AMD Ryzen 9 5980HS Cezanne Review: Ryzen 5000 Mobile Tested
by Dr. Ian Cutress on January 26, 2021 9:00 AM EST- Posted in
- CPUs
- AMD
- Vega
- Ryzen
- Zen 3
- Renoir
- Notebook
- Ryzen 9 5980HS
- Ryzen 5000 Mobile
- Cezanne
CPU Tests: Microbenchmarks
Core-to-Core Latency
As the core count of modern CPUs is growing, we are reaching a time when the time to access each core from a different core is no longer a constant. Even before the advent of heterogeneous SoC designs, processors built on large rings or meshes can have different latencies to access the nearest core compared to the furthest core. This rings true especially in multi-socket server environments.
But modern CPUs, even desktop and consumer CPUs, can have variable access latency to get to another core. For example, in the first generation Threadripper CPUs, we had four chips on the package, each with 8 threads, and each with a different core-to-core latency depending on if it was on-die or off-die. This gets more complex with products like Lakefield, which has two different communication buses depending on which core is talking to which.
If you are a regular reader of AnandTech’s CPU reviews, you will recognize our Core-to-Core latency test. It’s a great way to show exactly how groups of cores are laid out on the silicon. This is a custom in-house test built by Andrei, and we know there are competing tests out there, but we feel ours is the most accurate to how quick an access between two cores can happen.
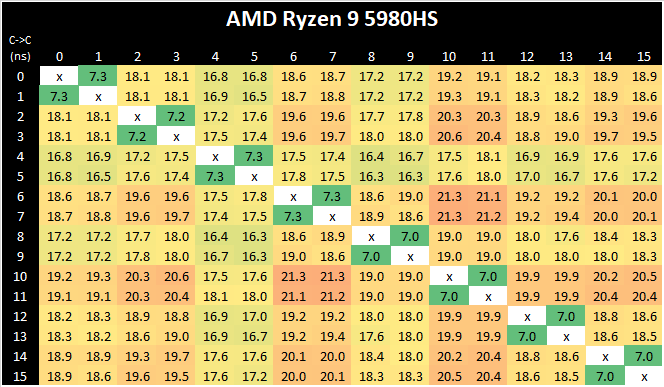
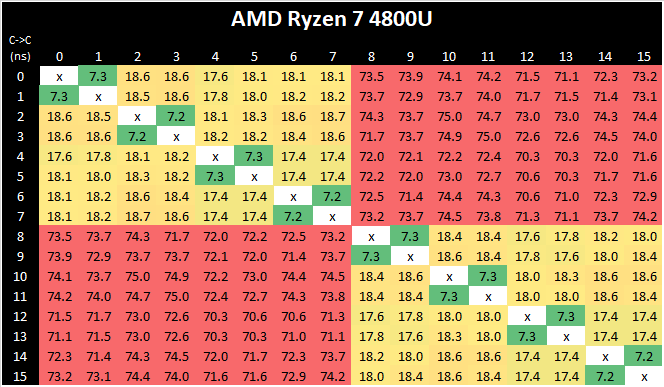
AMD’s move from a dual 4-core CCX design to a single larger 8-core CCX is a key characteristic of the new Zen3 microarchitecture. Beyond aggregating the separate L3’s together for a large single pool in single-threaded scenarios, the new Cezanne-based mobile SoCs also completely do away with core-to-core communications across the SoC’s infinity fabric, as all the cores in the system are simply housed within the one shared L3.
What’s interesting to see here is also that the new monolithic latencies aren’t quite as flat as in the previous design, with core-pair latencies varying from 16.8ns to 21.3ns – probably due to the much larger L3 this generation and more wire latency to cross the CCX, as well as different boost frequencies between the cores. There has been talk as to the exact nature of the L3 slices, whether they are connected in a ring or in an all-to-all scenario. AMD says it is an 'effective' all-to-all, although the exact topology isn't quite. We have some form of mesh with links, beyond a simple ring, but not a complete all-to-all design. This will get more complex should AMD make these designs larger.
Cache-to-DRAM Latency
This is another in-house test built by Andrei, which showcases the access latency at all the points in the cache hierarchy for a single core. We start at 2 KiB, and probe the latency all the way through to 256 MB, which for most CPUs sits inside the DRAM (before you start saying 64-core TR has 256 MB of L3, it’s only 16 MB per core, so at 20 MB you are in DRAM).
