The Apple iPad Pro Review
by Ryan Smith, Joshua Ho & Brandon Chester on January 22, 2016 8:10 AM ESTSoC Analysis: On x86 vs ARMv8
Before we get to the benchmarks, I want to spend a bit of time talking about the impact of CPU architectures at a middle degree of technical depth. At a high level, there are a number of peripheral issues when it comes to comparing these two SoCs, such as the quality of their fixed-function blocks. But when you look at what consumes the vast majority of the power, it turns out that the CPU is competing with things like the modem/RF front-end and GPU.
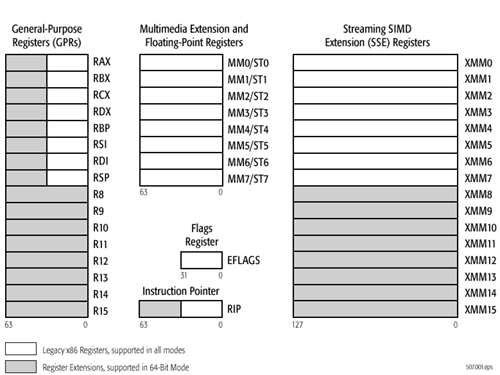
x86-64 ISA registers
Probably the easiest place to start when we’re comparing things like Skylake and Twister is the ISA (instruction set architecture). This subject alone is probably worthy of an article, but the short version for those that aren't really familiar with this topic is that an ISA defines how a processor should behave in response to certain instructions, and how these instructions should be encoded. For example, if you were to add two integers together in the EAX and EDX registers, x86-32 dictates that this would be equivalent to 01d0 in hexadecimal. In response to this instruction, the CPU would add whatever value that was in the EDX register to the value in the EAX register and leave the result in the EDX register.
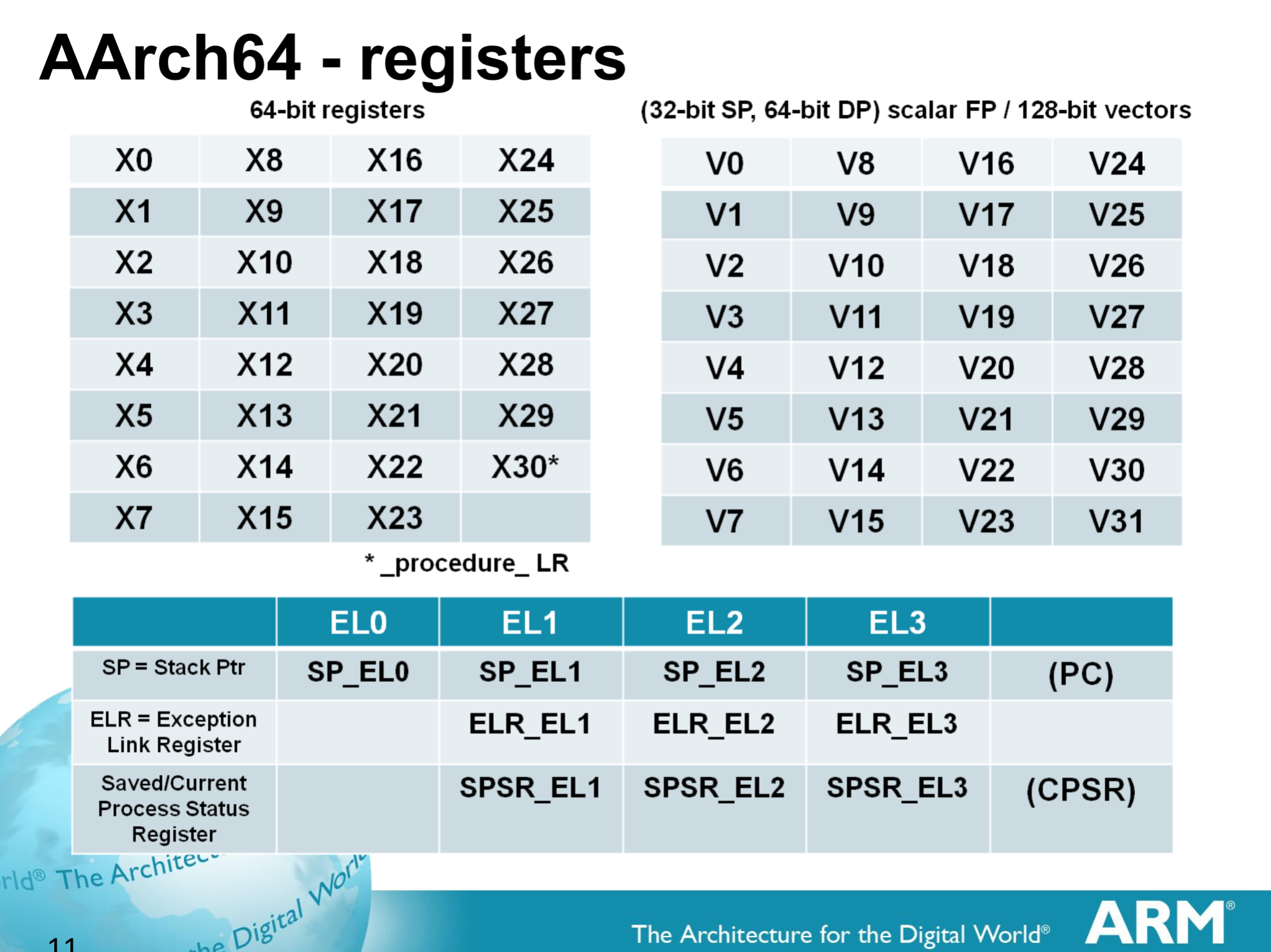
ARMv8 A64 ISA Registers
The fundamental difference between x86 and ARM is that x86 is a relatively complex ISA, while ARM is relatively simple by comparison. One key difference is that ARM dictates that every instruction is a fixed number of bits. In the case of ARMv8-A and ARMv7-A, all instructions are 32-bits long unless you're in thumb mode, which means that all instructions are 16-bit long, but the same sort of trade-offs that come from a fixed length instruction encoding still apply. Thumb-2 is a variable length ISA, so in some sense the same trade-offs apply. It’s important to make a distinction between instruction and data here, because even though AArch64 uses 32-bit instructions the register width is 64 bits, which is what determines things like how much memory can be addressed and the range of values that a single register can hold. By comparison, Intel’s x86 ISA has variable length instructions. In both x86-32 and x86-64/AMD64, each instruction can range anywhere from 8 to 120 bits long depending upon how the instruction is encoded.
