The Snapdragon 865 Performance Preview: Setting the Stage for Flagship Android 2020
by Andrei Frumusanu on December 16, 2019 7:30 AM EST- Posted in
- Mobile
- Qualcomm
- Smartphones
- 5G
- Cortex A77
- Snapdragon 865
Machine Learning Inference Performance
AIMark 3
AIMark makes use of various vendor SDKs to implement the benchmarks. This means that the end-results really aren’t a proper apples-to-apples comparison, however it represents an approach that actually will be used by some vendors in their in-house applications or even some rare third-party app.
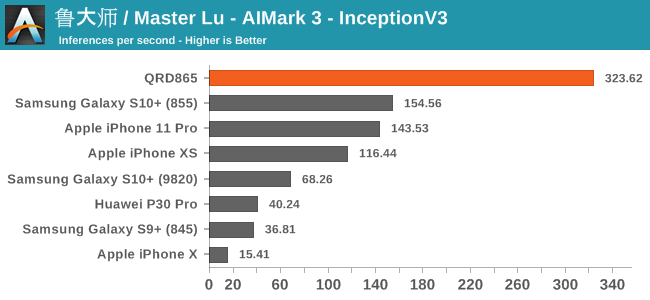
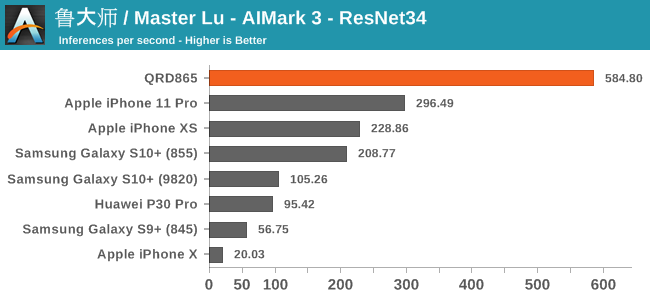
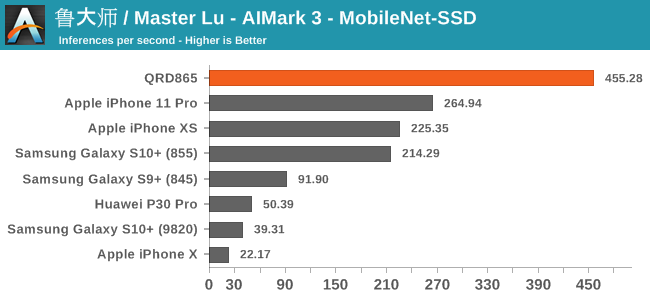
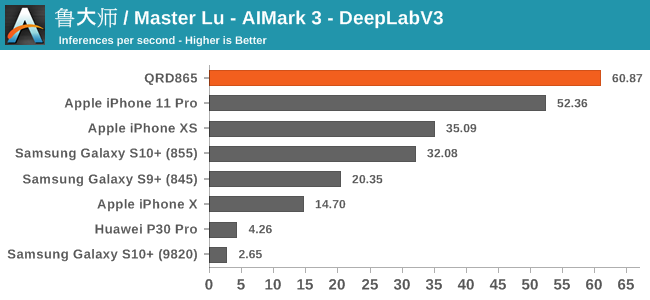
In AIMark 3, the benchmark uses each vendor’s proprietary SDK in order to accelerate the NN workloads most optimally. For Qualcomm’s devices, this means that seemingly the benchmark is also able to take advantage of the new Tensor cores. Here, the performance improvements of the new Snapdragon 865 chip is outstanding, posting in 2-3x performance compared to its predecessor.
AIBenchmark 3
AIBenchmark takes a different approach to benchmarking. Here the test uses the hardware agnostic NNAPI in order to accelerate inferencing, meaning it doesn’t use any proprietary aspects of a given hardware except for the drivers that actually enable the abstraction between software and hardware. This approach is more apples-to-apples, but also means that we can’t do cross-platform comparisons, like testing iPhones.
