MIPS Strikes Back: 64-bit Warrior I6400 Arrives
by Stephen Barrett on September 2, 2014 10:00 AM ESTThe MIPS I6400 CPU
Like the Cortex-A53, the I6400 is an in-order, dual-issue design. Each processor supports IEEE 754-2008 floating point operations, 128-bit SIMD instructions, and hardware virtualization. ARM has previously stated that Cortex-A9 is roughly 2.5 mm2 of area with a 40 nm process, and Cortex-A53 is 40% smaller at the same process, placing it at roughly 1.5 mm2 of area. At 28nm, we can estimate a Cortex-A53 is about 1mm2. Comparatively, MIPS states the I6400 is 1mm2 on the TSMC 28nm HPM process in "worst-case scenarios". Therefore the designs are quite comparable.

Differences between the Cortex-A53 and I6400 start with a 9 stage pipeline in the I6400 vs 8 stages with the A53, theoretically allowing the I6400 to clock higher. However the I6400 is 9 stages for all operations, whereas the A53 is 8 stages for integer but 10 for NEON/Floating Point operations.
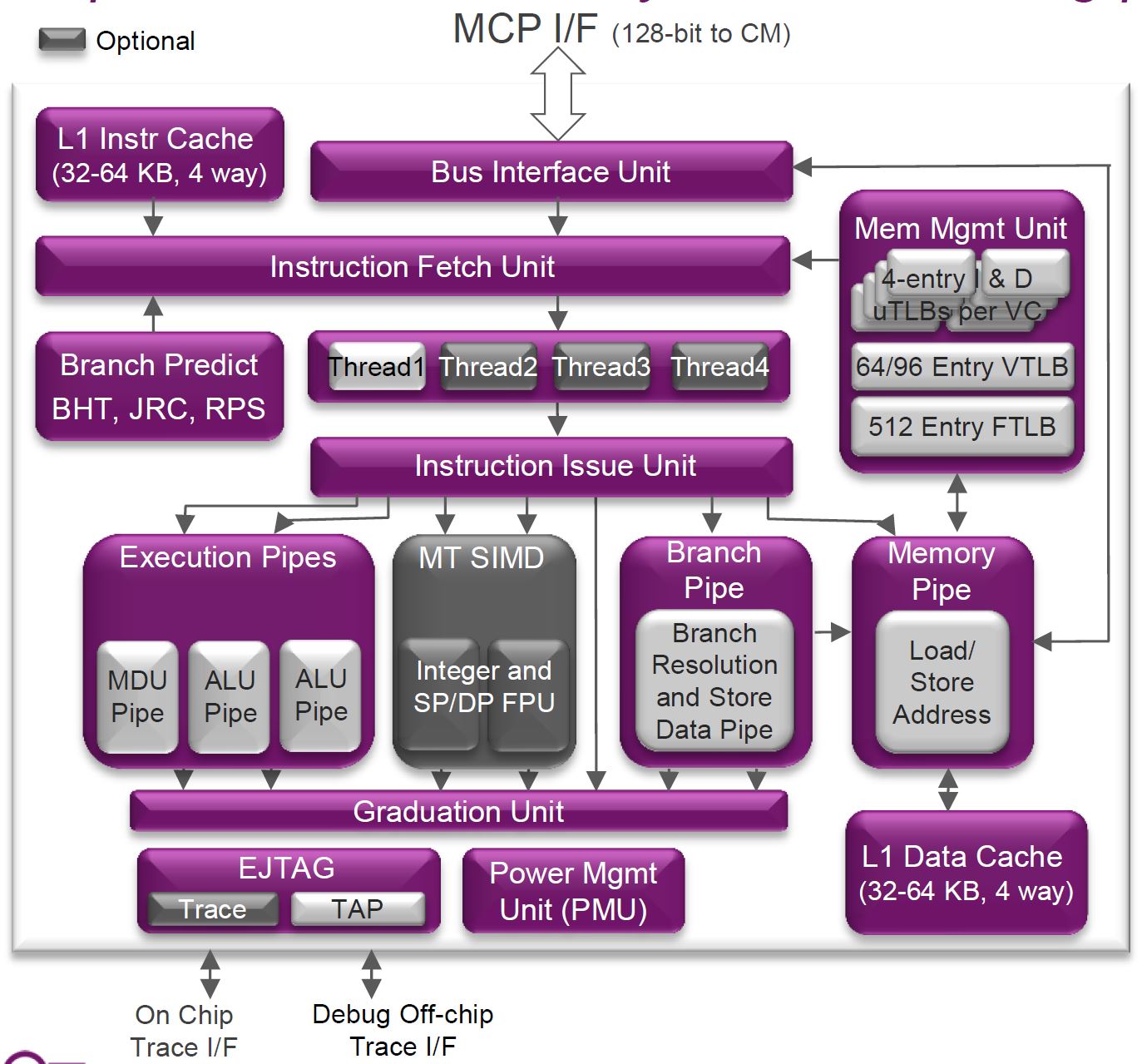
If you look closely at the block diagram you can see one of the I6400’s interesting tricks: Simultaneous Multi-Threading (SMT). Avid readers of AnandTech should recognize this technology immediately. It has been utilized by Intel since the venerable Pentium 4, over a decade ago in 2002, under the trademarked name Hyper-Threading. While the Core Duo and Core 2 lines dropped support for Hyper-Threading, the Nehalem (Core i7) and later processors have continued its use. IBM's POWER cores also support SMT (up to 4-way SMT with POWER7 and 8-way SMT with POWER8).
