ARM Details "Project Trillium" Machine Learning Processor Architecture
by Andrei Frumusanu on May 22, 2018 11:30 AM EST
Arm first announced Project Trillium machine learning IPs back in February and we were promised we’d be hearing more about the product in a few months’ time. Project Trillium is unusual for Arm to talk about because the IP hasn’t been finalised yet and won’t be finished until this summer, yet Arm made sure not to miss out on the machine learning and AI “hype train” that has happened over the last 8 months in both the semiconductor industry and as well as particularly in the mobile industry.
Today Arm details more of the architecture of what Arm now seems to more consistently call their “machine learning processor” or MLP from here on now. The MLP IP started off a blank sheet in terms of architecture implementation and the team consists of engineers pulled off from the CPU and GPU teams.
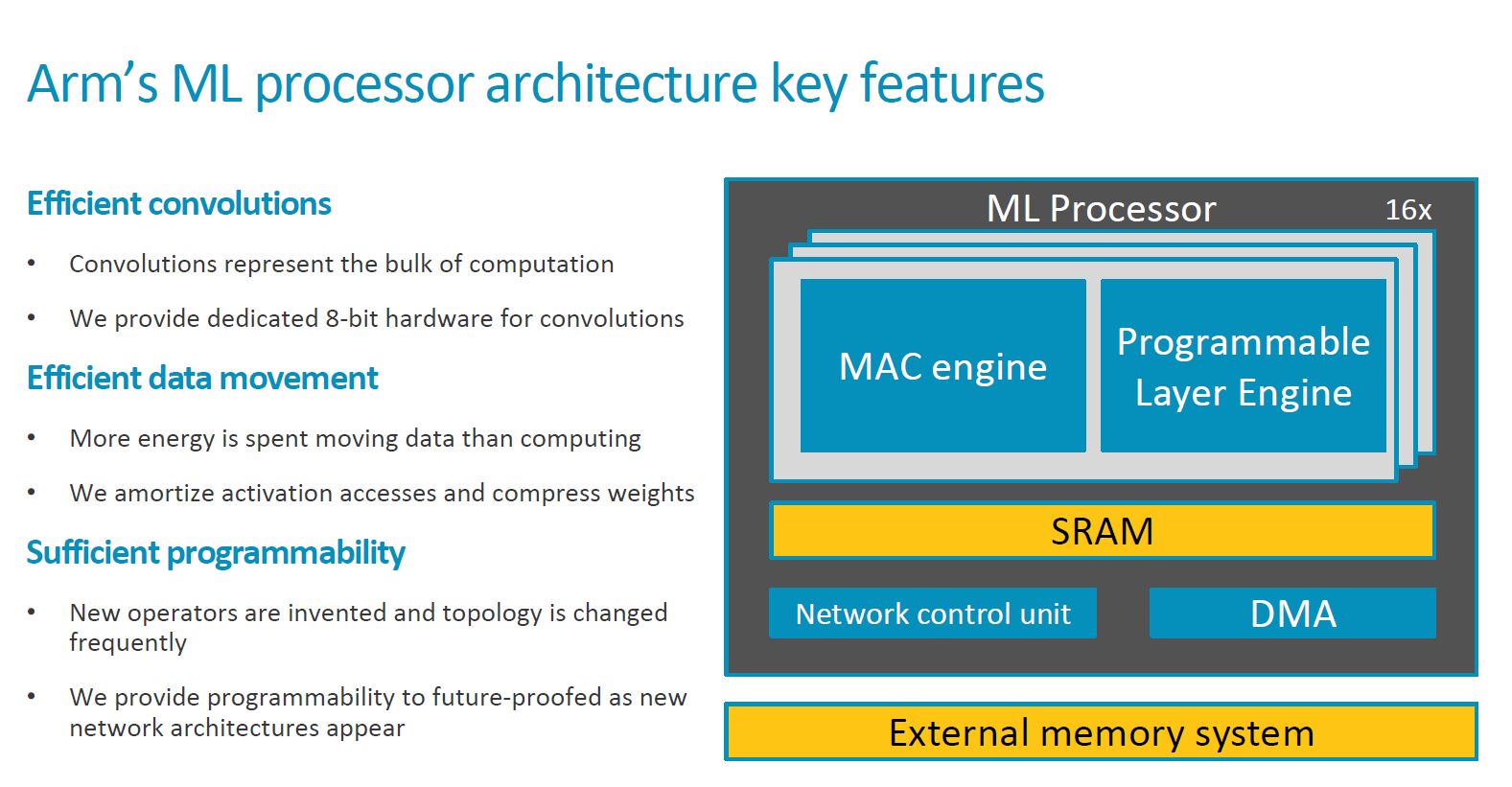
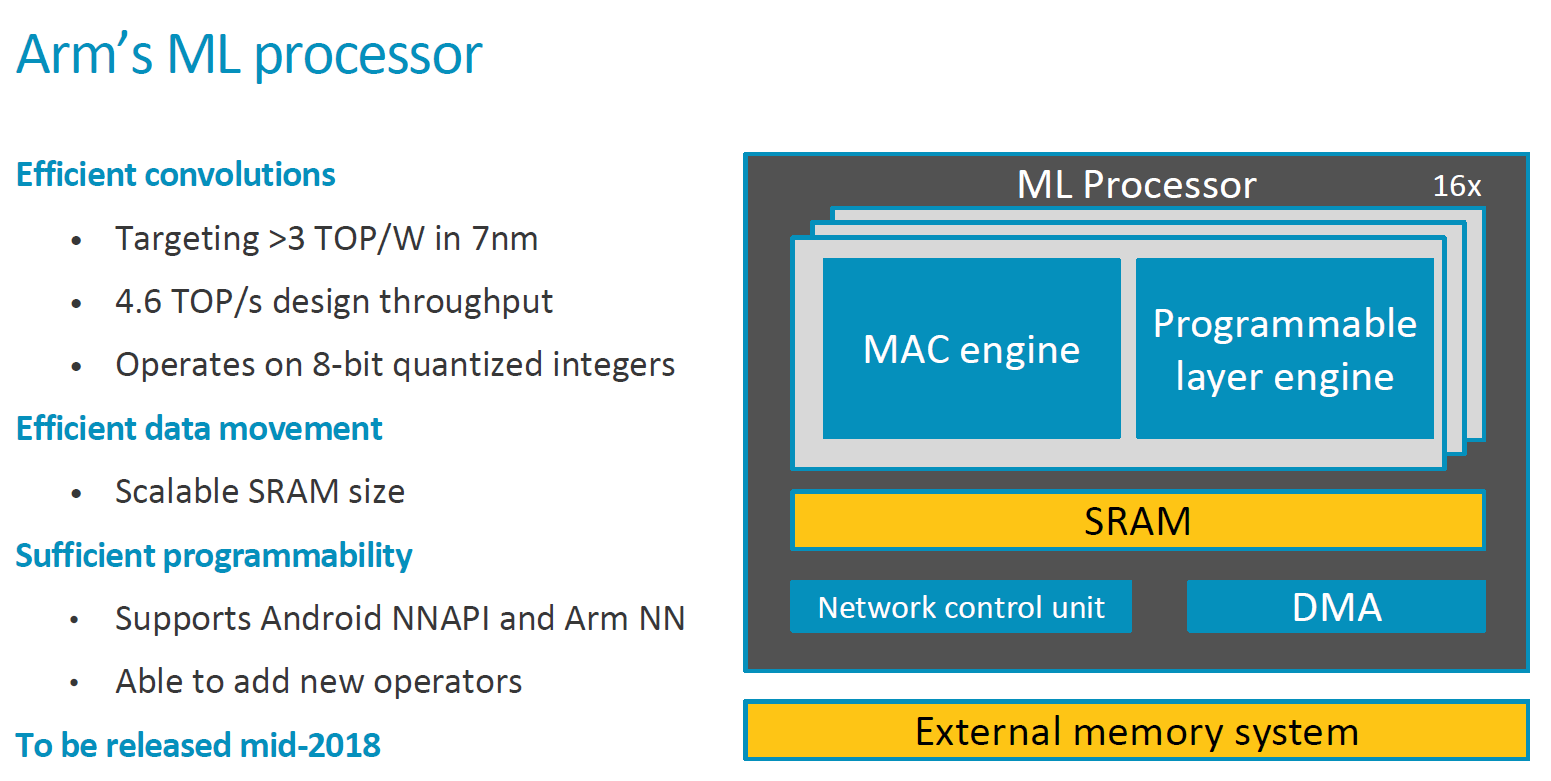
With the MLP Arm set out to provide three key aspects that are demanded in machine learning IPs: Efficiency of convolutional computations, efficient data movement, and sufficient programmability. From a high level perspective the MLP seems no different than many other neural network accelerator IPs out there. It still has a set of MAC engines for the raw computational power, while offering some sort of programmable control flow block alongside a sufficiently robust memory subsystem.
