NVIDIA Publishes Statement on GeForce GTX 970 Memory Allocation
by Ryan Smith on January 24, 2015 8:00 PM EST
On our forums and elsewhere over the past couple of weeks there has been quite a bit of chatter on the subject of VRAM allocation on the GeForce GTX 970. To quickly summarize a more complex issue, various GTX 970 owners had observed that the GTX 970 was prone to topping out its reported VRAM allocation at 3.5GB rather than 4GB, and that meanwhile the GTX 980 was reaching 4GB allocated in similar circumstances. This unusual outcome was at odds with what we know about the cards and the underlying GM204 GPU, as NVIDIA’s specifications state that the GTX 980 and GTX 970 have identical memory configurations: 4GB of 7GHz GDDR5 on a 256-bit bus, split amongst 4 ROP/memory controller partitions. In other words, there was no known reason that the GTX 970 and GTX 980 should be behaving differently when it comes to memory allocation.
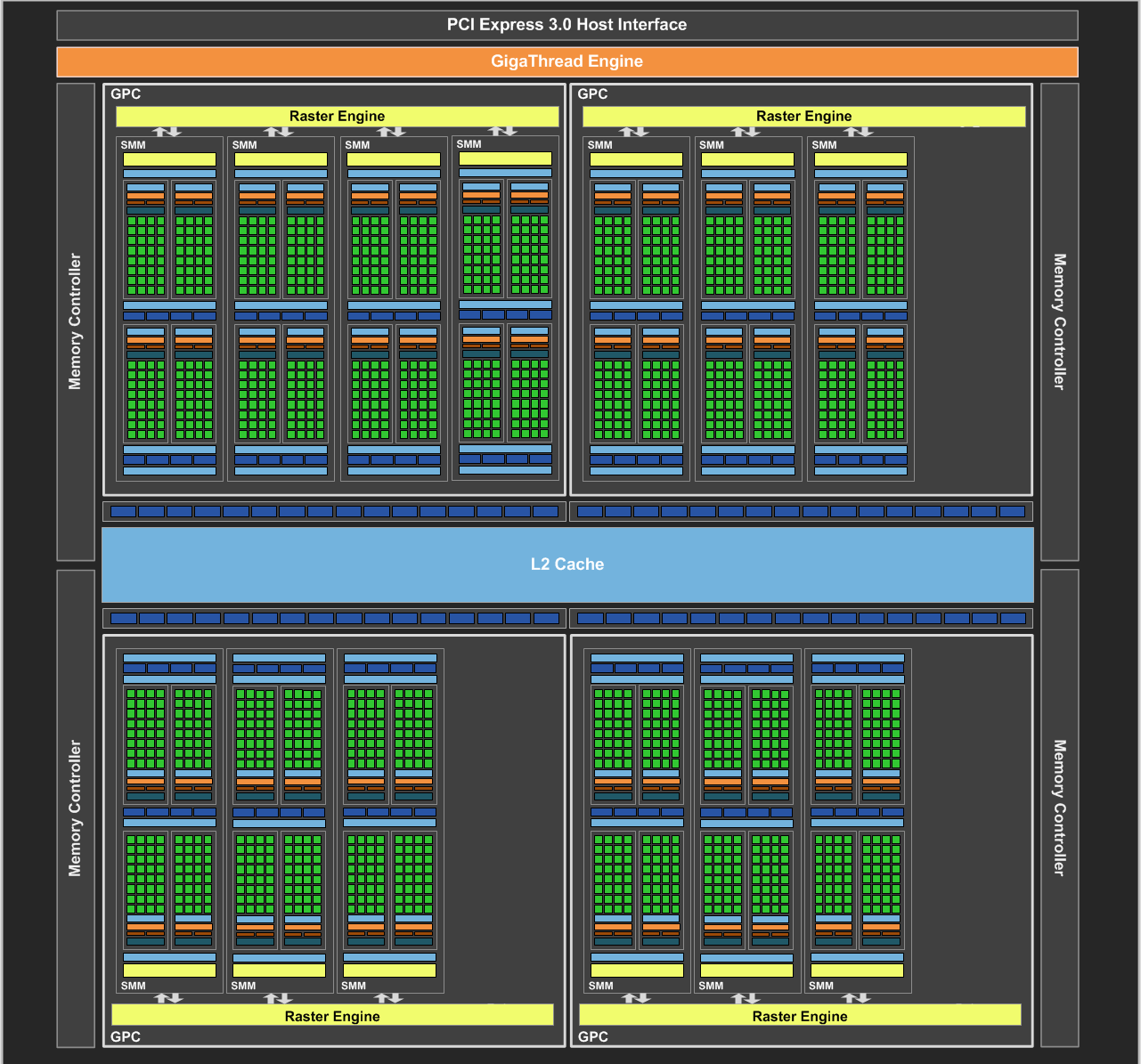
GTX 970 Logical Diagram
GTX 970 Memory Allocation (Image Courtesy error-id10t of Overclock.net Forums)
Since then there has been some further investigation into the matter using various tools written in CUDA in order to try to systematically confirm this phenomena and to pinpoint what is going on. Those tests seemingly confirm the issue – the GTX 970 has something unusual going on after 3.5GB VRAM allocation – but they have not come any closer in explaining just what is going on.
