The AMD Zen and Ryzen 7 Review: A Deep Dive on 1800X, 1700X and 1700
by Ian Cutress on March 2, 2017 9:00 AM ESTZen: New Core Features
Since August, AMD has been slowly releasing microarchitecture details about Zen. Initially it started with a formal disclosure during Intel’s annual developer event, the followed a paper at HotChips, some more details at the ‘New Horizon’ event in December, and recently a talk at ISSCC. The Zen Tech Day just before launch gave a chance to get some of those questions answered.
First up, let’s dive right in to the high-level block diagram:
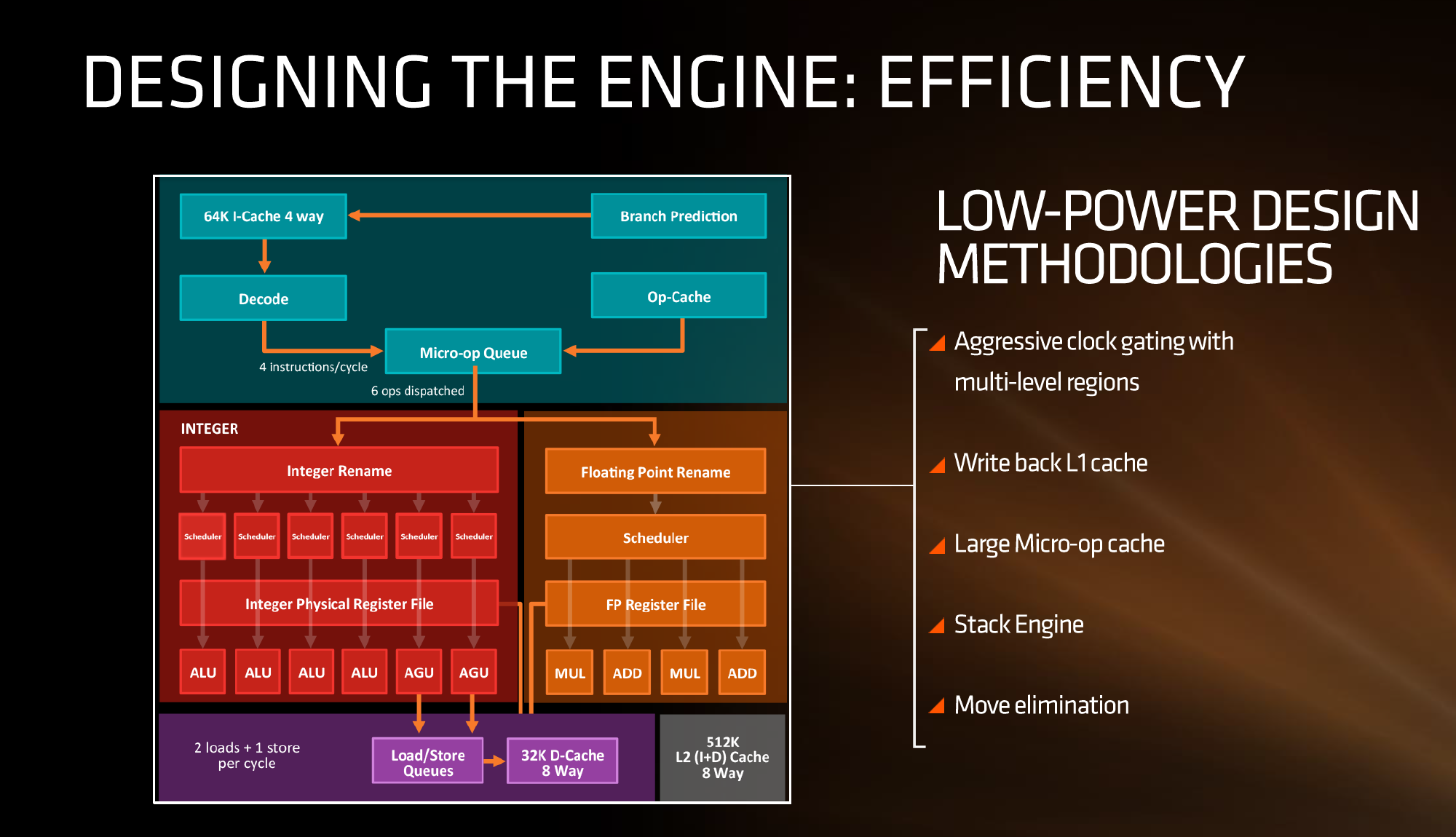
In this diagram, the core is split into the ‘front-end’ in blue and the rest of the core is the ‘back-end’. The front-end is where instructions come into the core, branch predictors are activated and instructions are decoded into micro-ops (micro-operations) before being placed into a micro-op queue. In red is the part of the back-end that deals with integer (INT) based instructions, such as integer math, loops, loads and stores. In orange is the floating-point (FP) part of the back-end, typically focused on different forms of math compute. Both the INT and FP segments have their own separate execution port schedulers
If it looks somewhat similar to other high-performance CPU cores, you’d be correct: there seems to be a high-level way of ‘doing things’ when it comes to x86, with three levels of cache, multi-level TLBs, instruction coalescing, a set of decoders that dispatch a combined 4-5+ micro-ops per cycle, a very large micro-op queue (150+), shared retire resources, AVX support, and simultaneous hyper-threading.