Strangely, we have not seen anyone else (e.g. ARM or AMD) implement this same technology until now. AMD has a partial implementation in its Bulldozer architecture, with each "module" in their current CPUs/APUs providing two full integer cores with some shared elements. AMD contends that their partial SMT implementation is actually better for some workloads, but that's a different discussion. Regardless, SMT support it is new to the small-core space.
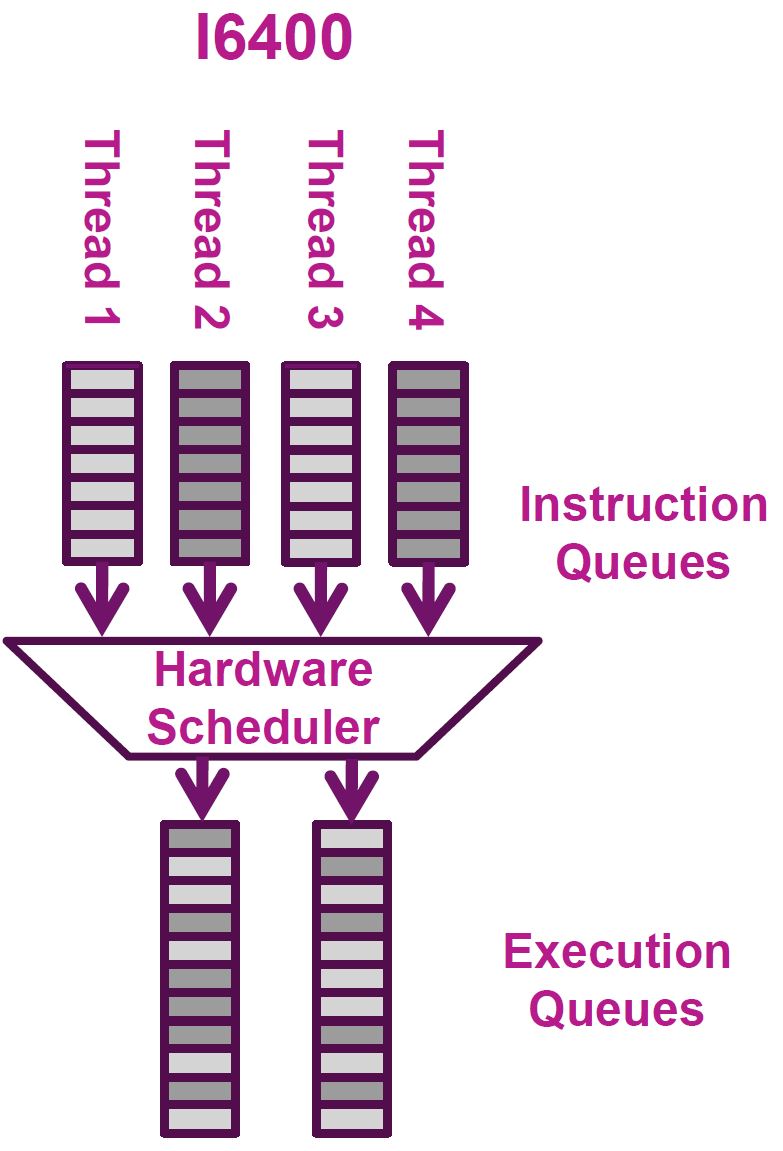
An SoC designer licensing an I6400 core can decide how many threads of SMT they want to implement into the core, from 1 to 4. The physical core then advertises itself to the operating system as 1 to 4 logical cores, thus allowing the OS to send up to four threads of instructions to execute at any given time. The hardware’s execution scheduler can then, per cycle, dynamically switch between threads depending on which hardware resources are available. For example, if the integer ALUs are tied up with threads 1-3 but thread 4 only needs floating point resources, the scheduler can schedule thread 4 to the FP units instead of waiting around.
Imagination claims their MIPS core featuring SMT only increases 10% in size but increases an incredible 30% to 50% in performance. A 3x to 5x size to performance ratio for any given feature is quite hard to come by. If Imagination’s claims are correct, it’s a wonder this feature is optional. Certain applications greatly suffer from SMT, namely real-time applications that depend on determinism, but like Intel Hyper-Threading, I would hope there is a simple software setting to disable this feature when it is not desired. Imagination specifically calls out networking applications (which are very throughput focused) as greatly benefiting from SMT, which is the optional MIPS MT extension.