Finally, more or less the entire technical press has been pushing NVIDIA on the issue, and this morning they have released a statement on the matter, which we are republishing in full:
The GeForce GTX 970 is equipped with 4GB of dedicated graphics memory. However the 970 has a different configuration of SMs than the 980, and fewer crossbar resources to the memory system. To optimally manage memory traffic in this configuration, we segment graphics memory into a 3.5GB section and a 0.5GB section. The GPU has higher priority access to the 3.5GB section. When a game needs less than 3.5GB of video memory per draw command then it will only access the first partition, and 3rd party applications that measure memory usage will report 3.5GB of memory in use on GTX 970, but may report more for GTX 980 if there is more memory used by other commands. When a game requires more than 3.5GB of memory then we use both segments.
We understand there have been some questions about how the GTX 970 will perform when it accesses the 0.5GB memory segment. The best way to test that is to look at game performance. Compare a GTX 980 to a 970 on a game that uses less than 3.5GB. Then turn up the settings so the game needs more than 3.5GB and compare 980 and 970 performance again.
Here’s an example of some performance data:
GeForce GTX 970 Performance Settings GTX980 GTX970 Shadows of Mordor
<3.5GB setting = 2688x1512 Very High
72fps
60fps
>3.5GB setting = 3456x1944
55fps (-24%)
45fps (-25%)
Battlefield 4
<3.5GB setting = 3840x2160 2xMSAA
36fps
30fps
>3.5GB setting = 3840x2160 135% res
19fps (-47%)
15fps (-50%)
Call of Duty: Advanced Warfare
<3.5GB setting = 3840x2160 FSMAA T2x, Supersampling off
82fps
71fps
>3.5GB setting = 3840x2160 FSMAA T2x, Supersampling on
48fps (-41%)
40fps (-44%)
On GTX 980, Shadows of Mordor drops about 24% on GTX 980 and 25% on GTX 970, a 1% difference. On Battlefield 4, the drop is 47% on GTX 980 and 50% on GTX 970, a 3% difference. On CoD: AW, the drop is 41% on GTX 980 and 44% on GTX 970, a 3% difference. As you can see, there is very little change in the performance of the GTX 970 relative to GTX 980 on these games when it is using the 0.5GB segment.
Before going any further, it’s probably best to explain the nature of the message itself before discussing the content. As is almost always the case when issuing blanket technical statements to the wider press, NVIDIA has opted for a simpler, high level message that’s light on technical details in order to make the content of the message accessible to more users. For NVIDIA and their customer base this makes all the sense in the world (and we don’t resent them for it), but it goes without saying that “fewer crossbar resources to the memory system” does not come close to fully explaining the issue at hand, why it’s happening, and how in detail NVIDIA is handling VRAM allocation. Meanwhile for technical users and technical press such as ourselves we would like more information, and while we can’t speak for NVIDIA, rarely is NVIDIA’s first statement their last statement in these matters, so we do not believe this is the last we will hear on the subject.
In any case, NVIDIA’s statement affirms that the GTX 970 does materially differ from the GTX 980. Despite the outward appearance of identical memory subsystems, there is an important difference here that makes a 512MB partition of VRAM less performant or otherwise decoupled from the other 3.5GB.
Being a high level statement, NVIDIA’s focus is on the performance ramifications – mainly, that there generally aren’t any – and while we’re not prepared to affirm or deny NVIDIA’s claims, it’s clear that this only scratches the surface. VRAM allocation is a multi-variable process; drivers, applications, APIs, and OSes all play a part here, and just because VRAM is allocated doesn’t necessarily mean it’s in use, or that it’s being used in a performance-critical situation. Using VRAM for an application-level resource cache and actively loading 4GB of resources per frame are two very different scenarios, for example, and would certainly be impacted differently by NVIDIA’s split memory partitions.
For the moment with so few answers in hand we’re not going to spend too much time trying to guess what it is NVIDIA has done, but from NVIDIA’s statement it’s clear that there’s some additional investigating left to do. If nothing else, what we’ve learned today is that we know less than we thought we did, and that’s never a satisfying answer. To that end we’ll keep digging, and once we have the answers we need we’ll be back with a deeper answer on how the GTX 970’s memory subsystem works and how it influences the performance of the card.