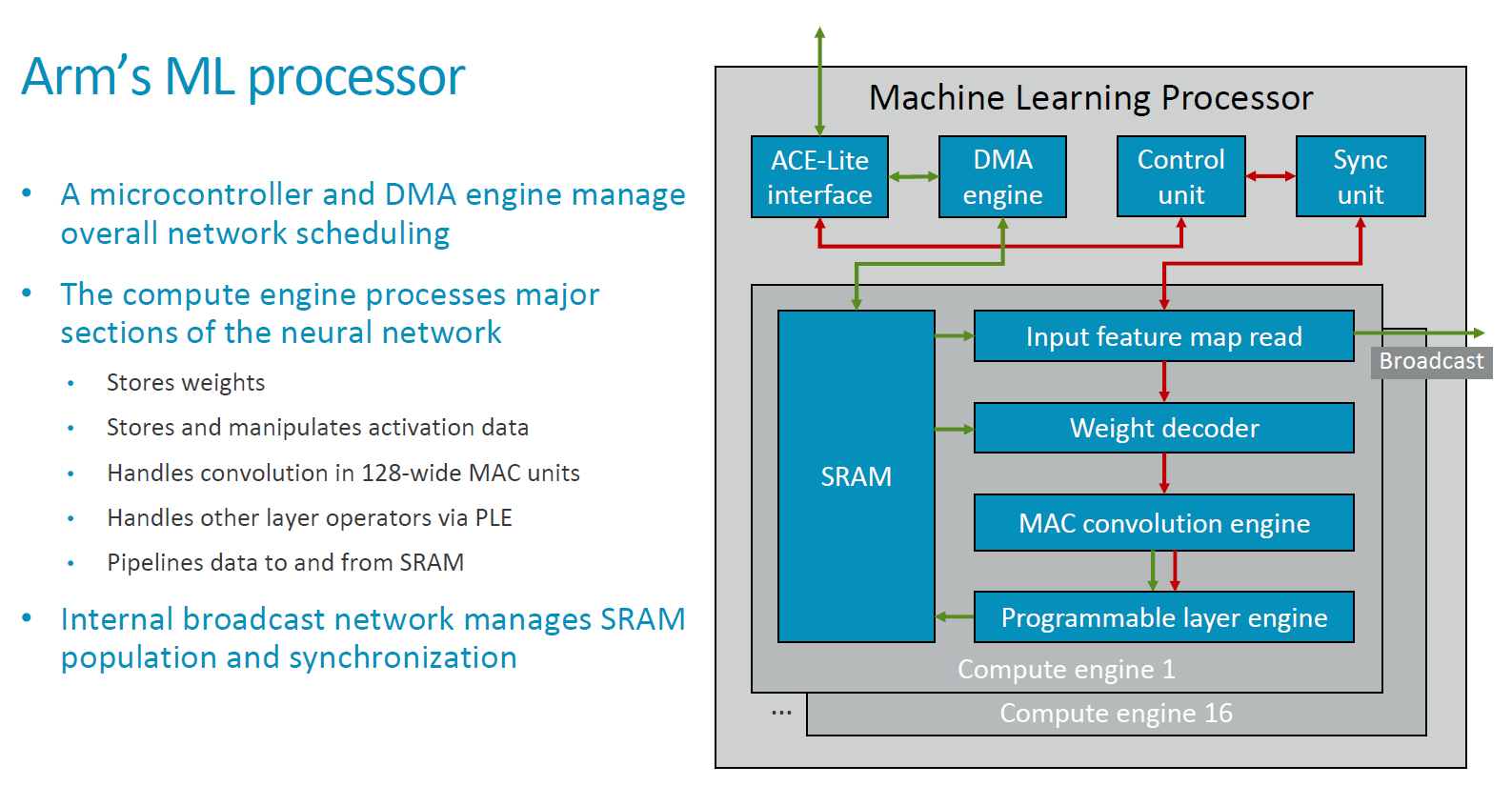
Starting off at a more detailed view of the IP’s block diagram, the MLP consists of common functional blocks such as the memory interconnect interfaces as well as a DMA engine. The above graphic we see portrayal of the data flow (green arrows) and control flow (red arrows) throughout the functional blocks of the processor. The SRAM is a common block to the MLP sized at 1MB which serves as the local buffer for computations done by the compute engines. The compute engines each contained fixed function blocks which operate on the various layers of the neural network model, such as input feature map read blocks which pass onto control information to a weight decoder.