Even though the core is in-order, the I6400 performs superscalar execution for a given thread. Since it is dual dispatch, two instructions from a single thread can be executed in parallel. I would imagine the superscalar execution is limited to the next two instructions within a thread (as there is no reorder buffer); otherwise the entire core wouldn’t be listed as in-order.
| Mid-Class CPU Core Comparison | ||||||
| MIPS I6400 | ARM Cortex-A53 | |||||
| CPU Codename | Warrior | Apollo | ||||
| ISA | MIPS3264 Release 6 | ARMv8-A (32/64-bit) | ||||
| Cores in an SMP Cluster | 1-6 | 1-4 | ||||
| Thread Width | 1-4 | 1 | ||||
| Issue Width | 2 micro-ops | 2 micro-ops | ||||
| Reorder Buffer Size | None: In-Order | None: In-Order | ||||
| Pipeline Depth (stages) | 9 | 8 (Int) 10 (FP) | ||||
| Integer ALUs | 2 | 2 | ||||
| Load/Store Units | 1 (2 with bonding) | 1 | ||||
| Load Latency | 3 cycles | 3 cycles | ||||
| Branch Units | 1 | 1 | ||||
| FP/NEON ALUs | 2 | 2 | ||||
| Coherency | Directory | Snoop + Filter | ||||
| L1 Cache | 32 or 64KB I$ + 32 or 64KB D$ | 8 to 64KB I$ + 8 to 64KB D$ | ||||
| L2 Cache | 0.5 to 8MB | 0.5 to 2MB | ||||
Another trick the I6400 employs is called instruction bonding or load/store bonding, which probably ties in with the previously mentioned hardware scheduler. If two load or store instructions arrive at the scheduler with adjacent addresses, the I6400 can "bond" them together into a single instruction executed by the load/store unit. Two 32-bit integer accesses will be bonded into a single 64-bit integer access, two 64-bit integer accesses bond into a single 128-bit integer access, and two 64-bit floating point accesses bond into a single 128-bit FP access.