We’re publishing one-shot inference times. The difference here to sustained performance inference times is that these figures have more timing overhead on the part of the software stack from initialising the test to actually executing the computation.
AIBenchmark 3 - NNAPI CPU
We’re segregating the AIBenchmark scores by execution block, starting off with the regular CPU workloads that simply use TensorFlow libraries and do not attempt to run on specialized hardware blocks.
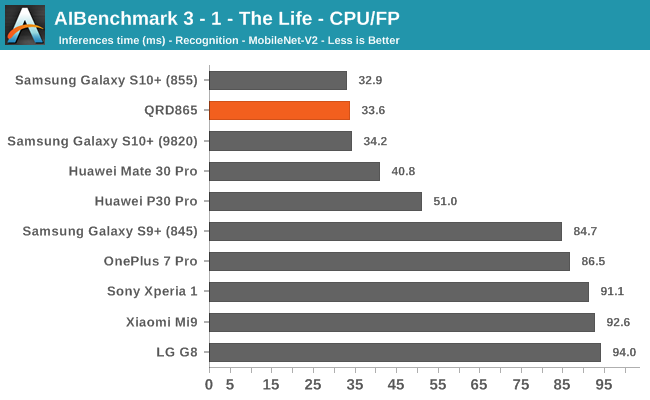