What’s New to AMD
First up, and the most important, was the inclusion of the micro-op cache. This allows for instructions that were recently used to be called up to the micro-op queue rather than being decoded again, and saves a trip through the core and caches. Typically micro-op caches are still relatively small: Intel’s version can support 1536 uOps with 8-way associativity. We learned (after much asking) at AMD’s Tech Day that the micro-op cache for Zen can support ‘2K’ (aka 2048) micro-ops with up to 8-ops per cache line. This is good for AMD, although I conversed with Mike Clark on this: if AMD had said ‘512’, on one hand I’d be asking why it is so small, and on the other wondering if they would have done something different to account for the performance adjustments. But ‘2K’ fits in with what we would expect.
Secondly is the cache structure. We were given details for the L1, L2 and L3 cache sizes, along with associativity, to compare it to former microarchitectures as well as Intel’s offering.
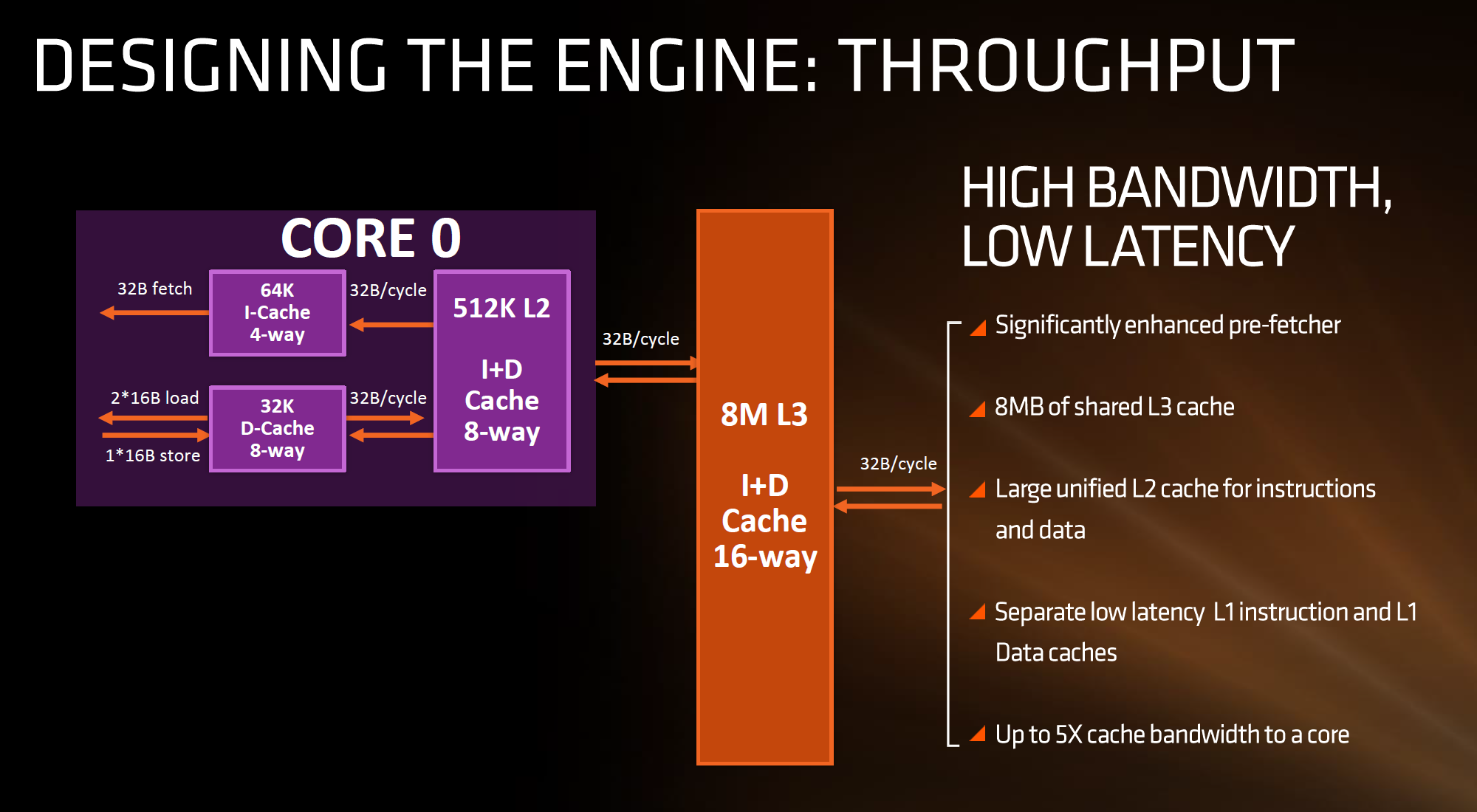
In this case, AMD has given Zen a 64KB L1 Instruction cache per core with 4-way associativity, with a lop-sided 32KB L1 Data cache per core with 8-way associativity. The size and accessibility determines how frequently a cache line is missed, and it is typically a trade-off for die area and power (larger caches require more die area, more associativity usually costs power). The instruction cache, per cycle, can afford a 32byte fetch while the data cache allows for 2x 16-byte loads and one 16-byte store per cycle. AMD stated that allowing two D-cache loads per cycle is more representative of the most workloads that end up with more loads than stores.