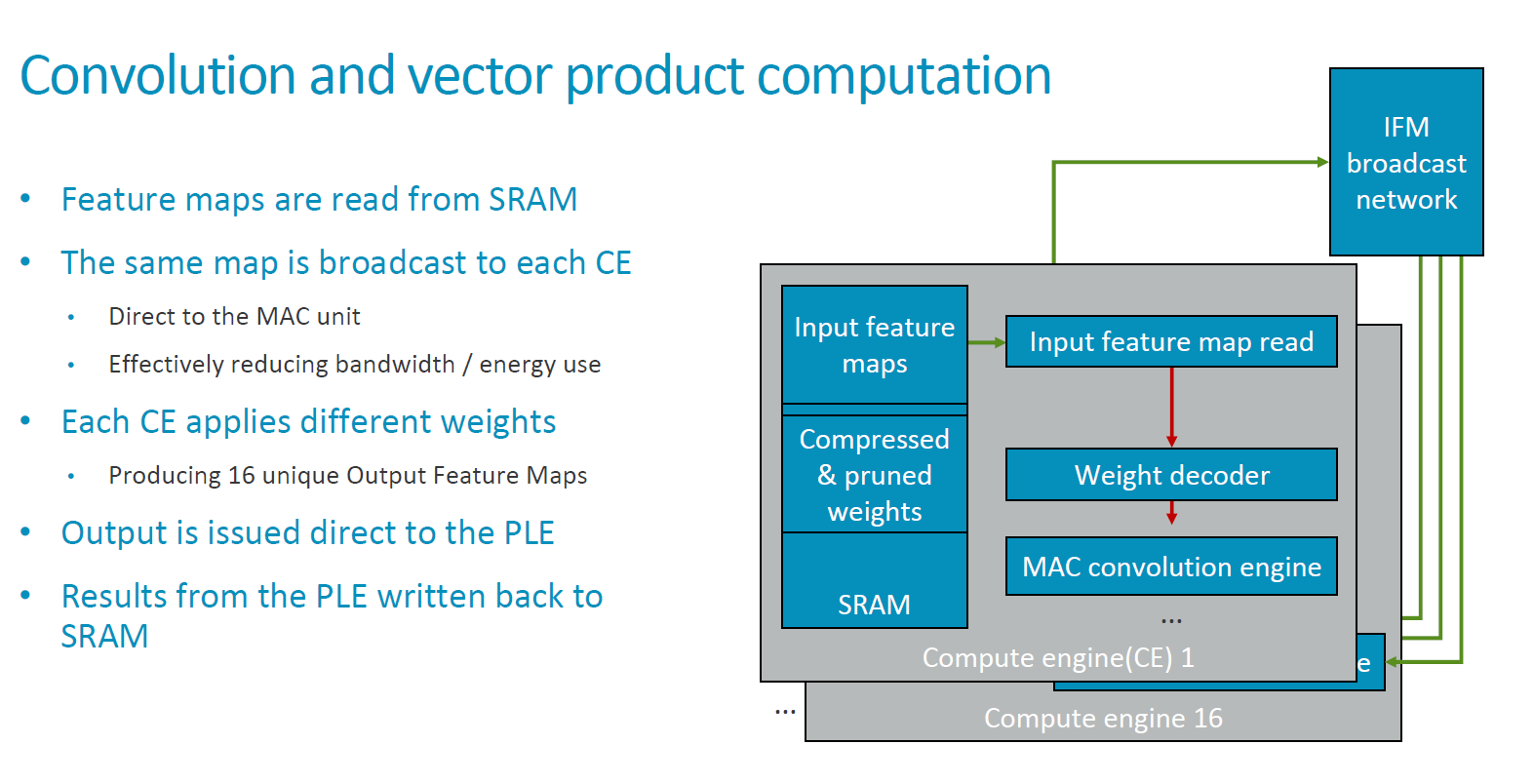
At the heart the actual convolution engine which does the computations is a 128-wide MAC unit operating on 8-bit integer data storing the quantised weights of the NN model.
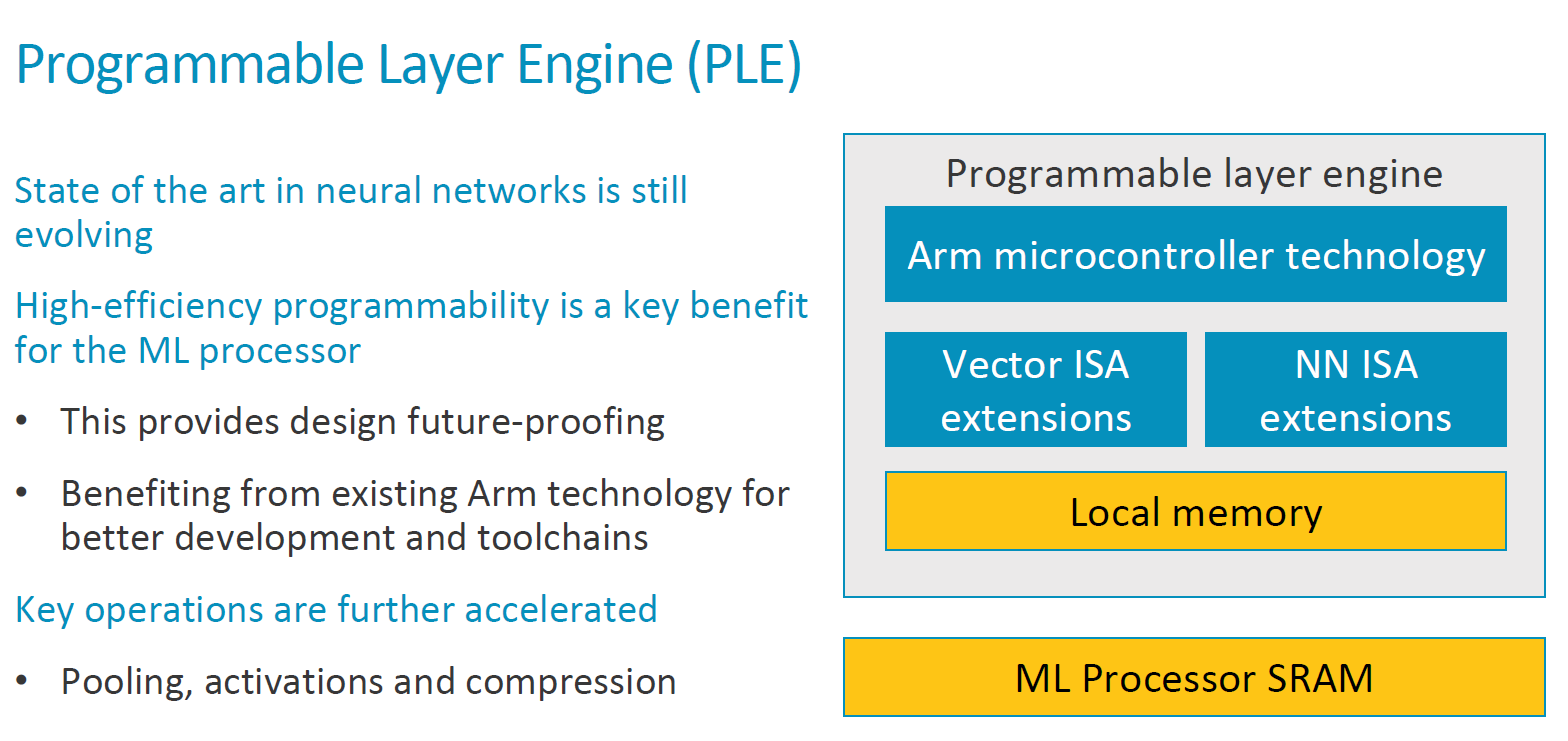
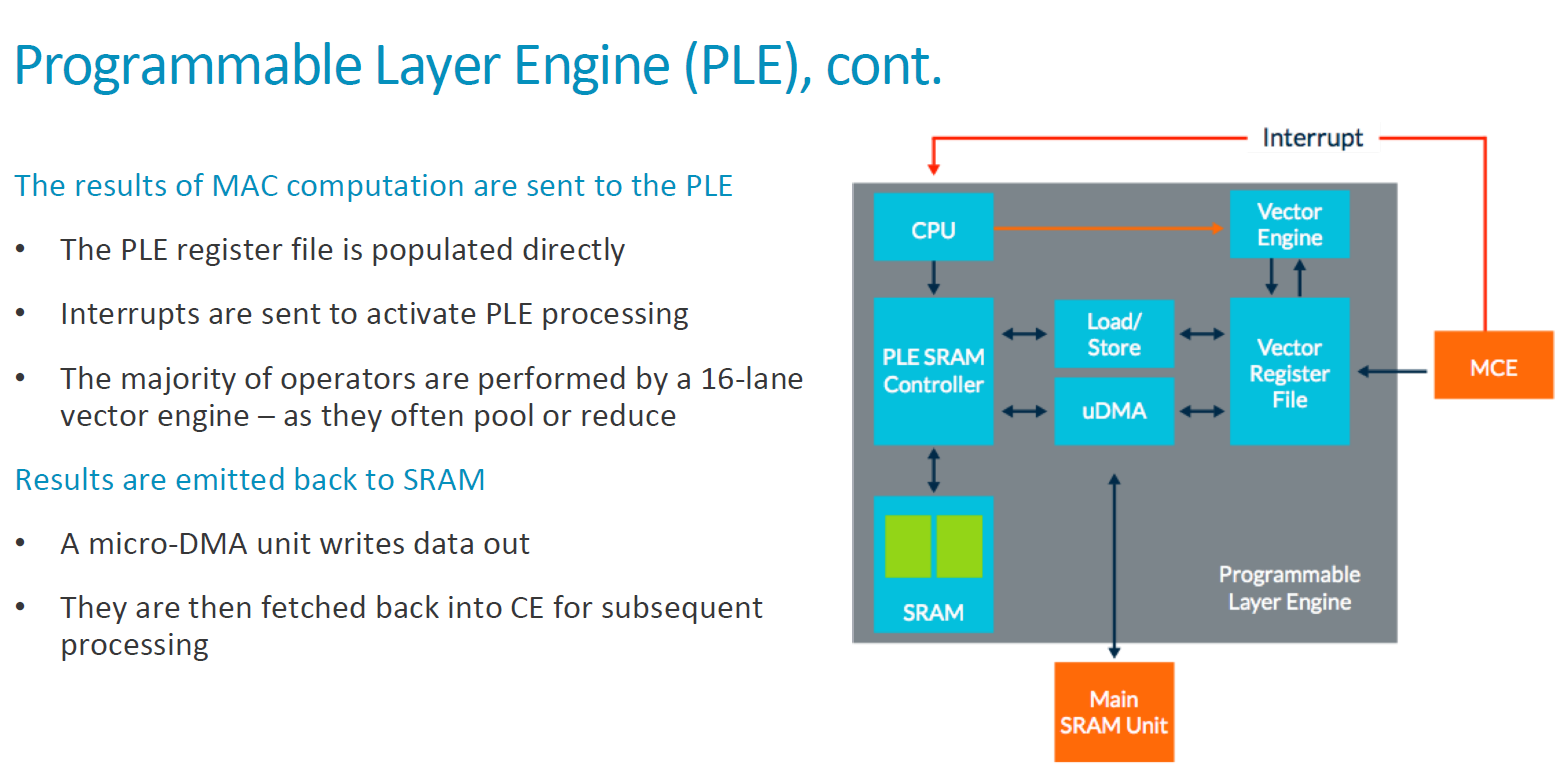
Arm recognises that the future of neural network models is relatively uncertain and we haven’t really seen any sort of “standard” model emerge. It is most certain that in the