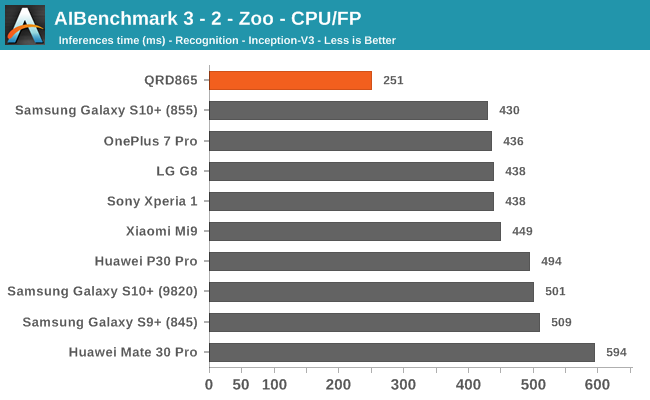
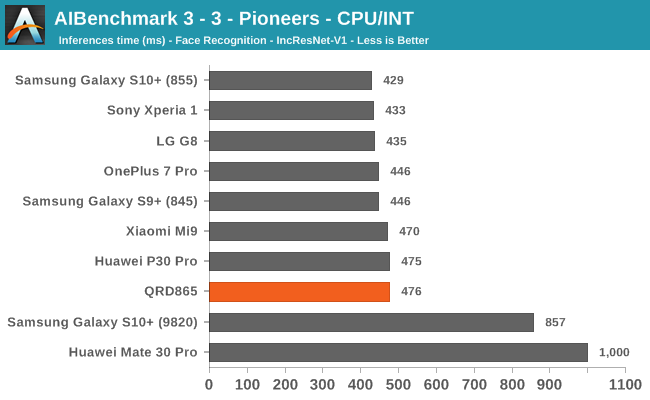
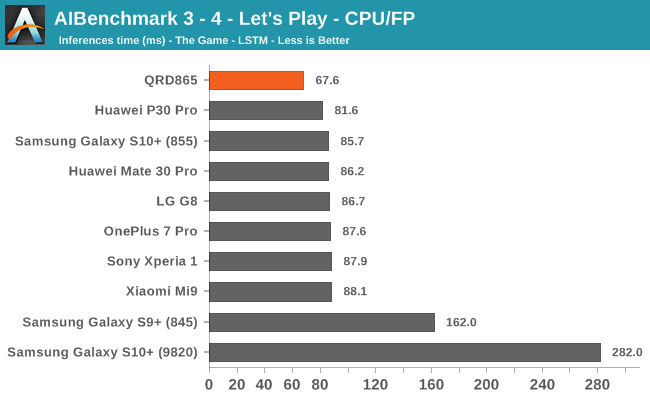
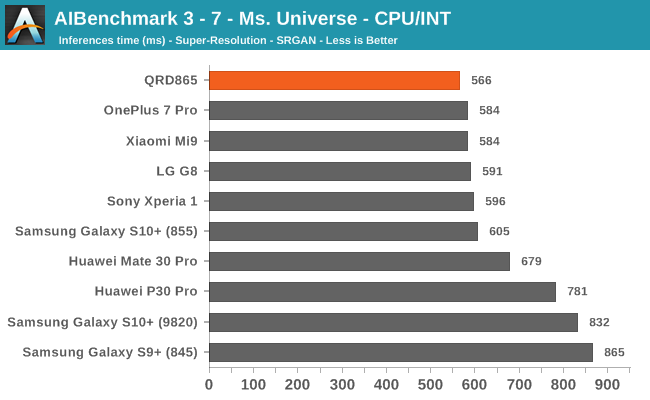

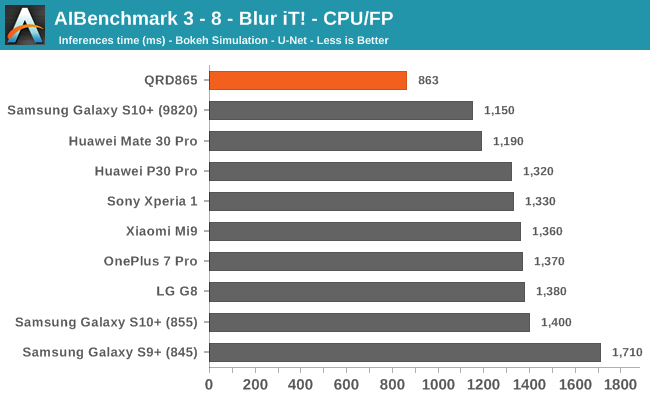
Starting off with the CPU accelerated benchmarks, we’re seeing some large improvements of the Snapdragon 865. It’s particularly the FP workloads that are seeing some big performance increases, and it seems these improvements are likely linked to the microarchitectural improvements of the A77.
AIBenchmark 3 - NNAPI INT8