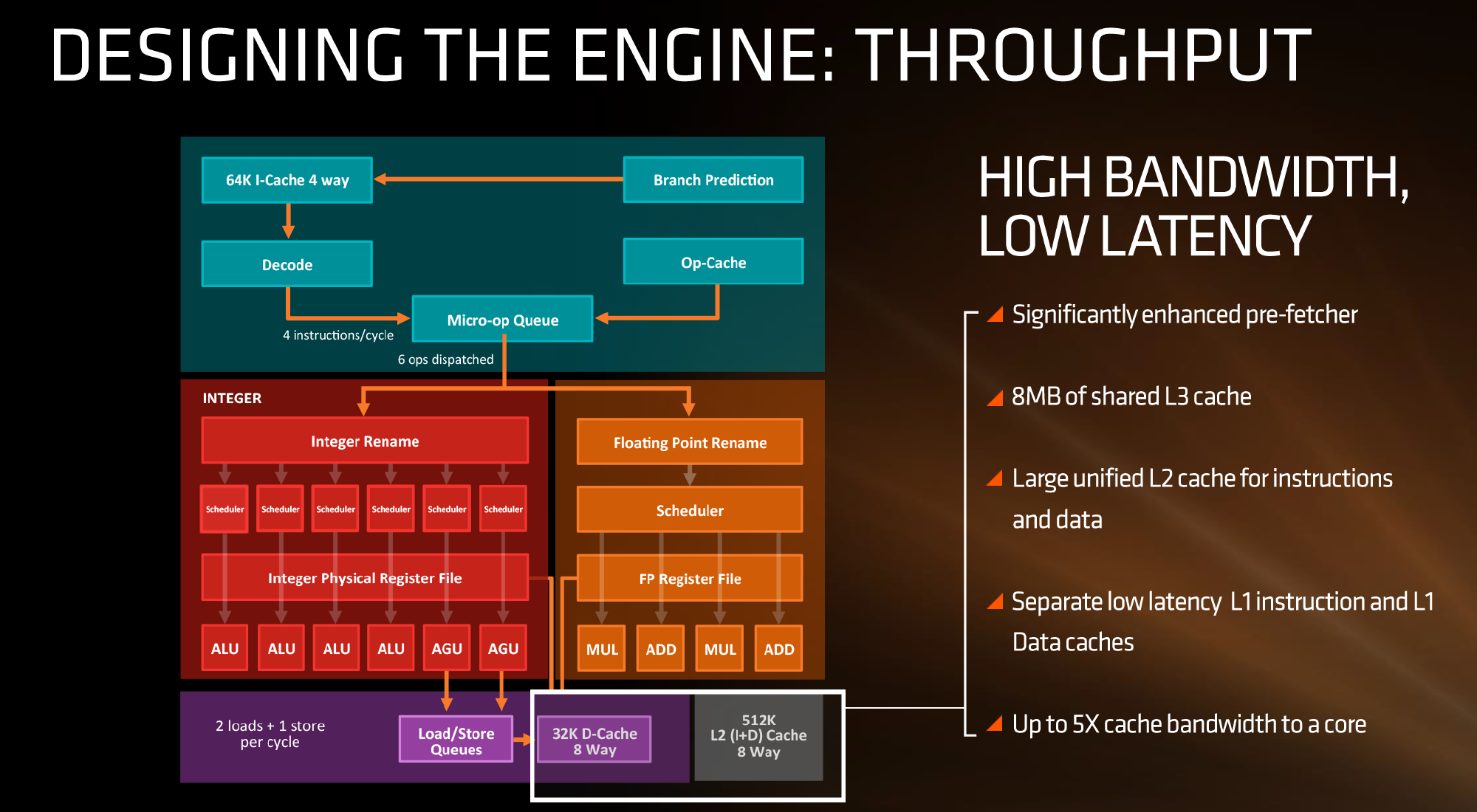
The L2 is a large 512 KB, 8-way cache per core. This is double the size of Intel’s 256 KB 4-way cache in Skylake or 256 KB 8-way cache in Broadwell. Typically doubling the cache size affords a 1.414 (square root of 2) better chance of a cache hit, reducing the need to go further out to find data, but comes at the expense of die area. This will have a big impact on a lot of performance metrics, and AMD is promoting faster cache-to-cache transfers than previous generations. Both the L1 and L2 caches are write-back caches, improving over the L1 write-through cache in Bulldozer.
The L3 cache is an 8MB 16-way cache, although at the time last week it was not specified over how many cores this was. From the data release today, we can confirm rumors that this 8 MB cache is split over a four-core module, affording 2 MB of L3 cache per core or 16 MB of L3 cache for the whole 8-core Zen CPU. These two 8 MB caches are separate, so act as a last-level cache per 4-core module with the appropriate hooks into the other L3 to determine if data is needed. As part of the talk today we also learned that the L3 is a pure victim cache for L1/L2 victims, rather than a cache for prefetch/demand data, which tempers the expectations a little but the large L2 will make up for this. We’ll discuss it as part of today’s announcement.