coming years we’ll see different kind of model architectures improve on existing neural networks, and this means that any kind of hardware implementation today will need to provide sufficient flexibility that it will be able to be compatible with eventual future models. The MLP thus offers a “programmable layer engine” which is a specialised processing unit with vector and NN specific instructions that are able to operate on different pooling or other layer operations with enhanced flexibility and programmability compared to a fixed function block.
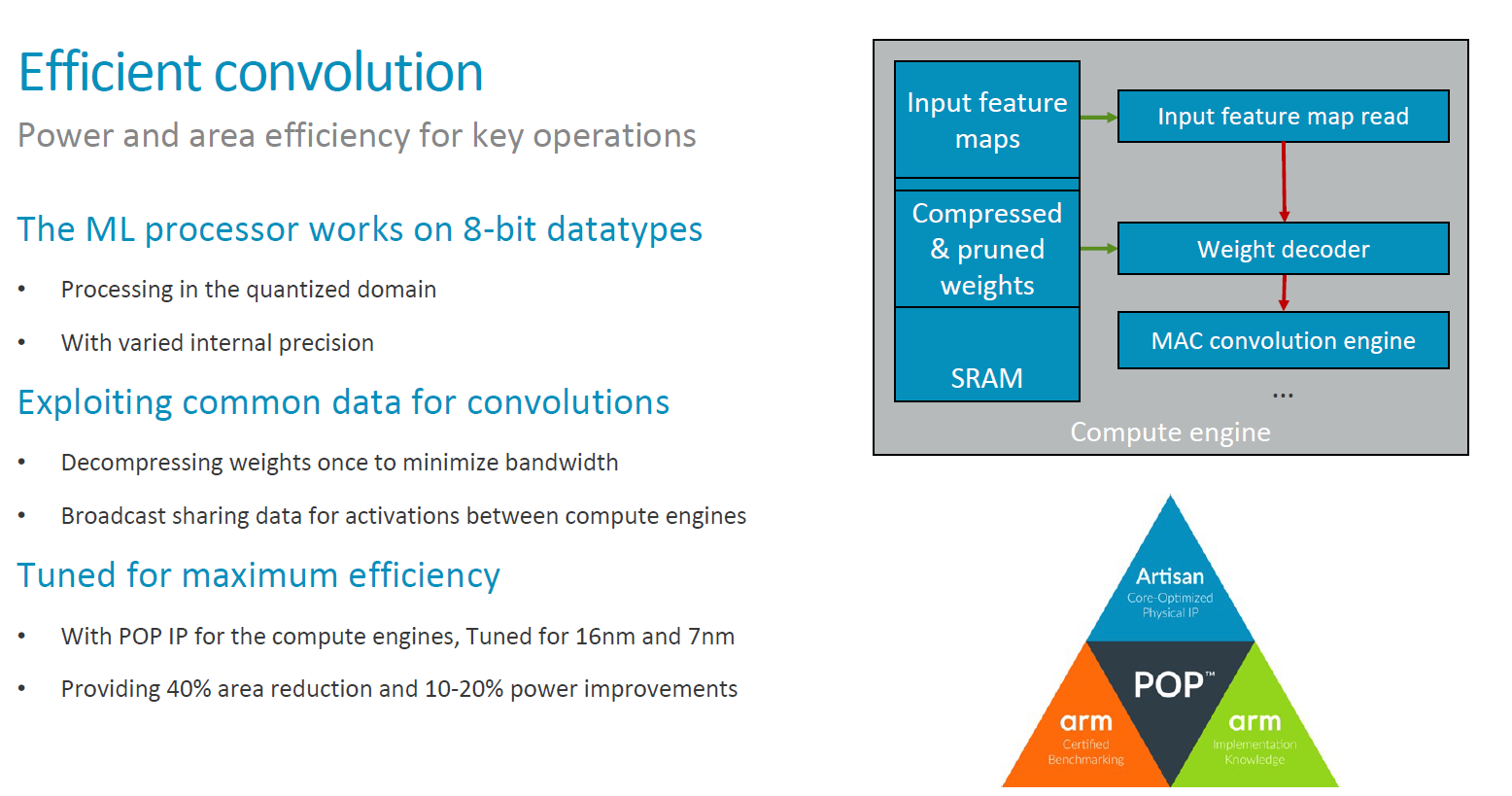
Important for efficient convolutions is how data is handled through the IP block as data-flow and bandwidth requirements easily overshadow any computational unit power. Again, the MLP operates on 8-bit quantized data and Arm states that the internal precision is varied, however without further detailing more on this aspect of the architecture.