Applications often perform memcopies that move relatively large amounts of memory from point A to point B, resulting in a long list of load/store instructions. This hardware scheduler feature can halve the time required to fulfill a memcopy request and is completely transparent to software. MIPS states this feature is a natural expansion of their load/store unit, as their bus widths are already 128-bits to support their SIMD unit. Doubling the efficiency of the I6400's single load/store unit (in certain cases) helps save area and power compared to duplicating the unit entirely.
Directory Based Coherency
One of the largest problems a multicore processor needs to solve is coherency. Multiple PhDs have been earned on this topic alone. The core of the problem (pun intended) is that multiple execution resources (CPU or GPU cores) exist each with their own L1 data cache. If Core1 writes to address 0xABC0FF, its L1 data cache is immediately updated. However, what if there is another core present that also has the data at address 0xABC0FF cached? Its cached data is now invalid and, if used, results in computational inconsistency and a potentially critical application errors.
There are multiple techniques to deal with this problem. The most common is called snooping. Each core in a multicore system monitors the L1 cache lines of every other core. If a write is observed to an address that is locally cached, that cache line is immediately invalidated. When an invalidated cache line is accessed, the invalid data is not returned but rather a longer trip out to the coherent L2 cache is made. Since all the L1 caches update whenever any L1 cache is written to, this is the most performant coherency implementation. However, it is quite complex. If eight cores are designed with coherent L1 caches, each core must connect to seven other cores, causing an explosion of complexity.
One way modern designs deal with increasing snoop complexity is by using a "snoop bus". Instead of connecting all cores L1 caches to each other, all cores are connected all to a shared bus. When a core writes to an L1 cache location, it broadcasts the address written to all other cores on the snoop bus. Other cores then invalidate that address if it is present in their L1 cache. This helps with wiring inside the chip, but snoop traffic is still increasing with added cores. ARM's A53 goes a step further and has a Snoop Control Unit (SCU) that sits on the bus and filters out snoop traffic based upon which caches have which addresses.
The I6400 uses the other common technique, directory based coherency. The L2 cache in the I6400 maintains a listing of all the data being duplicated in attached CPU cores. When an address is changed, the directory is always notified. The directory can then update the attached CPU cores that have duplicated that data. In the worst-case scenario this is both higher latency (informing the directory of a write takes time) and can result in increased bus traffic because every core could have cached a particular address. However, it’s not likely that every single core would have cached the same data that gets overwritten. Either way, it is significantly simpler to implement as it is a single point to point connection between L1 and L2 per core rather than a web of connections between L1s. This is likely a contributing factor in why the I6400 can be used in SMP clusters of 6, whereas the A53 is limited to SMP clusters of 4.

Finally, the I6400 includes fine grained power consumption optimizations branded as “PowerGearing” by MIPS. The processor can disable clocks (clock gating) to individual CPU cores, caches, and subsystems (such as SIMD blocks). Each CPU core can individually sleep and be controlled by OS Dynamic Voltage and Frequency Scaling (DVFS), which is essential to Android/Linux processor power management.








84 Comments
View All Comments
Flunk - Tuesday, September 2, 2014 - link
Competition is always good, it will be interesting to see how these perform in real devices. The performance/power consumption offered by modern ARM processors is difficult to compete with.alexvoica - Tuesday, September 2, 2014 - link
I6400 offers better performance at lower power and reduced area vs. the competition. I have included some benchmarks in my article http://blog.imgtec.com/mips-processors/meet-mips-i...name99 - Tuesday, September 2, 2014 - link
I'm sorry but that article appears to be marketing crap.You state "Preliminary results for I6400 show that adding a second thread leads to performance increases of 40-50% on SPECint or CoreMark". So adding a second thread speeds up the SINGLE-THREADED version of SPEC? That's a neat trick.
