The Intel 12th Gen Core i9-12900K Review: Hybrid Performance Brings Hybrid Complexity
by Dr. Ian Cutress & Andrei Frumusanu on November 4, 2021 9:00 AM ESTIntel Disabled AVX-512, but Not Really
One of the more interesting disclosures about Alder Lake earlier this year is that the processor would not have Intel’s latest 512-bit vector extensions, AVX-512, despite the company making a big song and dance about how it was working with software developers to optimize for it, why it was in their laptop chips, and how no transistor should be left behind. One of the issues was that the processor, inside the silicon, actually did have the AVX-512 unit there. We were told as part of the extra Architecture Day Q&A that it would be fused off, and the plan was for all Alder Lake CPUs to have it fused off.
Part of the issue of AVX-512 support on Alder Lake was that only the P-cores have the feature in the design, and the E-cores do not. One of the downsides of most operating system design is that when a new program starts, there’s no way to accurately determine which core it will be placed on, or if the code will take a path that includes AVX-512. So if, naively, AVX-512 code was run on a processor that did not understand it, like an E-core, it would cause a critical error, which could cause the system to crash. Experts in the area have pointed out that technically the chip could be designed to catch the error and hand off the thread to the right core, but Intel hasn’t done this here as it adds complexity. By disabling AVX-512 in Alder Lake, it means that both the P-cores and the E-cores have a unified common instruction set, and they can both run all software supported on either.
There was a thought that if Intel were to release a version of Alder Lake with P-cores only, or if a system had all the E-cores disabled, there might be an option to have AVX-512. Intel shot down that concept almost immediately, saying very succinctly that no Alder Lake CPU would support AVX-512.
Nonetheless, we test to see if it is actually fused off.
On my first system, the MSI motherboard, I could easily disable the E-cores. That was no problem, just adjust the BIOS to zero E-cores. However this wasn’t sufficient, as AVX-512 was still clearly not detected.
On a second system, an ASUS motherboard, there was some funny option in the BIOS.
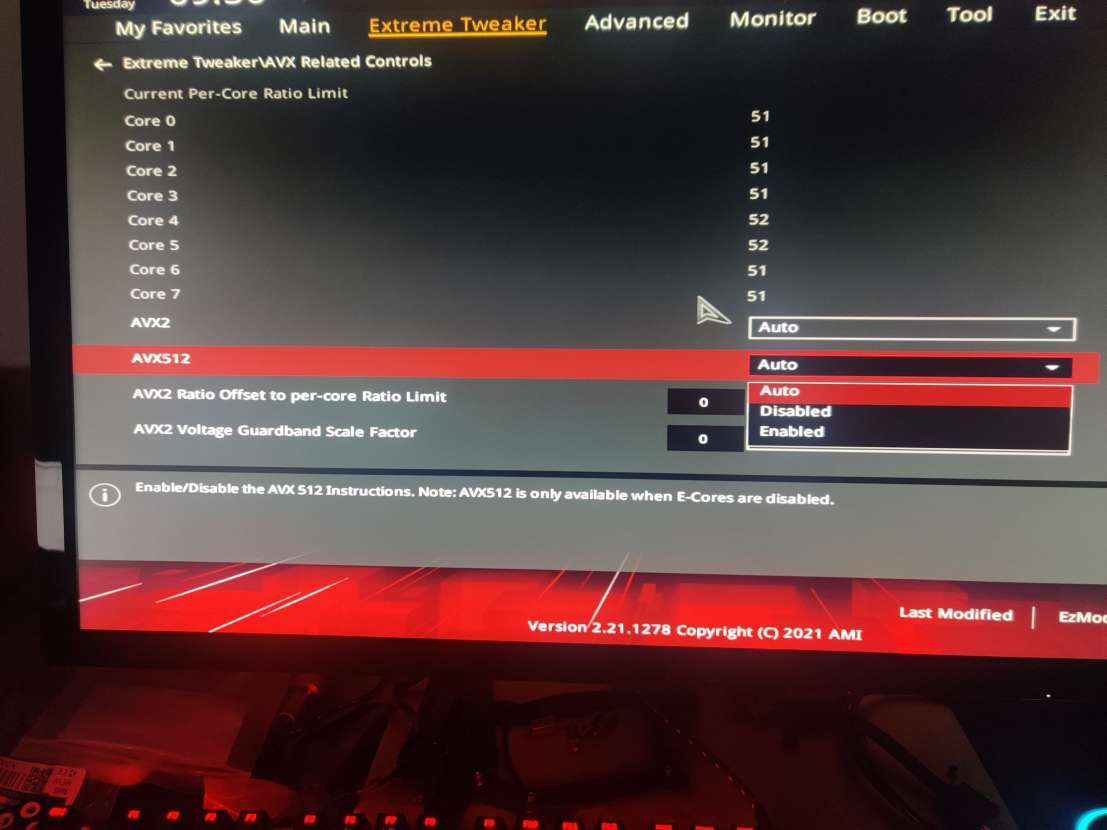
Well I’ll be a monkey’s uncle. There’s an option, right there, front and centre for AVX-512. So we disable the E-cores and enable this option. We have AVX-512 support.
For those that have some insight into AVX-512 might be aware that there are a couple of dozen different versions/add-ons of AVX-512. We confirmed that the P-cores in Alder Lake have:
- AVX512-F / F_X64
- AVX512-DQ / DQ_X64
- AVX512-CD
- AVX512-BW / BW_X64
- AVX512-VL / VLBW / VLDQ / VL_IFMA / VL_VBMI / VL_VNNI
- AVX512_VNNI
- AVX512_VBMI / VBMI2
- AVX512_IFMA