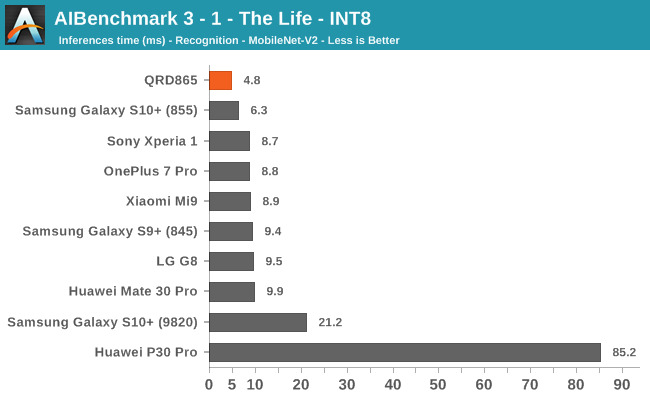
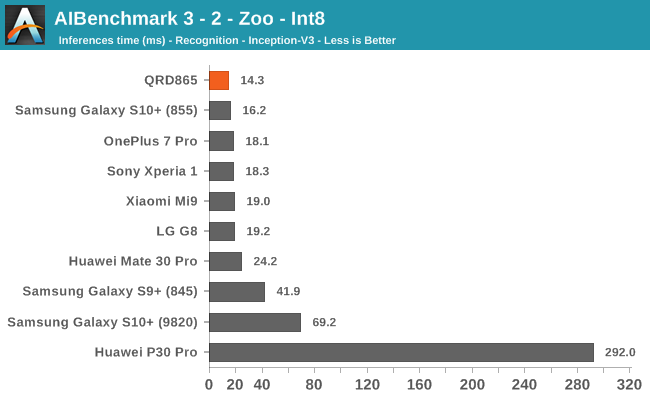
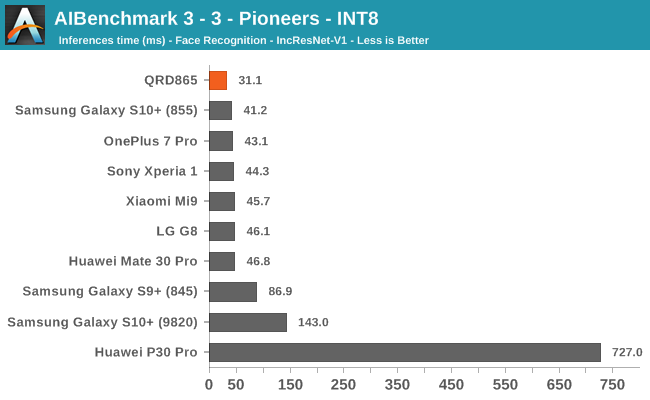
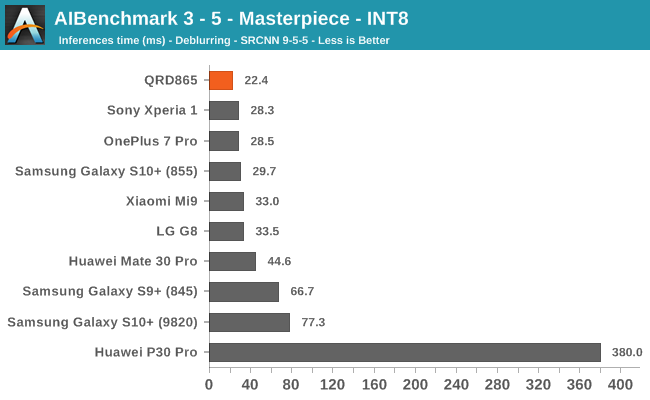
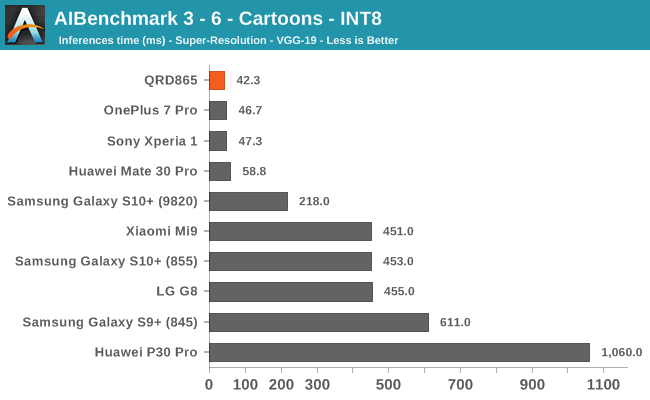
INT8 workload acceleration in AI Benchmark happens on the HVX cores of the DSP rather than the Tensor cores, for which the benchmark currently doesn’t have support for. The performance increases here are relatively in line with what we expect in terms of iterative clock frequency increases of the IP block.