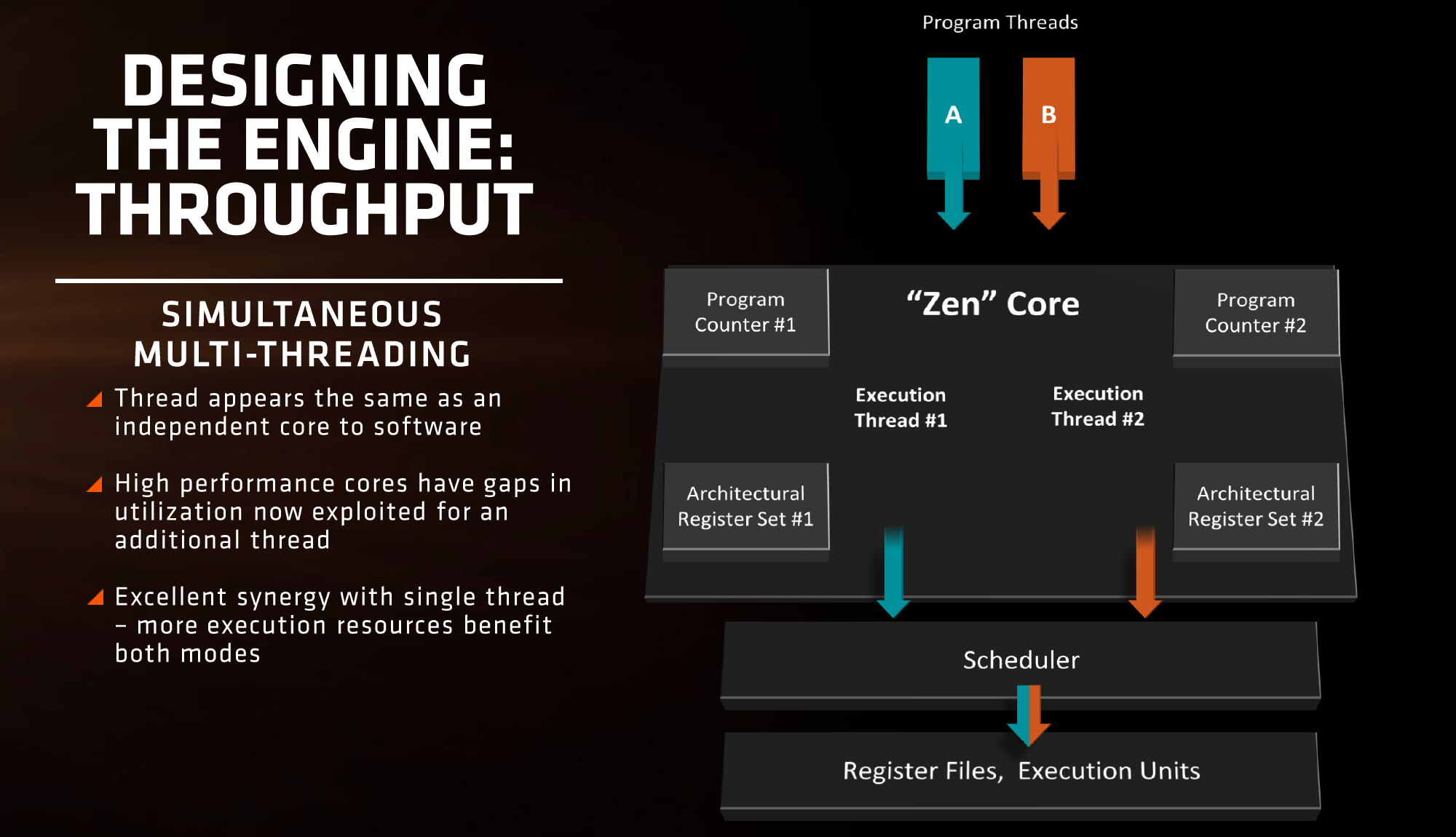
AMD is also playing with SMT, or simultaneous multi-threading. We’ve covered this with Intel extensively, under the heading ‘HyperThreading’. At a high level both these terms are essentially saying the same thing, although their implementations may differ. Adding SMT to a core design has the potential to increase throughput by allowing a second thread (or third, or fourth, or like IBM up to eight) on the same core to have the same access to execution ports, queues and caches. However SMT requires hardware level support – not all structures can be dynamically shared between threads and can either be algorithmically partitioned (prefetch), statically partitioned (micro-op queue) or used in alternate cycles (retire queue).
We also have dual schedulers, one for INT and another for FP, which is different to Intel’s joint scheduler/buffer implementation.








574 Comments
View All Comments
EasyListening - Thursday, March 2, 2017 - link
caqde is correct. There was a point where an Israeli Intel research team went back to the P3 and updated it, focusing on the tightness and speed of the P3 vs the P4 which had become bloated. That was the beginning of what later became the core and i series.lmcd - Thursday, March 2, 2017 - link
Pentium III was the basis for the Core 2 architecture. Pentium IV actually has inspired a lot of things in Sandy Bridge and newer.lmcd - Thursday, March 2, 2017 - link
