Intel Xe-HP Graphics: Early Samples Offer 42+ TFLOPs of FP32 Performance
by Dr. Ian Cutress on August 21, 2020 11:00 AM EST- Posted in
- GPUs
- Intel
- Enterprise
- Intel Arch Day 2020
- XeHP

One of the promises that Intel has made with its new Xe GPU family is that in its various forms it will cater to uses ranging from integrated graphics all the way up to the high performance compute models needed for super-dense supercomputers. This means support for the types of calculations involved in simple graphics, complex graphics, ray tracing, AI inference, AI training, and the compute that goes into molecular modelling, oil-and-gas, nuclear reactors, rockets, nuclear rockets, and all the other big questions where more compute offers more capabilities. Sitting near the top of Intel’s offerings is the Xe-HP architecture, designed to offer high performance GPUs for standard server and enterprise deployments.
Over the past couple of weeks Intel has offered some of the first technical details of Xe-HP, following Raja Koduri showing it off across his social media profiles. We know that it is designed to be a modular architecture, with different chiplets connected together using Intel’s Embedded Multi-Die Interconnect Bridge technology. We also know, due to disclosures made at Intel’s Architecture Day, that it is set to be built on Intel’s 10nm Enhanced SuperFin (10ESF, formerly 10++, formerly 10+++) manufacturing process, which we believe to be a late 2021 process. Raja Koduri promised during the Architecture Day presentation that Xe-HP (and Xe-HPG) will be available in 2021.

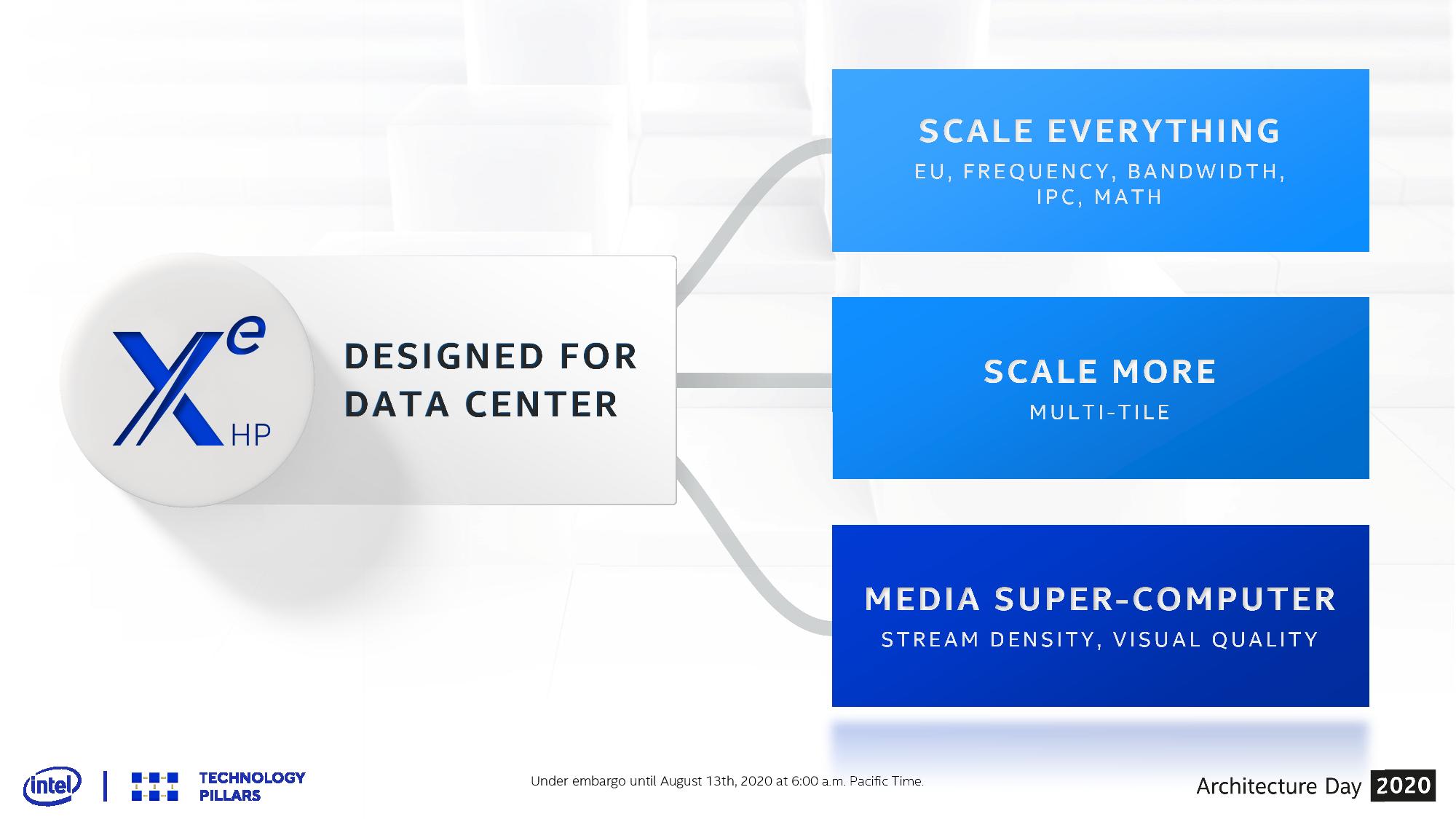
Intel explained that the modular Xe-HP design will scale from one to four tiles, and the concept of Xe-HP was to ‘scale everything’, such as execution units, frequency, bandwidth, IPC, and math capabilities. We assume that each tile will have direct access to some on-chip memory as well – truly scaling up every aspect of a chip – although how the chip's HBM2E is allocated hasn't been confirmed. The point of the product is that it is designed for the data-center, so there needs to be a mix of media compute as well as raw compute, covering all sorts of uses cases.