AIBenchmark 3 - NNAPI FP16
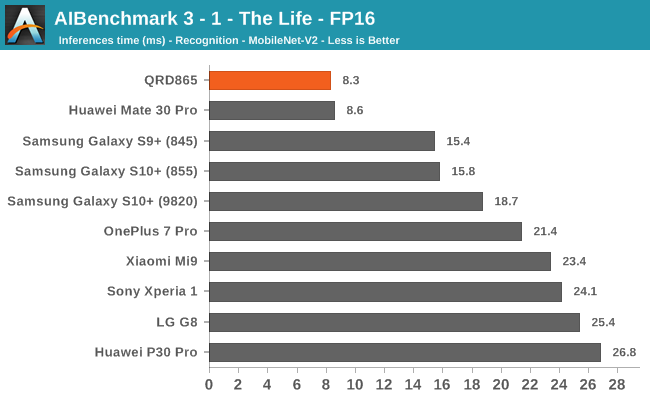
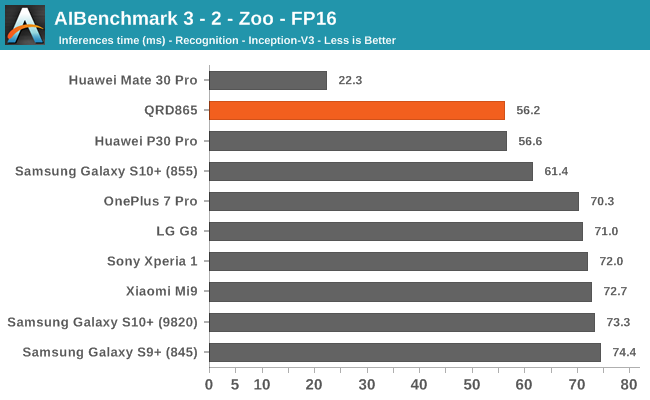
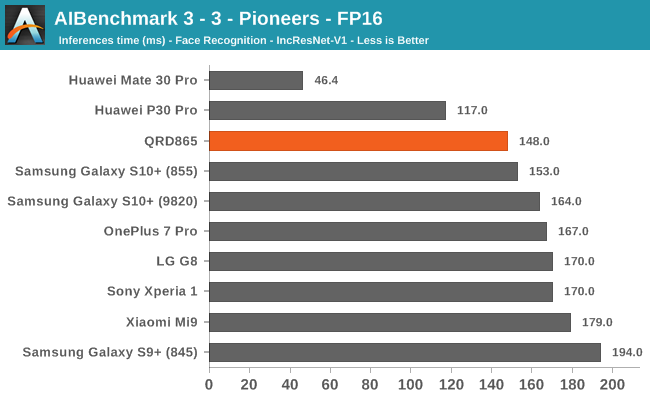
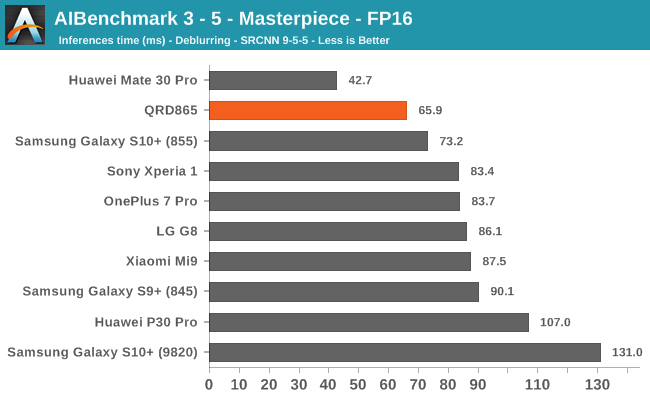
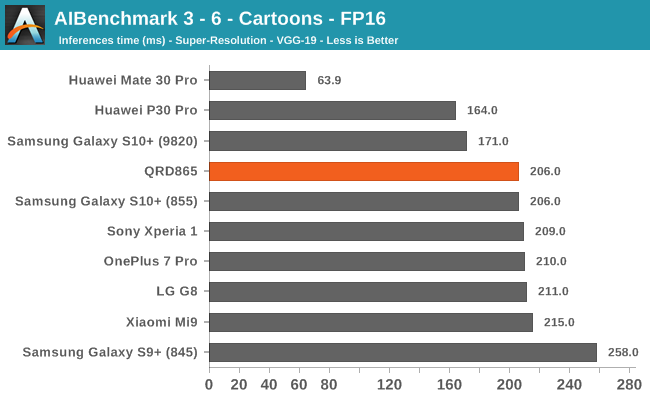
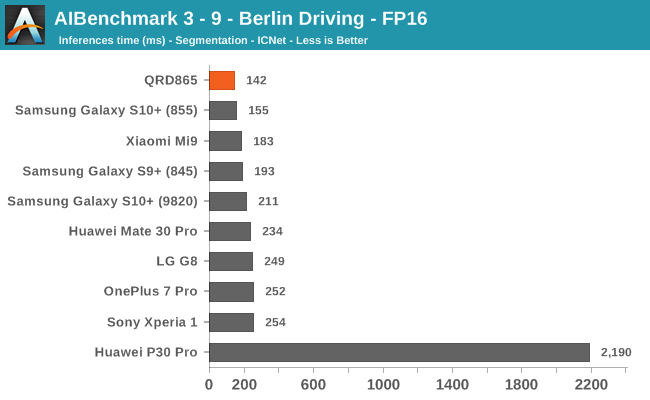
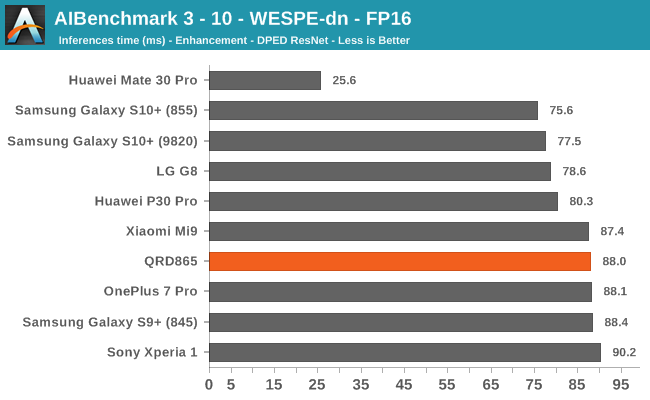
FP16 acceleration on the Snapdragon 865 through NNAPI is likely facilitated through the GPU, and we’re seeing iterative improvements in the scores. Huawei’s Mate 30 Pro is in the lead in the vast majority of the tests as it’s able to make use of its NPU which support FP16 acceleration, and its performance here is quite significantly ahead of the Qualcomm chipsets.
AIBenchmark 3 - NNAPI FP32
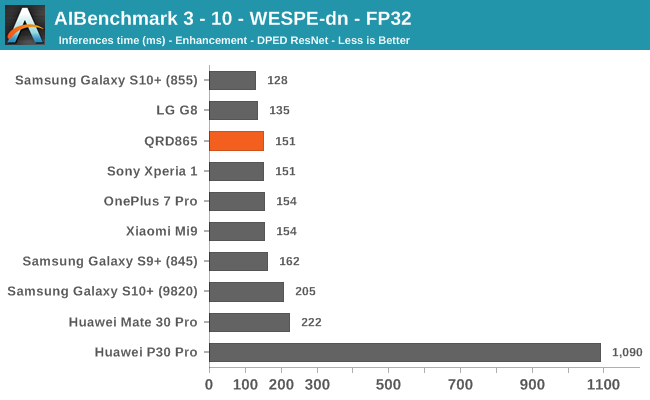
Finally, the FP32 test should be accelerated by the GPU. Oddly enough here the QRD865 doesn’t fare as well as some of the best S855 devices. It’s to be noted that the results here today were based on an early software stack for the S865 – it’s possible and even very likely that things will improve over the coming months, and the results will be different on commercial devices.
Overall, there’s again a conundrum for us in regards to AI benchmarks today, the tests need to be continuously developed in order to properly support the hardware. The test currently doesn’t make use of the Tensor cores of the Snapdragon 865, so it’s not able to showcase one of the biggest areas of improvement for the chipset. In that sense, benchmarks don’t really mean very much, and the true power of the chipset will only be exhibited by first-party applications such as the camera apps, of the upcoming Snapdragon 865 devices.