Part of this test helps us understand the range of latencies for accessing a given level of cache, but also the transition between the cache levels gives insight into how different parts of the cache microarchitecture work, such as TLBs. As CPU microarchitects look at interesting and novel ways to design caches upon caches inside caches, this basic test proves to be very valuable.
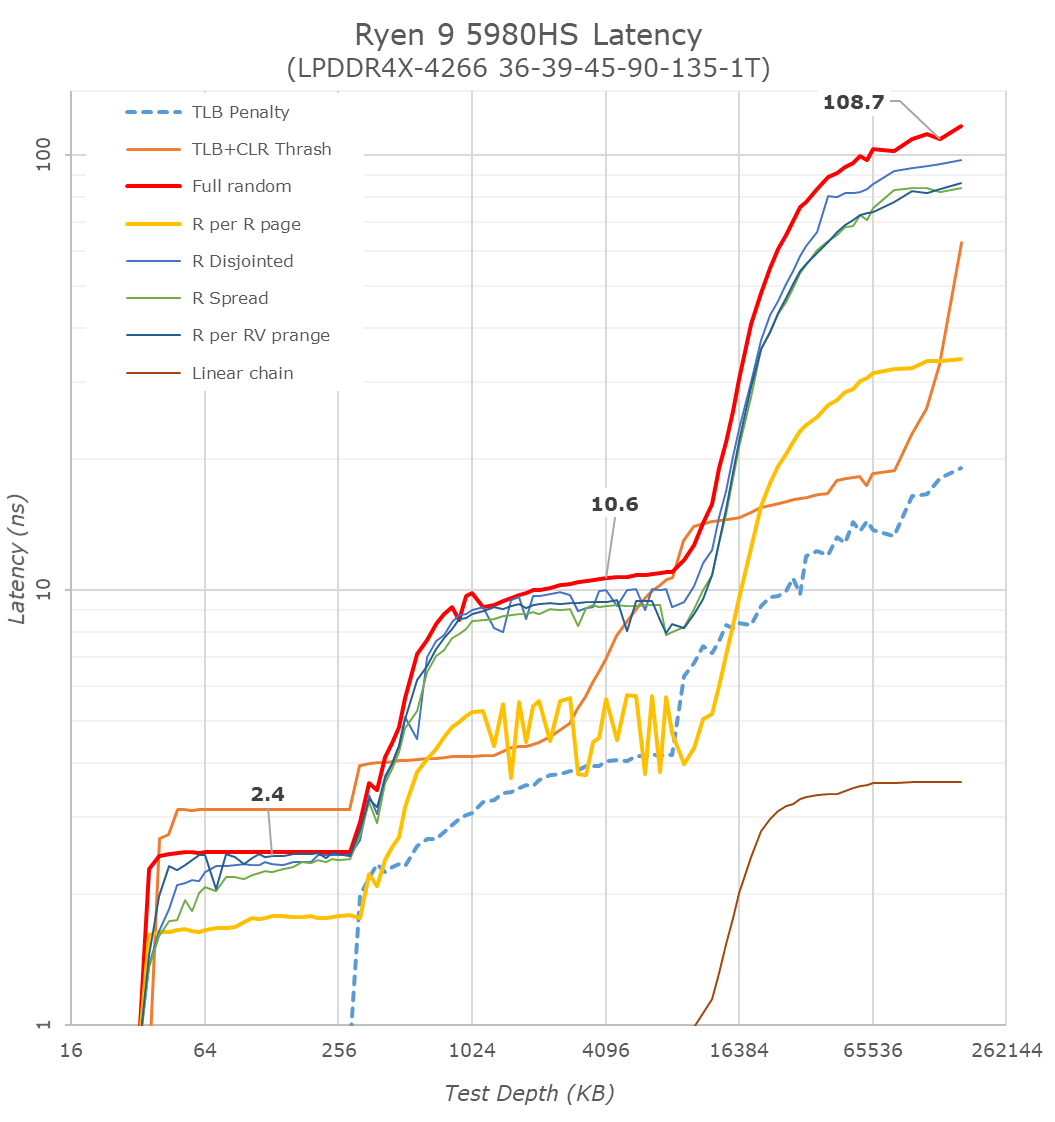
As with the Ryzen 5000 Zen3 desktop parts, we’re seeing extremely large changes in the memory latency behaviour of the new Cezanne chip, with AMD changing almost everything about how the core works in its caches.
