s dive in.








95 Comments
View All Comments
grahaman27 - Monday, February 24, 2014 - link
Because apple can't have all the cool stuff!CiccioB - Monday, February 24, 2014 - link
Architecture wise, PowerVR seems more alike AMD's VLIW then nvidia's Kepler (or G200 or Fermi or Maxwell).That means PowerVR is going to have the same issues AMD had with VLIW and general computing performances and ILP.
There are also many interesting facts that could be analysed:
1. AMD went from having 5 computing ALUs to 4 to improve efficiency before switching to a completely new architetecture (CGN). PowerVR went from 5 to 7 ALUs (if we consider them all as separate units, are you sure it can process 16bit instructions togheter with 32bits one and not that those 32bits units can each execute 2x16bits instructions alternatively?)
2. PowerVR is using the same marketing politics used by AMD to count their computing core. They showed they had more computing core than nvidia competitor's architecture, but in the end, for the fact that they couldn't keep all of them feeded, they were less efficient.
3. nvidia passing from Kepler desktop to Kepler mobile removed ROPs and TMU. So, probably they think their architetcure (and GPUs on mobile in general) are less bottlenecked under those terms. PowerVR went incresing them, so they possibly think ROPs and TMU are more important then shaders... which is which? Both of them are trying to hide some deficiency of their respective architetcture?
4. We do not really know anything about PowerVR geometry power. nvidia in Kepler SMX has special function units (polymorph engine) that is connected directly to the shaders. That seems to give a enormous boost to geometric performaces (expecially tesselation) that rightly scale with the number of active SMX. PowerVR seems to have chosen AMD implementation with off-computational-core tesselator that do not scale automatically. How's going to behave PowerVR with future games that may need more geometric performances?
5. Again, as someone altready asked, tile based rendering was used on the desktop but was soon abandoned as it could not give any real advantages over the raw power of other architectures that grew much faster that what PowerVR could optimize their algorithms, making tile based rendering less and less profitable. What makes that scenario different that what we are witnessing in this period where mobile resolutions are growing to be even bigger than desktop monitors and that games complexity is gonig to increase for the arrival of these really powerful GPUs (K1 in primis)?
6. We lack the die area occupation comparison. How big is a 6 modules Rogue with respect to nvidia K1? If it is, just to say, twice nvidia die area, that would be a problem even thought the power consumption is the same. If it half, that would mean that PowerVR could make double K1 perfomance (if we believe Rogue 192 shaders perform like Kepler 192 ones). That would mean nvidia is in trouble just before beginning the high end socket race.
7. It seems PowerVR is behaving a bit like 3DFx did at the time, till it died. They were using their advanced but old technology to the exterme, so they rendered at 16bit instead of 32, used 16bit Zbuffer instead of 24 and many more "tricks" that were forced to try to hide what was quite clear: 3DFX didn't have the right architecture to compete with new companies like nvidia and ATI that started their story with the right step and much more powerful architectures (TNT2 simply destroyed Voodoo3 under all points, and beware, I was an Voodoo3 unfortunate owner). Will PowerVR go the same end trying to force the use of obsolete technics while all the others competitors are clearly pointing to constantly increasing raw power with no trade-offs (or with minimal ones?)
DanNeely - Monday, February 24, 2014 - link
AMDs shift from VLIW5 to VLIW4 was driven by the decline of DX9. DX9 was explicitly designed around a 5 step path; VLIW5 was tied directly to that. DX10's more flexible workflow rarely allowed for a 5 wide execution path.For VLIW4 AMD tied functional units together more than Imagination appears to've done here. They have 4 normal ALUs that match with the 4x 16bit ALUs in Rouge; but to do a special function operation they used 3 of the 32bit ALUs instead of using dedicated hardware. The tradeoff was that a special function cost a lot more normal processing capacity than it did before. Power VR doesn't appear to have put enough general purpose computing power place to do the same, and is required to use a dedicated SFU by default (even assuming they felt the tradeoff was worth like AMD does).
The main thing I'm curious about is if the 16 and 32bit ALUs are separate hardware; or if they implemented them similar to how SSE/AVX are done on x86 where the same hardware can do 2 32 (16) bit or 1 64 (32) bit operation.
http://www.anandtech.com/show/4061/amds-radeon-hd-...
Ryan Smith - Monday, February 24, 2014 - link
"The main thing I'm curious about is if the 16 and 32bit ALUs are separate hardware; or if they implemented them similar to how SSE/AVX are done on x86 where the same hardware can do 2 32 (16) bit or 1 64 (32) bit operation."They're separate hardware. Just as how NVIDIA uses separate FP32 and FP64 CUDA cores.
ryszu - Monday, February 24, 2014 - link
We're nothing like VLIW4/5, mobile Kepler still has ROPs and texture hardware, the area is absolutely nowhere near where you think it is and the architectural features we have in the front-end remain class leading and entirely sensible for mobile.CiccioB - Monday, February 24, 2014 - link
Sorry, maybe I was not that clear. I didn't meant they removed completely ROPs and TMUs, I was hinting to the fact that they decreased their number in a SMSX for mobile with respect to a SMX for desktop. ROPs are tied to memory channel, and that may be the cause. But TMUs are not, so they could be the same number as they are in desktop implementation.It seems nvidia sees those many ROPs and TMUs bottlenecked by RAM bandwidth so they spare space and power by not adding them.