At this point, it might be evident that on the implementation side of things, a decoder for x86 instructions is going to be more complex. For a CPU implementing the ARM ISA, because the instructions are of a fixed length the decoder simply reads instructions 2 or 4 bytes at a time. On the other hand, a CPU implementing the x86 ISA would have to determine how many bytes to pull in at a time for an instruction based upon the preceding bytes.
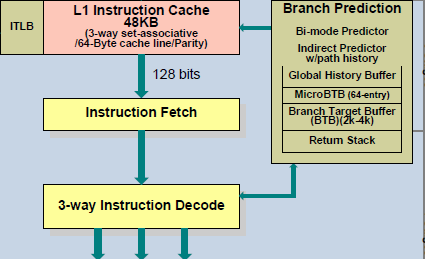
A57 Front-End Decode, Note the lack of uop cache
While it might sound like the x86 ISA is just clearly at a disadvantage here, it’s important to avoid oversimplifying the problem. Although the decoder of an ARM CPU already knows how many bytes it needs to pull in at a time, this inherently means that unless all 2 or 4 bytes of the instruction are used, each instruction contains wasted bits. While it may not seem like a big deal to “waste” a byte here and there, this can actually become a significant bottleneck in how quickly instructions can get from the L1 instruction cache to the front-end instruction decoder of the CPU. The major issue here is that due to RC delay in the metal wire interconnects of a chip, increasing the size of an instruction cache inherently increases the number of cycles that it takes for an instruction to get from the L1 cache to the instruction decoder on the CPU. If a cache doesn’t have the instruction that you need, it could take hundreds of cycles for it to arrive from main memory.
Of course, there are other issues worth considering. For example, in the case of x86, the instructions themselves can be incredibly complex. One of the simplest cases of this is just some cases of the add instruction, where you can have either a source or destination be in memory, although both source and destination cannot be in memory. An example of this might be addq (%rax,%rbx,2), %rdx, which could take 5 CPU cycles to happen in something like Skylake. Of course, pipelining and other tricks can make the throughput of such instructions much higher but that's another topic that can't be properly addressed within the scope of this article.