See: https://en.wikipedia.org/wiki/NetBurst_(microarchi...This is actually a big deal and a huge part of the separation from Sandy Bridge and previous architectures. Obviously the NetBurst version was more complicated, as was everything Intel was doing at the time, but TL;DR P4 has had huge, positive effects on Intel's present product portfolio overall.
rarson - Thursday, March 2, 2017 - link
You're an idiot. They didn't go from successful P-Pro/PII/PIII architecture to Netburst, which was a failure in P4, to Core architecture which was PII-based and wildly successful, and then BACK to Netburst after two successful generations for no reason whatsoever. Sandy Bridge was a refinement of the same Core architecture, same as every other generation.Gondalf - Thursday, March 2, 2017 - link
Ummm the core IPC looks lower than Haswell.....there is work to be done to equal Intel.AMD hides the deficit with an higher clock speed and likely an higer average power consumption.
The_Countess - Thursday, March 2, 2017 - link
power consumption is in fact lower. and they aren't lower then haswell. and skylake is only 7% faster then haswell, so who cares.lmcd - Thursday, March 2, 2017 - link
List power is lower.7% is insignificant?
silverblue - Friday, March 3, 2017 - link
If you go from 57% slower, sure.Cooe - Sunday, February 28, 2021 - link
Uhhh.... Zen's IPC is HIGHER than Haswell in the vast majority of workloads, landing just shy of Broadwell as far as single-thread IPC & just ahead for multi-thread IPC (thanks to AMD's superior SMT implementation).tankNZ - Sunday, March 5, 2017 - link
Hahaha great<img src="http://smsh.me/li3a.png" width="0" height="0">