PowerVR on the contrary has a ROPs and TMUs ratio with respect to shaders (or computing core) that is much higher. One or the other took the wrong assumption (also tied to the memory controller width, that may be higher as you want but costs in terms of die size and power). I'm curious to know who made it.
ryszu - Monday, February 24, 2014 - link
Ah, I see. Our ALU:TEX:ROP is different to Kepler (and again to Maxwell), yes. We're focused on still being strong for the basics (texturing, pixel fill) while still having a lot of shading to go with it. I can't speak for NV's design choices, just that both have pros and cons depending on market.The rest of your comment still has a lot of problems in respect to the PowerVR Rogue architecture and how it works, how it works in mobile, and how it compares to K1 and pre-GCN AMD.
Ryan Smith - Monday, February 24, 2014 - link
"Architecture wise, PowerVR seems more alike AMD's VLIW then nvidia's Kepler (or G200 or Fermi or Maxwell).That means PowerVR is going to have the same issues AMD had with VLIW and general computing performances and ILP."
To be honest I had the same thought at first. We've known that Rogue has multiple slots per pipeline since the Apple A7 came out, so when I first heard that I had the same thought. Given the greater simplicity of mobile SoCs, it would certainly make sense.
That said, after finally having access to IMG's technical details, it's clear to me that this is not the case, which was part of the reason I was so excited to work on this article. It's sort of like Fermi and it's sort of like VLIW5, but in reality it's neither.
The most important point is that in AMD's VLIW designs they had 4/5 ALUs all alike (for the sake of this discussion we'll ignore the T-unit). So to maximize a Streaming Processor's utilization, you needed to be able to extract a full 4-5 instructions of ILP out of a thread. Which was easy to do under DX9 (RGBA + lighting) and a lot harder to do under DX10.
Rogue on the other hand doesn't have ILP requirements nearly as high due to the fact that the 6 ALUs are not identical and are rarely all going to be in use at once (we don't even count the FP16 units in our GFLOPs calculations). They do have ILP requirements, unlike GCN, but for FP32 it's only 2 instructions for the 2 FP32 ALUs. This is in fact rather similar to Kepler (but not Maxwell) in that NVIDIA has a similar reliance on ILP to keep all of their CUDA cores fed. Half of the threads on Kepler need to co-issue another FP32 op to fill the other 64 CUDA cores in an SMX; Rogue is a bit worse in this regard since every thread needs to co-issue to fill every second FP32 ALU.
FP16 on the other hand is trickier, since that's a full 4 ALU setup. Worst case scenario is that IMG needs to pull off 4 instructions of ILP to maximize their utilization, but this is a bit murkier since we don't know why Series 6 had the unusual 3 operator FP16 ALUs in the first place. As such I'm less familiar with where FP16 is being used in mobile today, so it's harder to draw comparisons for what FP16 utilization may be like. That said, there's also the unknown of die size and power requirements of using FP16 units for FP16 math versus using FP32 units for the same task. I'm not sure if IMG has reason to be worried about FP16 utilization if they can pack 2x as much hardware in the same die size and power envelope.
Ultimately I'd classify Rogue as being closer to Fermi/Kepler than VLIW, which is why those are the comparisons we went with in the article. The 2 wide FP32 pipeline isn't nearly as narrow as AMD's VLIW, and the instructions themselves aren't the inflexible chaos that was VLIW as a language.
"Again, as someone altready asked, tile based rendering was used on the desktop but was soon abandoned as it could not give any real advantages over the raw power of other architectures that grew much faster that what PowerVR could optimize their algorithms, making tile based rendering less and less profitable. What makes that scenario different that what we are witnessing in this period where mobile resolutions are growing to be even bigger than desktop monitors and that games complexity is gonig to increase for the arrival of these really powerful GPUs (K1 in primis)?"
One of the problems IMG faced in the old days was that DirectX and Windows weren't very well suited for their TBDR design; they pretty much had to fight the API at times to get what they wanted. For iOS/Android it's difficult to draw comparisons - though I'd note iOS has always been driven by IMG GPUs and hence always used TBDR - but Windows for its part has since gotten much better. In particular there are API hooks to allow applications to see if the GPU is TBDR. I'm not sure if that's enough, but it does mean things have changed at least a little bit since the old days.
Scali - Monday, February 24, 2014 - link
In D3D11 there is now a flag to indicate whether you are running on a TBDR device or not: http://msdn.microsoft.com/en-us/library/windows/de...CiccioB - Monday, February 24, 2014 - link
I didn't realize that in counting those GFlops you ignored the 16bit ALUs, Issuing two instructions should be much easier than issuing 3, 4 or even 5, not to speak about 6 or 7.However I bet that PowerVR next architecture (or the next one again) will remove those 16bit ALUs and will introduce a couple of them able to issue 32 OR 2x16bit instruction, so that they can pack more shaders in the same area.
About TBDR design... the alternative to DirectX is OpenGL. Is it more suited for TBDR architecture than "brute force" ones?
Still I perceive PowerVR architecture as something from the past that has survived to to now until the big one have entered the mobile game for real. Kepler is a very efficient architecture and Maxwell has demonstrated that it can be even better. How is PowerVR going to fight against an architecture as flexible as nvidia ones that can also be used for CUDA computing and thus being adopted into markets (and for other tasks) PowerVR cannot with their current architecture? Not to forget that nvidia can now easily bring to their mobile versions whatever engine exists for their desktop GPUs.
Will extreme (but not so flexible) efficiency win against something not that efficient but able to do much more things in a easier way?
Would mobile game engines bet more on computing shaders power or memory bandwidth?
Will new DX10/DX11-alike engines (whose features are supported by new architectures) still be TBDR friendly? Does TBDR design still scale for the modern ultra high resolution displays or as for desktops "brute force" (or simply more power more performance) will rule out?
I think this year will tell us very much.