- AVX512_BITALG
- AVX512_VAES
- AVX512_VPCLMULQDQ
- AVX512_GFNI
- AVX512_BF16
- AVX512_VP2INTERSECT
- AVX512_FP16
This is, essentially, the full Sapphire Rapids AVX-512 support. That makes sense, given that this is the same core that’s meant to be in Sapphire Rapids (albeit with cache changes). The core also supports dual AVX-512 ports, as we’re detecting a throughput of 2 per cycle on 512-bit add/subtracts.
For performance, I’m using our trusty 3DPMAVX benchmark here, and compared to the previous generation Rocket Lake (which did have AVX-512), the score increases by a few percent in a scenario which isn’t DRAM limited.
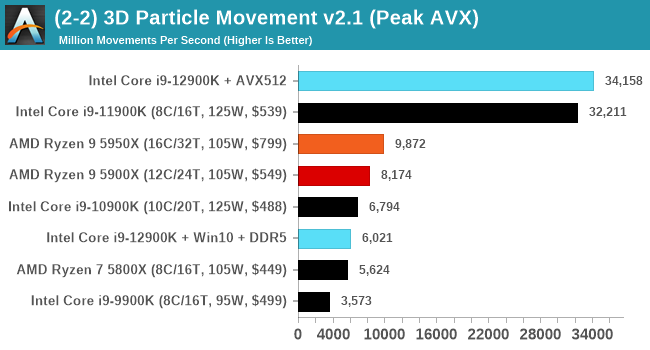
Now back in that Rocket Lake review, we noted that the highest power consumption observed for the chip was during AVX-512 operation. At that time, our testing showcased a big +50W jump between AVX2 and AVX-512 workloads. This time around however, Intel has managed to adjust the power requirements for AVX-512, and in our testing they were very reasonable:
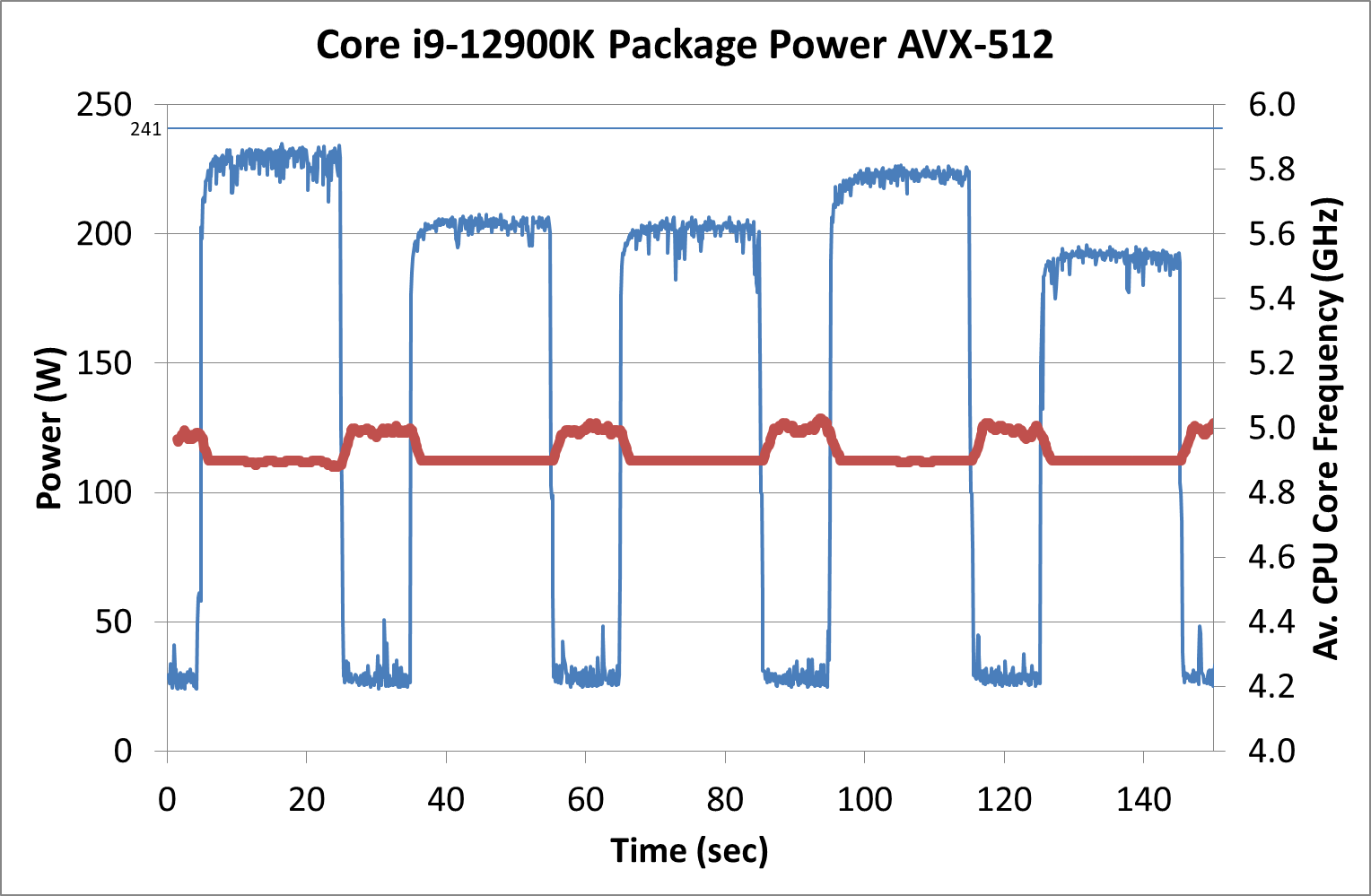
In this graph, we’re showing each of the 3DPM algorithms running for 20 seconds, then idling for 10 seconds. Each one has a different intensity of AVX-512, hence why the power is up and down. IN each instance, the CPU used an all-core turbo frequency of 4.9 GHz, in line with non-AVX code, and our peak power observed is actually 233 W, well below the 241 W rated for processor turbo.