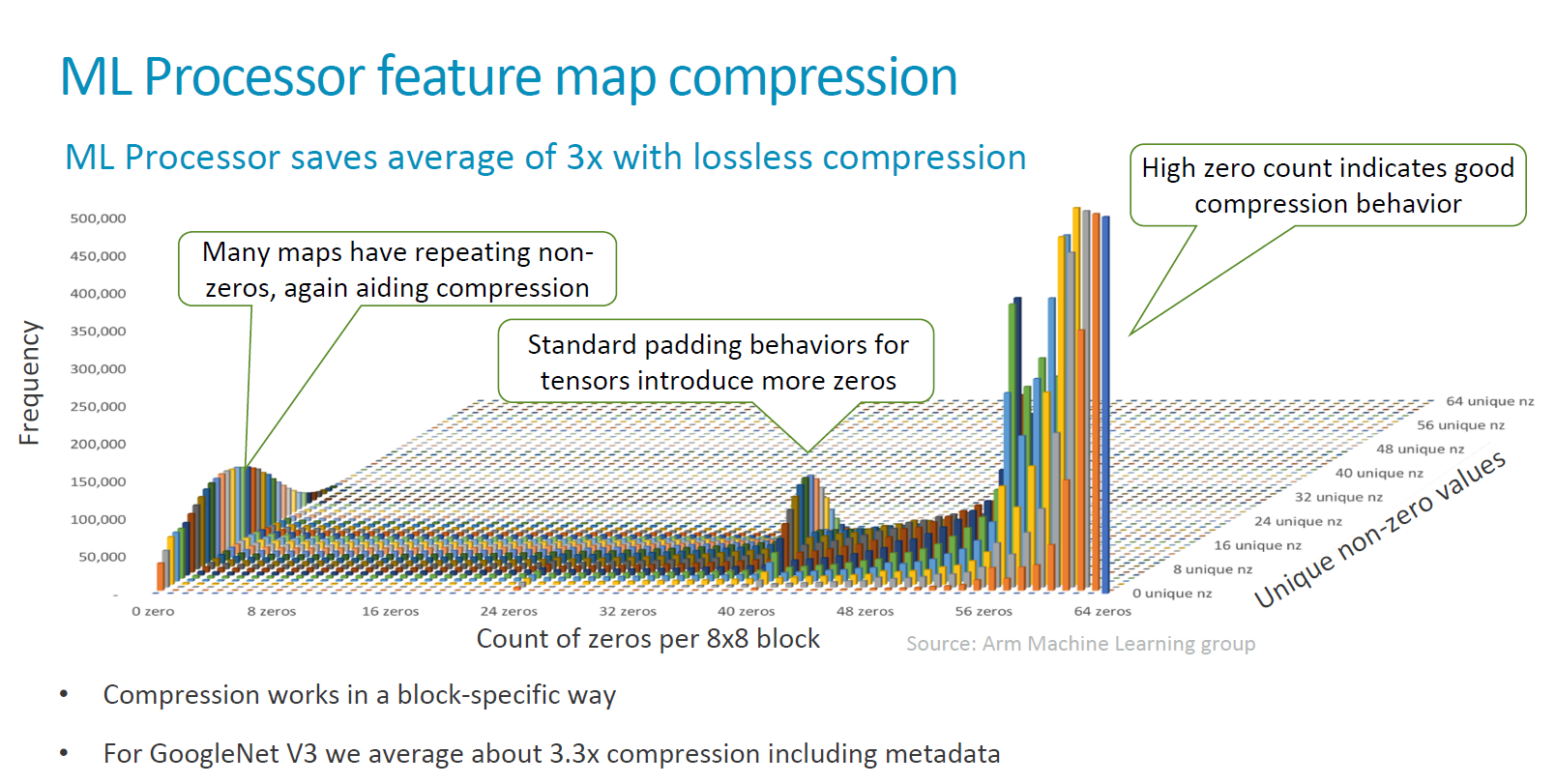
Another important feature unique to the MLP is the inclusion of compression capability on the part of the data set / feature map.