At the L1 and L2 regions, AMD has kept the cache sizes the same at respectively 32KB and 512KB, however depending on memory access pattern things are very different for the resulting latencies as the engineers are employing more aggressive adjacent cache line prefetchers as well as employing a brand-new cache line replacement policy.
In the L3 region from 512KB to 16 MB - well, the fact that we’re seeing this cache hierarchy quadrupled from the view of a single core is a major benefit of cache hit rates and will greatly benefit single-threaded performance. The actual latency in terms of clock cycles has gone up given the much larger cache structure, and AMD has also tweaked and changes the dynamic behaviour of the prefetchers in this region.
In the DRAM side of things, the most visible change is again this much more gradual latency curve, also a result of Zen3’s newer cache line replacement policy. All the systems tested here feature LPDDR4X-4266 memory, and although the new Cezanne platform has a slight advantage with the timings, it ends up around 13ns lower latency at the same 128MB test depth point into DRAM, beating the Renoir system and tying with Intel’s Tiger Lake system.
Frequency Ramping
Both AMD and Intel over the past few years have introduced features to their processors that speed up the time from when a CPU moves from idle into a high powered state. The effect of this means that users can get peak performance quicker, but the biggest knock-on effect for this is with battery life in mobile devices, especially if a system can turbo up quick and turbo down quick, ensuring that it stays in the lowest and most efficient power state for as long as possible.
Intel’s technology is called SpeedShift, although SpeedShift was not enabled until Skylake.
One of the issues though with this technology is that sometimes the adjustments in frequency can be so fast, software cannot detect them. If the frequency is changing on the order of microseconds, but your software is only probing frequency in milliseconds (or seconds), then quick changes will be missed. Not only that, as an observer probing the frequency, you could be affecting the actual turbo performance. When the CPU is changing frequency, it essentially has to pause all compute while it aligns the frequency rate of the whole core.
We wrote an extensive review analysis piece on this, called ‘Reaching for Turbo: Aligning Perception with AMD’s Frequency Metrics’, due to an issue where users were not observing the peak turbo speeds for AMD’s processors.
We got around the issue by making the frequency probing the workload causing the turbo. The software is able to detect frequency adjustments on a microsecond scale, so we can see how well a system can get to those boost frequencies. Our Frequency Ramp tool has already been in use in a number of reviews.