As part of the demonstration during Architecture Day, Intel also showcased that they’ve been running some benchmarks on the early silicon in the labs. By early silicon, we mean that these aren’t running at the final frequencies, this isn’t final firmware, and the software stack still has a way to go, so undoubtedly there are optimizations at every level.

First, Intel showed that a single tile of Xe-HP can not only transcode one 4K60 video in real time, but ten. In the demonstration they had the FFmpeg output, showing that the demo was converting each video from 5332 kb/s overall down to 3000 kb/s average (6000 kb/s max).
For compute, Intel offered the following performance numbers, given as peak GFLOPs of FP32 math using the OpenCL-based CLPeak benchmark.
- One Tile: 10588 GFLOPs (10.6 TF) of FP32
- Two Tile: 21161 GFLOPs (21.2 TF) of FP32 (1.999x)
- Four Tile: 42277 GFLOPs (42.3 TF) of FP32 (3.993x)
We also get some additional information from the video of Xe-HP. The tests were done on Linux, and actually all done on a version of the quad-tile chip, but made to run in 1T/2T/4T modes. This is why when looking at the video we can see all three versions are running at 1300 MHz. The string used for the chip is ‘XeHP HD Graphics NEO’ as well.
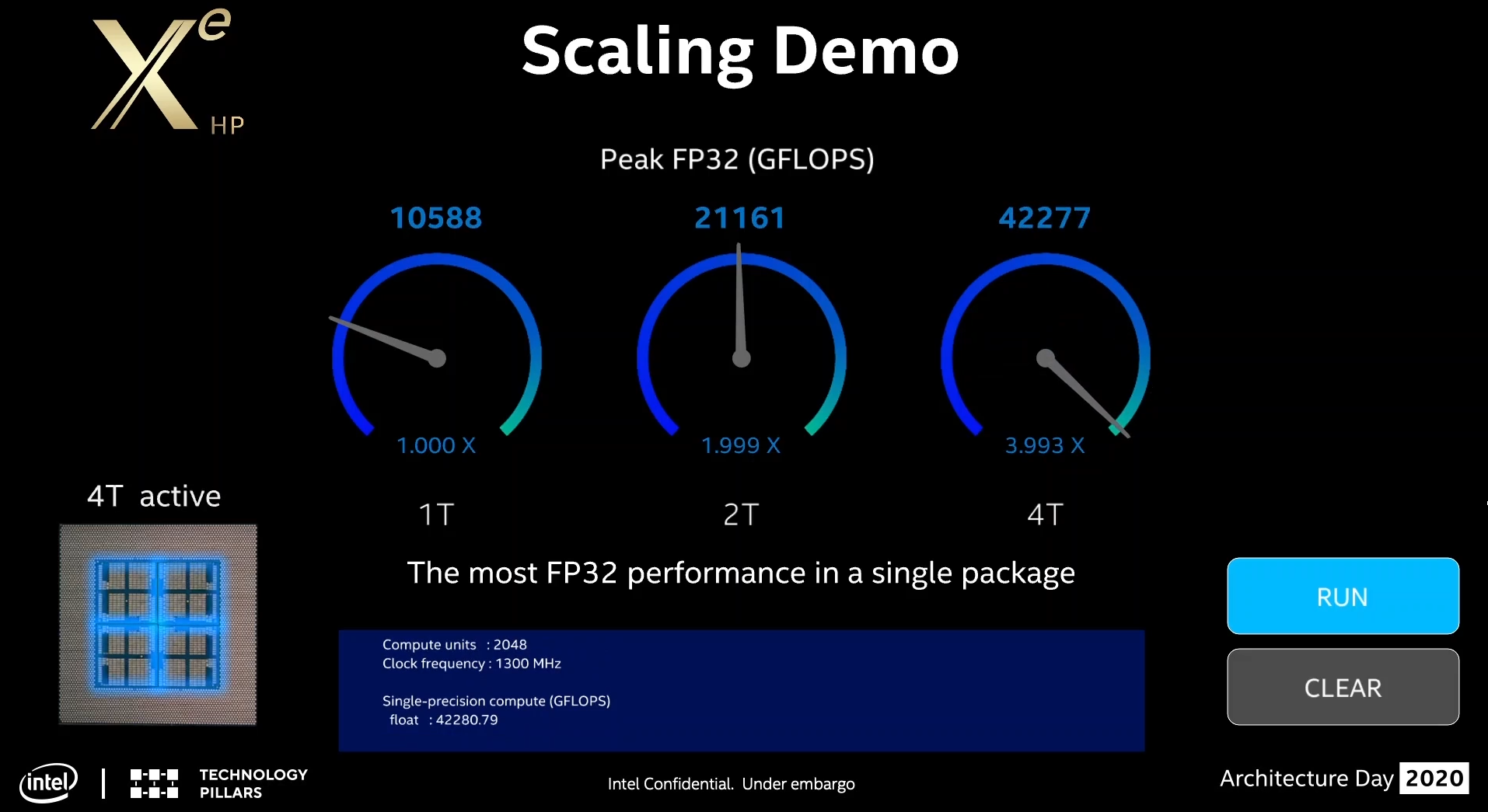
The video also shows that a single tile has 512 ‘compute units’, while the dual tile has 1024 compute units and the quad-tile has 2048 compute units. And while Intel hasn't officially claried what "compute units" mean in this context, the performance figures all but confirm that it's counting Intel's Execution Units. Based on the given GFLOPs, the stated clock speed, and the Xe architecture's 8 pipes per Execution unit with dual FMAs, Intel's performance figures map to 512/1024/2048 EUs respectively. That would mean that each one would have:
- One Tile: 512 EUs = 4096 ALUs (+ 1024 Extended Math ALUs)
- Two Tile: 1024 EUs = 8196 ALUs (+ 2048 Extended Math ALUs)
- Four Tiles: 2048 EUs = 16384 ALUs (+ 4096 Extended Math ALUs)
This is assuming that the Execution Unit structure of 8+2 from Xe-LP remains. We know that HP will support new XMX instructions for matrix math, as well as AI-related quantization levels and FP64 too. Which Intel's Hot Chips presentation has confirmed will be implemented within the EUs as additional physical blocks.



There was also a shot of the rear of an Xe-HP die, which Raja has shown off during his Hot Chips keynote as well. We can play a game of count the pins.

Intel Xe-HP 4-Tile Rear
Intel believes it is achieving near linear scaling in compute performance across its multi-tile strategy – at least up to 4T using CLPeak, a benchmark designed to measure a GPU's maximum compute throughput. There’s nothing here to say about tile-to-tile bandwidth scaling, or if this multi-tiling strategy and NUMA arrangement of tiles has knock-on effects for memory-limited or sparse math – Intel’s goal was simply to show that the hardware is running and what kind of peak compute performance it can offer. There’s also no word on power consumption either, or cost, however in the presentation Intel says that the goal here is to offer the equivalent of a rack-scale transcoding system in a single chip with best-in-class TCO, winning on performance-per-watt-per-dollar.
Xe-HP is set to be available in 2021 for the Enterprise market.
Related Reading
- The Intel Xe-LP GPU Architecture Deep Dive: Building Up The Next Generation
- Intel’s Xe-HPG GPU Unveiled: Built for Enthusiast Gamers, Built at a Third-Party Fab
- Intel Xe-HPC GPU Status Update: 4 Process Nodes Make 1 Accelerator
- Spotted At Hot Chips: Quad Tile Intel Xe-HP GPU
- Hot Chips 2020 Live Blog: Intel's Xe GPU Architecture (5:30pm PT)