Why?
So the question then refocuses back on Intel. Why was AVX-512 support for Alder Lake dropped, and why were we told that it is fused off, when clearly it isn’t?
Based on a variety of conversations with individuals I won’t name, it appears that the plan to have AVX-512 in Alder Lake was there from the beginning. It was working on early silicon, even as far as ES1/ES2 silicon, and was enabled in the firmware. Then for whatever reason, someone decided to remove that support from Intel’s Plan of Record (POR, the features list of the product).
By removing it from the POR, this means that the feature did not have to be validated for retail, which partly speeds up the binning and testing/validation process. As far as I understand it, the engineers working on the feature were livid. While all their hard work would be put to use on Sapphire Rapids, it still meant that Alder Lake would drop the feature and those that wanted to prepare for Alder Lake would have to remain on simulated support. Not only that, as we’ve seen since Architecture Day, it’s been a bit of a marketing headache. Whoever initiated that dropped support clearly didn’t think of how that messaging was going to down, or how they were going to spin it into a positive. For the record, removing support isn’t a positive, especially given how much hullaballoo it seems to have caused.
We’ve done some extensive research on what Intel has done in order to ‘disable’ AVX-512. It looks like that in the base firmware that Intel creates, there is an option to enable/disable the unit, as there probably is for a lot of other features. Intel then hands this base firmware to the vendors and they adjust it how they wish. As far as we understand, when the decision to drop AVX-512 from the POR was made, the option to enable/disable AVX-512 was obfuscated in the base firmware. The idea is that the motherboard vendors wouldn’t be able to change the option unless they specifically knew how to – the standard hook to change that option was gone.
However, some motherboard vendors have figured it out. In our discoveries, we have learned that this works on ASUS, GIGABYTE, and ASRock motherboards, however MSI motherboards do not have this option. It’s worth noting that all the motherboard vendors likely designed all of their boards on the premise that AVX-512 and its high current draw needs would be there, so when Intel cut it, it meant perhaps that some boards were over-engineered with a higher cost than needed. I bet a few weren’t happy.
Update: MSI reached out to me and have said they will have this feature in BIOS versions 1.11 and above. Some boards already have the BIOS available, the rest will follow shortly.
But AVX-512 is enabled, and we are now in a state of limbo on this. Clearly the unit isn’t fused off, it’s just been hidden. Some engineers are annoyed, but other smart engineers at the motherboard vendors figured it out. So what does Intel do from here?
First, Intel could put the hammer down and execute a scorched earth policy. Completely strip out the firmware for AVX-512, and dictate that future BIOS/UEFI releases on all motherboards going forward cannot have this option, lest the motherboard manufacturer face some sort of wrath / decrease in marketing discretionary funds / support. Any future CPUs coming out of the factory would actually have the unit fused out, rather than simply turned off.
Second, Intel could lift the lid, acknowledge that someone made an error, and state that they’re prepared to properly support it in future consumer chips with proper validation when in a P-core only mode. This includes the upcoming P-core only chips next year.
Third, treat it like overclocking. It is what it is, your mileage may vary, no guarantee of performance consistency, and any errata generated will not be fixed in future revisions.
As I’ve mentioned, apparently this decision didn’t go down to well. I’m still trying to find the name of the person/people who made this decision, and get their side of the story as to technically why this decision was made. We were told that ‘No Transistor Left Behind’, except these ones in that person’s mind, clearly.








474 Comments
View All Comments
bananaforscale - Friday, November 5, 2021 - link
I do wonder about the scheduler interactions if we add Process Lasso into the mix.mode_13h - Friday, November 5, 2021 - link
Ian, please publish the source to your 3D Particle Movement benchmark. Let us see what the benchmark is doing. Also, it's not only AMD that can optimize the AVX2 path. Please let the community have a go at it.mode_13h - Friday, November 5, 2021 - link
> The core also supports dual AVX-512 ports, as we’re detecting> a throughput of 2 per cycle on 512-bit add/subtracts.