Likewise you happily claim that multi-threading make a "big difference" to web browsing, something that will come as news to the many engineers on the WebKit, Blink and IE teams who have sweated blood over this without much to show for their efforts.
On your blog you can post whatever marketing fluff you like, but how about on AnandTech you limit yourself to actual numbers of real benchmarks?
(Sorry to be cruel but, christ, throwing raw ads into the comment stream and pretending they're informed comment pisses me off no end.)
alexvoica - Tuesday, September 2, 2014 - link
I might not be as versed as you are and excused me if I'm wrong (someone correct me if I am) but, as far as I know, SPEC supports multi-threading. Multi-threading really does improve performance - but don't take it from me, take it from our customers who are already using it in both 32- and 64-bit MIPS-based designs: Broadcom, Cavium, Lantiq - I could go on.I don't really understand how you can claim that my article is marketing fluff. It is marketing, yes. But doesn't every company have an official release? And doesn't part of that release include competitive positioning?
Let's not be behind-the-screen aggressive for behind-the-screen aggressiveness's sake. We have already offered a lot more information than our competitors, including benchmark data in CoreMark, DMIPS and SPECint.
name99 - Tuesday, September 2, 2014 - link
"We have already offered a lot more information than our competitors, including benchmark data in CoreMark, DMIPS and SPECint."Then why is the post full of claims, and basically numberless graphs, but not actual tables of numbers? Ooh, we're 1.3x faster than "competing CPU" --- that's helpful.
There's more information available in any AnandTech phone review.
Say what you like about nVidia, at least their HotChips Denver marketing slide gave numbers of a sort for Denver, compared to Baytrail, Krait-400, iPhone 5S and Haswell, all for a range of benchmarks (DMIPS, SPECInt2K and SPECFP2K, AnTuTu, Geekbench, Google Octane and some memory benchmarks). I think they were wrong to omit (definitely) SunSpider and (I care less) Kraken because SunSpider in particular gives a good feel for single-threaded performance on a large real-world code base. (SPECInt2K is a reasonable proxy, but stresses the uncore more than is probably usual for mobile devices.) Octane (and Kraken) are less interesting IMHO because they synthesize a workload that is vastly more parallelized than most actual websites.
(Of course I'd expect you to do better than nVidia, especially since you're the new kid on the block.
That means, for example, real numbers not scaled percentages;
it means running the benchmarks honestly --- using the optimal compiler plus flags for each device;
it means telling the public what those flags were so they can reproduce if necessary;
it means not playing games with cooling systems that aren't going to be used on a real device, or an OS power driver that does not match what will ship in real devices;
and it means using appropriate best of breed devices --- eg it's a bit slimy to use an iPhone 5S [1.3GHz] rather than iPad Air [1.4GHz] unless you have some damn good reason (like you're comparing against the phone version of your chip, not the tablet version.)
The code to be compiled to perform the SPECInt bechmark runs is not threaded. Sure, if your compiler is smart enough to auto-parallelize that code, it can go right ahead. Since no-one else's compiler has managed to achieve much by doing that, I kinda doubt MIPS has made a breakthrough here...
Multi-threading improves performance IF YOUR CODEBASE IS THREADED. My point is that the market that's being implied here (phones, tablets) is NOT substantially threaded.
There absolutely are markets (in many of which MIPS already does well, things like networking or cellular) where threading is important and of benefit. That doesn't change the fact that phones and tablets are not such a market, and pretending otherwise is not helpful to anyone.
alexvoica - Tuesday, September 2, 2014 - link
This is where you are wrong, no matter how much your finger gets stuck on caps lock. Programming for multithreading is not radically different than programming for multicore. In fact, Linux-SMP operating systems (e.g. Android) will see a dual-threaded CPU as two physical cores.Regarding your comments about benchmarks, I invite you to show me real, concrete numbers from our CPU IP competitor. We have said 5.6 CoreMark and 3.0 DMIPS per MHz. Now show me the data - and I am not interested in semiconductor manufacturers who are not our competitors but IP vendors.