178 Comments
View All Comments
UglyFrank - Monday, December 16, 2019 - link
I imagine the Tab S7 will have this.Meanwhile the iPad Pro 2020 will most likely have more than double the GPU power.
Kishoreshack - Monday, December 16, 2019 - link
That's not how it works broUglyFrank - Monday, December 16, 2019 - link
It is. The A12X has more than double the S855's GPU performance and we can expect ~ 20% increase in GPU performance (A12X to A13X) as the A12 to A13 had a similar increase.generalako - Monday, December 16, 2019 - link
Ok, but then again the SD875 (or whatever it will be called) is expected to be on a new architecture after 3 generation, which generally means 50%+ jump just there. With the transition over to 5nm, you can expect even more performance from that. That would, after all, be the most fair comparison to the A14 (or A14X) on 5nm later this year, due to process node comparisons. Same with CPUs (don't forget, the A77 in the SD865 was released in the summer before by ARM, and even presented in the SD865 in December).close - Tuesday, December 17, 2019 - link
Over the past few years Apple has been doing a consistently better job than Qualcomm regardless of process node. Probably they can afford to since they are in full control of the whole technology stack, including the software which means they can squeeze additional performance and efficiency like that. But this doesn't change the fact that year after year A-chips are better than their counterparts.tuxRoller - Wednesday, December 18, 2019 - link
I'm not sure that apple is much, if at all, more optimized than the Android bsps. If you're aware of proof to the contrary I'd be interested in reading it.michael2k - Wednesday, December 18, 2019 - link
It doesn’t mean optimized the way you envision it. It means more tailored to the design, since Apple has a fixed number of systems it has to support. There are three ways to see it: how many years does Apple push iOS updates? That is a function of performance as well, as as the OS.Another way to see it is knowing that Apple ships iPhones with much less RAM, meaning their OS and apps have to be designed to use less RAM too.
Likewise their iPhone usually ships with smaller batteries; by designing the OS, SoC, and RAM synergistically they can use a smaller battery too. RAM happens to use energy even when idle, so less RAM does translate to lower energy usage.
michael2k - Tuesday, December 17, 2019 - link
Yeah, but anything Qualcomm does to boost performance, Apple will be doing too.The 865 is going to compete with the A14 in 2020, and the 875 will compete with the A15 in 2021. So if we expect the A14 to boost perf by 15% and the A14X to boost perf by 40%, and the A15 to boost perf again by 10% and A15X to boost perf again by 25%, you'll see:
855 = 1.00
865 = 1.25
875 = 1.50
A13 = 1
A13X = 1.4
A14 = 1.15
A14X = 1.96
A15 = 1.26
A15X = 2.45
Technically Qualcomm has more room to improve when you compare transistor budgets: the A13 is approximately 8.5b transistors, the A12 7b transistors.
In comparison, the 855 only had 6b transistors, per Qualcomm itself:
https://www.qualcomm.com/media/documents/files/sna...
id4andrei - Tuesday, December 17, 2019 - link
The 865 competes with A13 not with the future A14. Apple sets the cadence in the SoC space and have done so since breaking rank with sheer performance and transition to a 64bit arch.generalako - Tuesday, December 17, 2019 - link
This is just misrepresentative. The past two generations ARM's architecture has been closing the gap to Apple. It closed the gap by around 30% in IPC with A76, and doing so by around 15% in IPC with A77 (A77 had 27% IPC gain vs. A13's 12% IPC gain). The gap has been getting smaller, and hopefully it will continue. But the fact is still that it's closing for the performance cores.Also, you're comparisons are way off. The SD855 was comparable to the A12, just as the SD865 is to the A13, and so on and so forth. This with process node and the actual release date of the Cortex Core in mind.