41 Comments
View All Comments
Everett F Sargent - Friday, August 21, 2020 - link
Four Tile: 42277 GFLOPs (42.3 TF) of FP32 (3.993x)https://developer.nvidia.com/blog/nvidia-ampere-ar...
So ~2X of the nVidia A100.
Now all we need to know are the die/card size, temperature, power requirements, price and apples-to-apples comparisons to nVidia next generation enterprise GPU. What else was I expecting but incomplete reporting of unicorn hardware and the proverbial; "take these numbers with a grain of salt" NOT that these are pre-production numbers so that we'll assume to infinity and beyond for the final hardware.
Oh and for anandtech to stop being a 247 shill for intel.
shabby - Friday, August 21, 2020 - link
By the time the 10nm process is mature Nvidia will be on the next architecture.TimSyd - Friday, August 21, 2020 - link
Yup. What a yawn-fest.If it was available NOW that would be something to discuss. But this is nothing that AMD & NVIDIA cannot equal in the Ampere & RDNA 2 generations which will *ship* in the next few months (1T & 2T solutions, 4T equivalent would be multi-GPU).
By the time Intel fixes their process or migrates the IP to TSMC both NVIDIA & AMD will be on next gen, chiplet architectures, likely 5nm, with performance that will beat this with ease.
As someone else said - Intel is shrieking loudly about unicorn hardware running at undisclosed power levels with unverified benchmarks because they have NOTHING they can ship or even sample that is competitive.
What a sad state of affairs for a company with some great engineering talent.
Also sad that AT is broadcasting this propaganda with little to no comment pointing out the gaping holes in Intel's presentations & roadmaps.
Santoval - Friday, August 21, 2020 - link
"As someone else said - Intel is shrieking loudly about unicorn hardware running at undisclosed power levels with unverified benchmarks because they have NOTHING they can ship or even sample that is competitive."That's precisely what Intel have been doing for many years now, first for their 10nm fabbed CPUs and now for their GPUs.
MojArch - Friday, August 21, 2020 - link
RDNA 2? I wouldn't count on that one too much cause as long as i can remember AMD wanted to bring THE BIG GPU which they predictably failed!Ampere? well it is no currently at Xe league but next gen NVIDIA GPU might be who knows!
Also a small note: intel 10nm is actually on par with TSMC 7nm and intel's 7nm would be on par with TSMC 5nm so the only thing AMD/NVIDIA or TSMC actually would have is smaller naming scheme nothing else!
Spunjji - Monday, August 24, 2020 - link
@MojArch - so many citations needed. Intel's 10nm is *about to be on a par* with TSMC 7nm - it hasn't been up until now, as it's not lived up to Intel's original specifications. 10++ (or 10SF as it's now known) is getting them to that point.As for RDNA 2 vs this, it's worth bearing in mind that from Tiger Lake projections, Xe gets Intel to a position of needing significantly more area to beat *Vega* in terms of power and performance. Scaling that up, they're either going to pay a die-size penalty or a power penalty to beat RDNA 2.
Projecting from Turing, Ampere is likely to be *way* outside of Xe's League on a pound-for-pound basis.
Santoval - Friday, August 21, 2020 - link
Ampere is the last monolithic Nvidia GPU. From its successor (Hopper) onward they are also switching to chiplets (or at least that's the current plan; it's possible that the very high transistor density of TSMC's 5nm node allows them to postpone switching to chiplets for one more generation). I doubt Hopper will be released before Q4 2021 - Q1 2022 though.Spunjji - Monday, August 24, 2020 - link
I think you're probably right about that release date. Nvidia seem to be quite firmly sticking to a 2-year cadence with mid-cycle refresh now.JayNor - Monday, August 24, 2020 - link
Xe-LP is on 10nm SuperFin and Xe-HP on 10nm Enhanced SuperFin. Judging from Tiger Lake benchmark leaks, the SuperFin process provided a pretty big performance bump vs Ice Lake. Intel says it also can now extend to a higher voltage and frequency range. I expect to see the extra range used in Tiger Lake-H in 2021.Aside from yields, which they noticeably didn't mention, it looks like Intel's 10nm process is doing well.
Ian Cutress - Friday, August 21, 2020 - link
This is news. We're reporting news that came out of the Architecture Day event, just as the same way we report news out of AMD's Tech Days when they give insights into future products. These products aren't finalised, but understanding where Intel is pitching its stake in the sand, at least at a holistic level, is better than not knowing.Normally I'm called a shill for AMD, but what do I know.