Arm’s compression algorithm is lossless and promises an up to 3x compression ratio which reduces the bandwidth to external DRAM and thus having a very large impact on overall system power.

While the compression of weights and feature maps happen on the MLP losslessly at runtime, another important optimisation for memory bandwidth is the actual training and optimisation of the neural network model. This happens offline through Arm’s software tools which are then able to optimise the data for better compression ratio as well as prune irrelevant connections to save on the computation requirements on the MACs – further improving both power efficiency as well as performance.
I’ll admit that Arm’s MLP architecture disclosure might seem interesting on paper – how it will actually perform in terms of actual performance as well as efficiency versus other architectures from other vendors is still something we won’t know until we actually have silicon back and can run some real world workloads. This seems to be an issue that other vendors also have recognised and why many of them have actually decided against divulging more in-depth architectural characteristics such as presented by Arm today.
Arm proclaims target metrics such as >3TOPs/W on 7nm implementations with absolute throughputs of 4.6TOPs (deriving target power of ~1.5W). Again these metrics are relatively ephemeral in their meaning as actual performance of inferencing work will also strongly depend on additional characteristics such as overall MAC utilisation or performance of the IP fully-connected layers.
In terms of scalability the MLP is meant to come with configurable compute engine setups from 1 CE up to 16 CEs and a scalable SRAM buffer up to 1MB. The current active designs however are the 16CE and 1MB configurations and smaller scaled down variants will happen later on in the product lifecycle. Arm wasn’t ready to note exact area figures for the MLP but generally we’ll be looking at around larger than an A55.
As I’ve noted in past releases from competitor neural network IPs – we’re still very early on in the ecosystem so to give any actual judgment on the competitiveness or how good a certain IP is against the other is something that’s essentially impossible to predict. The more obvious aspect we can talk about is timelines – ARM’s MLP and project Trillium does lag behind in terms of availability as we won’t be seeing finalisation of the RTL until sometime this summer, which means we won’t be seeing silicon until around mid- to late 2019 at the earliest meaning the MLP will likely have to face off competitor IP such as the third-generation NPU from HiSilicon.
On the high-end there’s seemingly also not that many prospective customers for the MLP as many are opting for their own solutions – it’s on the low- and mid-range where we might see more success for Project Trillium but also that will be a tough uphill battle against the quite varied IP offerings from competitors and Arm’s best chance for success here is to really emphasize on its CPU-GPU-MLP software ecosystem advantage.








13 Comments
View All Comments
peevee - Tuesday, May 22, 2018 - link
Isn't it named deceptively compared to what it can actually do? Application of models is not the same as machine learning, which is building them.boeush - Tuesday, May 22, 2018 - link
If the PLE is sufficiently flexible, it might support actual backpropagation (or other actual learning-type processing.)Aside from which, during any kind of learning, a major aspect is running the network through a training set over and over and over again, to obtain some result that then feeds into iterative corrections to the network's structure or weights - which could still be significantly accelerated even by processors that only purely support "application of models".
mode_13h - Wednesday, May 23, 2018 - link
The emphasis on 8-bit processing suggests it won't be well-suited to training.hastalavista - Wednesday, May 23, 2018 - link
Why do u think so? I think increasing to more 8bits will dramatically increase the power values, making the whole chip not so interestingpeevee - Wednesday, May 23, 2018 - link
From the architecture in the pic above, it is not flexible at all (or at least not in the efficient manner).Yojimbo - Wednesday, May 23, 2018 - link
"Machine learning" is the technology and the discipline. "Training" is the building of models, and "inference" is the application of the models. Both training and inference are part of machine learning.peevee - Wednesday, May 23, 2018 - link
Let's agree to disagree on definition on terms. For me, learning means learning.jospoortvliet - Sunday, May 27, 2018 - link
I get your point but I find it hard to argue that inferencing isn't part of the Machine Learning discipline...gerWal - Wednesday, May 23, 2018 - link
Inference is a logical pipeline for mobile devices, whilst training is better suited for desktop/servers as the do not have similar power constraints to mobile devices.peevee - Wednesday, May 23, 2018 - link
Of course. Just inference is not learning. It is application of something learned somewhere else.