The comparisons were made based on similar core configurations to ensure accuracy; how would you be able to reproduce them - are you an ARM licensee?
Wilco1 - Tuesday, September 2, 2014 - link
You've showed some numbers but not explained how they were made. As I said in my other post, MIPS uses a trick to get its CoreMark score, so any competitor result without the same trick will obviously look bad.And this is the issue with benchmarketing, unless it is possible to reproduce the score yourself, it is hard to believe any vendor-supplied scores.
name99 - Tuesday, September 2, 2014 - link
(a) Thanks for explaining SMT to stupid old me who's been in a coma for the past fifteen years and has never heard of the concept. Not sure WTF it has to do with my actual point about the dearth of threaded APPLICATIONS...(b) I'm not the guy trying to sell a CPU to the rest of the world, so I'm not sure why it's my job to provide numbers, but OK, here we go.
iPhone 5S at 1.3GHz gets a geekbench-singlecore rating of about 1300, and a sunspider rating (with iOS7) of 416. What do you have as closest equivalent numbers?
DMIPS --- give me a break. No-one cares about that because it tells you precisely nothing about anything hard that the CPU does. Coremark's slightly more interesting, but why don't you give some comparable CoreMark/MHz values so we can see what you consider to be your competitors.
I see, for example, that Exynos quad A9 claims a value of 15.89 and a dual-core A15 claims 9.36. Would you consider those competitors?
(As comparison, a single core A53 (at least the QC Snapdragon 410 variant) gets 3.7 according to AnandTech --- but 3.0 according to other sources so??? A57 is supposed to get 3.9, but who knows how trustworthy that number is.)
Assuming your 5.6 number is for multi-threaded operation, I'm going to do the naive thing and say that that tells me the single-threaded value is 2.8, which is apparently worse than an A53. If you don't like that arithmetic, then give us the single-threaded benchmark numbers, rather than trying to persuade us that phones are a great example of user-level multi-threaded software.
alexvoica - Wednesday, September 3, 2014 - link
Please understand that CoreMark does not work like that for multi-threading vs multicore.If you look at their website https://www.eembc.org/coremark/
PThreads refer to performance for both cores and/or threads - they do not specifically say which is which.
ARM scores are for multicore versions - this is why the CoreMark per MHz per core number is obtained by dividing that number by the number of PThreads. For example, for one Cortex-A15 you have 9.36 / 2 = 4.68 CoreMark/MHz. A single core proAptiv - which is a single-threaded design too - offers 5.1 CoreMark/MHz.
The number we've quoted for I6400 is 5.6 CoreMark/MHz. For multithreading however, you do not divide by number of threads since these are not individual CPUs but threads part of a single core. The score for a single core, single threaded I6400 is not half of 5.6. We specify very clearly in the press release/blog article that adding another thread improves performance by 40-50%, so your numbers are incorrect.
I still don't understand why you are pushing your agenda so aggressively and jump to conclusions since the data is clear. The author of the article chose to quote DMIPS, but I believe we have presented a valid combination of benchmarks and scenarios. Again, we are not competing with silicon manufacturers - some of them are licensees - but with other IP vendors.
Wilco1 - Wednesday, September 3, 2014 - link
I don't agree Dhrystone and CoreMark are valid benchmarks for CPU comparisons - both are easily cheated. You claim some great results but you know very well these are not indicative of actual CPU performance. Both benchmarks use special compiler tricks (like I mentioned in other posts) that only speedup these benchmarks, but nothing else. I bet SPEC scores are not nearly as good.Once again eg. NVidia actually posted real scores for lots of benchmarks of their SoCs, including SPEC. Do the same rather than playing these benchmarketing games and you'll gain a lot more credibility.