By comparison, the ARM ISA has no direct equivalent to this instruction. Looking at our example of an add instruction, ARM would require a load instruction before the add instruction. This has two notable implications. The first is that this once again is an advantage for an x86 CPU in terms of instruction density because fewer bits are needed to express a single instruction. The second is that for a “pure” CISC CPU you now have a barrier for a number of performance and power optimizations as any instruction dependent upon the result from the current instruction wouldn’t be able to be pipelined or executed in parallel.
The final issue here is that x86 just has an enormous number of instructions that have to be supported due to backwards compatibility. Part of the reason why x86 became so dominant in the market was that code compiled for the original Intel 8086 would work with any future x86 CPU, but the original 8086 didn’t even have memory protection. As a result, all x86 CPUs made today still have to start in real mode and support the original 16-bit registers and instructions, in addition to 32-bit and 64-bit registers and instructions. Of course, to run a program in 8086 mode is a non-trivial task, but even in the x86-64 ISA it isn't unusual to see instructions that are identical to the x86-32 equivalent. By comparison, ARMv8 is designed such that you can only execute ARMv7 or AArch32 code across exception boundaries, so practically programs are only going to run one type of code or the other.
Back in the 1980s up to the 1990s, this became one of the major reasons why RISC was rapidly becoming dominant as CISC ISAs like x86 ended up creating CPUs that generally used more power and die area for the same performance. However, today ISA is basically irrelevant to the discussion due to a number of factors. The first is that beginning with the Intel Pentium Pro and AMD K5, x86 CPUs were really RISC CPU cores with microcode or some other logic to translate x86 CPU instructions to the internal RISC CPU instructions. The second is that decoding of these instructions has been increasingly optimized around only a few instructions that are commonly used by compilers, which makes the x86 ISA practically less complex than what the standard might suggest. The final change here has been that ARM and other RISC ISAs have gotten increasingly complex as well, as it became necessary to enable instructions that support floating point math, SIMD operations, CPU virtualization, and cryptography. As a result, the RISC/CISC distinction is mostly irrelevant when it comes to discussions of power efficiency and performance as microarchitecture is really the main factor at play now.








408 Comments
View All Comments
ghostbit - Friday, January 22, 2016 - link
I like iPads as thin clients.wolfemane - Friday, January 22, 2016 - link
The article was a great read and very thorough. Thank you Joshua Ho, Brandon Chester & Ryan Smith. I look forward to the next article!nrencoret - Saturday, January 23, 2016 - link
It seems cliché in Apple product reviews to mention bias, but this article fits the cliché quite well.The selective comparisons with other tablets are alarming. As others pointed out, no other product with a stylus has been thoroughly reviewed. A bare mention of the SP3 pen is all we get whilst all of the cons explored in the stylus section have no counterpoint as to how strong Surface tablets (and even Samsung devices) are at note taking (the exporting woes with the iPad come to mind). Even more troubling is the keyboard section where anyone who has decent tech knowledge knows how big of an improvement is the SP4 keyboard just to have it conveniently ignored in the conversation. The section is even worse when one considers the lack of angle adjustments, stability issues and cumbersome setup of the iPad keyboard are compared to the SP. Not to say a thing about the lack of mouse input which makes the whole desktop use uncomfortable. Finally the bland treatment given to the charge time of the tablet is inexcusable.
On the plus side, the SOC section is impeccable.
But the overall falling (as with all of Joshua's Apple writings) is a self-fulfilling prophecy: he likes the iPad and excuses or dismisses the the product's failings and conveniently never discusses what other products+software do better. Happy you like your iPad and you've written a good essay as to why its a good device for you, but this, a professional unbiased review its not.
10101010 - Saturday, January 23, 2016 - link
As a Note 8 and 12.2 owner, I can say the "exporting woes" of the iPad Pro are absolutely trivial in comparison. Samsung completely fumbled building a pen app ecosystem. This will not be the case with the iPad Pro.When it comes to the Surface Pro, we need to talk about how Windows is a broken platform and few developers want to write apps for it anymore. Even Microsoft's own developers don't like Windows anymore and are writing their latest software for other platforms using open source frameworks such as Electron.
Let's not forget to mention that the Surface Pro hardware, firmware, and drivers are so flaky that there is "SurfaceGate":
https://www.thurrott.com/mobile/microsoft-surface/...