I thought that was true of all Intel's AVX-512 capable CPUs? What Intel has traditionally restricted is the number of FMAs. And if you look at the AVX-512 performance of 3DPM on Rocket Lake and Alder Lake, the relative improvement is only 6%. That doesn't support the idea that Golden Cove's AVX-512 is any wider than that of Cypress Cove, which I thought was established to be single-FMA.
SystemsBuilder - Saturday, November 6, 2021 - link
Cascade lake X and Skylake X/XE core i9 and Xeons with more that 12 cores (it think) have two AVX-512 capable FMA ports (port 0 and port 5) while all other AVX-512 capable CPUs have 1 (Port 0 fused).the performance gap could be down to coding. you need to vectorize your code in such a way that you feed both ports at maximum bandwidth.
However, in practice it turns out that the bottle neck is seldom the AVX-512 FMA ports but the memory bandwidth, i.e. it is very hard to keep up with the FMAs, each capable of retiring many of the high end vector operations in 4 clock cycles. e.g. multiply two vectors of 16 32bit floats and add to a 3rd vector in 4 clock cycles. Engaging both FMAs => you retire one FMA vector op every 2 cycles. Trying to avoid getting too technical here, but with a bit of math you see that the total bandwidth capability of the FMAs easily outstrips the cache, even if most vectors are kept in the Z registers – the resisters can only absorbs so much and at the steady state, the cache/memory hierarchy becomes the bottleneck depending on the problem size.
Some clever coding can work around that and hide some of the memory reads (using prefetching etc) but again there is only so much you can do. In other words two AVX-512 FMAs are beasts!
coburn_c - Friday, November 5, 2021 - link
This hybrid design smacks of 5+3 year ago thinking when they wanted to dominate mobile. Maybe that's why it needs 200+ watts to be performant.mode_13h - Friday, November 5, 2021 - link
This doesn't make sense. Their P-cores were never suitable for phones or tablets. Still aren't.I think the one thing we can say is *not* behind Alder Lake is the desire to make a phone/tablet chip. It would be way too expensive and the P-core would burn too much power at even the lowest clockspeeds.
tygrus - Saturday, November 6, 2021 - link
It appears the mixing is more trouble than they are worth for pure mid to high range desktop use. Intel should have split the Desktop CPU's from the mobile CPU's. Put P-cores in the new mid to high range desktops. Put the E-cores in mobiles or cheap desktops/NUC.Wrs - Saturday, November 6, 2021 - link
The mixing helps with a very sought-after trait of high-end desktops. Fast single/lightly threaded performance AND high multithreaded capacity. Meaning very snappy and can handle a lot of multitasking. It is true they can pump out more P cores and get rid of E cores, but that would balloon the die size and cut yields, spiking the cost.mode_13h - Saturday, November 6, 2021 - link
> AND high multithreaded capacity.Yes. This is supported with a very simple experiment. Look at the performance delta between 8 P-Cores and the full 8 + 8 configuration, on highly-threaded benchmarks. All the 8 + 8 configuration has to do is beat the P-core -only config by 25%, in order to prove it's a win.
The reason is simple. Area-wise, the 8 E-cores are equivalent to just 2 more P-cores. The way I see it is as an easy/cheap way for Intel to boost their CPU on highly-threaded workloads. That's what sold me on it. Before I saw that, I only thought Big.Little was good for power-savings in mobile.
mode_13h - Saturday, November 6, 2021 - link
Forgot to add that page 9 shows it meets this bar (I get 25.9%), but the reason it doesn't scale even better is due to the usual reasons for sub-linear scaling. Suffice it to say that a 10 P-core wouldn't scale linearly either, meaning the net effect is almost certainly better performance in the 8+8 config (for integer, at least).