93 Comments
View All Comments
Samus - Sunday, January 25, 2015 - link
The technical explanation of this is pretty simple. NVidia doesn't need to say anything further, other than WHY this really had to be implemented this way. But the way it works is simple.Imagine you have a 4GB SSD and 3500MB is C: and 500MB is D:
You can still use all 4GB of it. The only scenario you'd have a problem is if you have a 3600MB file. You couldn't actually store the file anywhere. But in games this never happens. Images, vector\shadder cache and various computational data are all small chunks. It'll span across the two partitions without any real penalty. There might even be an optimization to put certain low priority data on the 500MB partition under stressful workloads, such as PhysX data...
But this does become a problem, for example, a CUDA program that uses a database (a single file) as that file will be capped at 3.5GB. This is an incredibly rare case, and admittedly, a poorly written program as the database should probably be broken up in to 500MB chunks to prevent memory fragmentation.
olafgarten - Sunday, January 25, 2015 - link
I think I would be more worried that my SSD is smaller than my RAM!edzieba - Sunday, January 25, 2015 - link
"The only scenario you'd have a problem is if you have a 3600MB file"To be pedantic, it will happen if you have a 3500+MB OPERATION, e.g. if you have two 1200MB megatextures and you for some reason want to perform an operation that combines both into a third texture. That requires 3600MB total vRAM. This is an example (texture compression occurs, and that's a massive texture to be working on all at once), but there might be some very weird edge cases where operating on a lot of large files may start to dip into the lower-speed zone.
I can't see it being an issue for games even at extreme render and texture resolutions though.
Samus - Sunday, January 25, 2015 - link
It's important to point out that VRAM isn't a limiting factor in any graphics cards ability to render large chunks of data.Data that doesn't fit in VRAM simply get paged to system RAM, as they have for decades.
Friendly0Fire - Monday, January 26, 2015 - link
At a heavy performance hit which I doubt any game developer wants to trigger.Siana - Friday, January 30, 2015 - link
The memory is fully virtualized on the GPU, has been since GeForce6. It doesn't matter if you have a single drawcall, or single object hitting the barrier or multiple. I don't think any special provisions on the application end are necessary.I think the issue is best handled by the driver, which knows already which programs are demanding and which aren't, because demanding programs are either on its whitelist, or carry an NvOptimusEnablement token, or link NVAPI or CUDA. That's the rules set by nVidia Optimus, or are manually specified by the user. So then the driver could force the programs which are demanding to believe they have 3.5 GB and partition them into the fast section exclusively, and partition non-demanding programs such as DWM into the slow section first.
Given that DWM alone will happily eat a few hundred megs, we're really talking just about 200MB of actual performance-relevant difference. What's the big deal?
Vayra - Monday, January 26, 2015 - link
Windows occupies around 200+MB of VRAM on that slower partition as well. Hitting the 4GB or 3.51GB marker is really not that hard to do, especially when gaming @ 4K which is well within reach on this card (due to the higher amount of VRAM, in part).The issue here is frame times. The stutter that occurs when crossing the magical VRAM barrier (ie swaps bigger than 3.5GB) is precisely the same as the stutter that occurs when using 2.1GB on a 2GB card. It hardly shows in frame rate, but does show in frame time. Basically we have a card here that handles like a 3.5GB VRAM capped card, but is marketed as a 4GB one. It does not matter that at THE CURRENT STATE IN GAMING not many games utilize over 3.5GB. What matters is that the last 0,5GB does not perform like one would expect from GDDR5, it actually performs as if you didn't have it at all.
Superlatives such as 'an incredibly rare case' are worthless. If there is one edge case today, there will be dozens in a years' time as demands on VRAM increase further.
Lakku - Tuesday, February 3, 2015 - link
And do you have any proof to back up that claim?Gothmoth - Sunday, January 25, 2015 - link
it may sounds bad because(!) you have no clue....2late2die - Saturday, January 24, 2015 - link
I an confused about as to why Nvidia's statement isn't satisfactory in this case (consumer/performance wise). Obviously someone technical might be curious about more details, but as far as the whole "is it actually 4GB or not" issue goes, it seems like that has been resolved.Also, the following I feel is inaccurate:
"Despite the outward appearance of identical memory subsystems, there is an important difference here that makes a 512MB partition of VRAM less performant or otherwise decoupled from the other 3.5GB."
Nowhere did Nvidia say that the .5GB of RAM is less performant. What they said is that the 3.5GB allocation has higher priority, which is completely logical as you'd want the card to use that partition first. As for performance their statement doesn't say anything either way, instead it just goes into those examples, which to my mind show that there is in fact no significant performance hit. Now, one could certainly assume that the reason they didn't specifically say that the .5GB allocation performs the same is that it does perform slower, but that's just an assumption.
At the end of the day, it seems to me that there has been no wrong doing on Nvidia's part here other than not going into a bunch of technical detail into which they usually don't go in any case. They didn't lie about having 4GB of memory, and while the way that memory used is different between 980 and 970, it doesn't seem to affect performance.