And we also have the endless "whack-a-mole" adventure that is trying to maintain some semblance of data privacy/security with Windows 10 and its factory installed malware and forced updates.
One could on. You know, so things are more "professionally unbiased".
royalcrown - Sunday, January 31, 2016 - link
Thank you, for I am racing this on a Note 12.2 now. The S Pens have good hardware but their size sucks and the apps for them are too dumbed down or too many steps just to take simple notes.name99 - Saturday, January 23, 2016 - link
Hmm. For a team that is supposedly so blindly in love with Apple, they seem remarkably ignorant about how to actually DO things. For example, here's how you export those Pencil written notes:you install an iOS app called PrinterPro https://readdle.com/products/printerpro OR
https://itunes.apple.com/us/app/printer-pro-print-...
This installs a share sheet into iOS which allows you to "print" to a variety of real or virtual printers. One of these virtual printers is, of course, a PDF printer which just create a PDF file.
THIS sort of thing is why Apple folks get so irritated with Windows/Linux folks. You keep claiming that something or other cannot be done (on OSX or iOS) but 95% of the time your actual complaint is "I don't know how to do ... on OSX/iOS; therefore obviously it can't be done because I know everything in the universe about computing". There's more than one way to do things, folks, and just because the Windows way is some weird voodoo of "install a driver; go into some dialog that hasn't been updated since Windows 95; change three settings in the registry; now you can create PDFs" doesn't mean that iOS makes you do the same thing if you want to create PDFs.
Share sheets are the generic inter-app communication mechanism for iOS, and anyone who was actually familiar with the platform would immediately think that this was the sort of place to look to solve the problem.
As for Printer Pro being "unsupported". Well, my version is actually free because Apple liked the product so much they sponsored it being free on the app store for two weeks or so. I don't think they're likely to yank it from the store...
Should this be part of the OS? Well, plenty of thing should be part of every OS. How long did it take WINDOWS to get a Print to PDF option?...
My guess is that at some point it will be wrapped into the standard iOS bundle of features, but that right now Apple have higher priorities, and the third party solution works very well without the sorts of security, stability, or power concerns that might compel Apple to move other features into the base OS more rapidly.
royalcrown - Sunday, January 31, 2016 - link
True, but it'seems stupid in this day of very common WiFi printers that you can'take just install an app from the app store that is from the printer manufacturer that allows IOS to print directly (No Airprint nonsense). How a out the fact that it took until IOS 8 or 9 to attach a PDF to an email.I like both companies and use both, but this is the kind of stupid crap that apple does that gives haters a "Foot in the door". It's why I switched out my IPad 3 for a Note at the time.
bitbank - Saturday, January 23, 2016 - link
Small correction to your comparison of ARM to x86 ISA: you said "By comparison, the ARM ISA has no direct equivalent to this instruction. Any instruction like leal/leaq is going to take multiple instructions.". This is incorrect. ARM with its 3-operand instructions usually takes fewer instructions compared to Intel. In this case, there is a single instruction which is more powerful than the Intel equivalent -> ADD R1,R2,R3,LSL #2. This is effectively R1 = R2 + 4*R3. The barrel shifter and 3-operand instructions mean you can do more work than the Intel ISA allows. Individual ARM instructions are on average longer than Intel instructions, but you usually need fewer of them to accomplish the same task.JoshHo - Saturday, January 23, 2016 - link
Fiora Aeterna has also helpfully pointed this out. I've since updated the article to resolve this inaccuracy and use a (hopefully) better example.name99 - Sunday, January 24, 2016 - link
We can be more precise about this. Experiments have been done about the density of code and it is a fact that ARM-v8 is very slightly DENSER than x64 code. ARM-v7 was slightly less dense than 32-bit x86 code.The barrel shifter is not relevant to ARM-v8 (neither is predication). What is relevant is a very cleverly designed ISA that actually exploits what we've learned about usual code patterns over the past 30 years or so. So ARM has load and store register pair, or just enough predication-like instructions (CSEL and the concatenated branch conditions), or a way to distinguish between instructions that do and don't set branch conditions, or an encoding of literals that is, as matter of empirical reality, substantially denser than a flat encoding. All these make for a substantially denser ISA than the traditional load-store type ISA of something like MIPS or POWER.