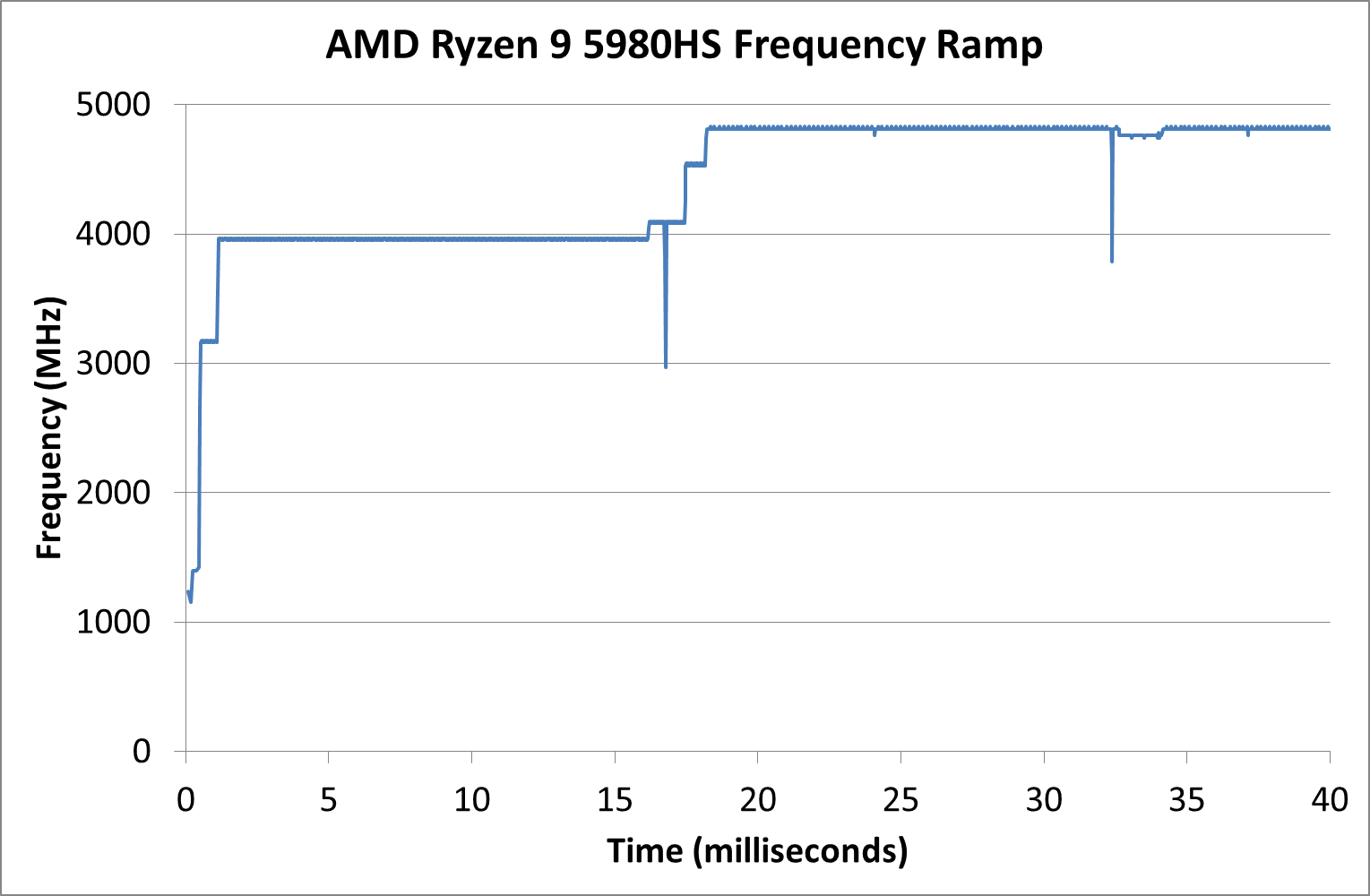
Our frequency ramp showcases that AMD does indeed ramp up from idle to a high speed within 2 milliseconds as per CPPC2. It does take another frame at 60 Hz (16 ms) to go up to the full turbo of the processor mind.








218 Comments
View All Comments
Tomatotech - Thursday, January 28, 2021 - link
Wrong. Check Wikipedia - 2013 MacBook Pros were available from Apple with 1TB SSDs. They’re still good even now as you can replace that 2013 Apple SSD with a modern NVME SSD for a huge speed up.And yes Apple supported the NVMe standard before it was even a standard. It wasn’t finalised by 2013 so these macs need a $10 hardware adaptor in the m.2 bay to physically take the NVMe drive but electronically and on the software level NVME is fully supported.
Kuhar - Thursday, January 28, 2021 - link
Sorry but you are wrong or don`t understand what stock means. On Apple`s own website states clearly that MBP 2013 had STOCK 256 gb SSD with OPTION to upgrade to as high as 1 tb SSD. So maybe your Apple lies again and wiki is ofc correct. On top of that: bragging about 1 tb SSD when in PC world you could get 2 tb SSD in top machines isn`t rellay something to brag about.GreenReaper - Saturday, January 30, 2021 - link
Stock means that they were in stock, available from the manufacturer for order. Which is fair to apply in this case. Most likely they didn't have any SSD in them until they were configured upon sale.What you're thinking of is base. At the same time, it's fair to call out as an unfair comparison, because they are cited as the standard/base configuration of this model, where it wasn't for the MBP
grant3 - Wednesday, January 27, 2021 - link
1. Worrying about what was standard 7 years ago as if it's relevant to what people need today is silly2. TB SSDs were probably about $600-$700 in 2013. If you spent that much to upgrade your MBP, good for you, that doesn't mean it's the best use of funds for everyone.
Makste - Wednesday, January 27, 2021 - link
It is a good review thank you Dr. Ian.My concern is, and has always been the fact that, CPU manufacturers make beefier iGPUs on higher core count CPUs which is not right/fair in my view, because higher core count CPUs and most especially the H series are most of the time bundled with a dGPU, while lower core count CPUs may or may not be bundled with a dGPU. I think lower core count APUs would sell much better if the iGPUs on lower core count CPUs are made beefier because they have enough die space for this, I suppose, in order to satisfy clients who can only afford lower core count CPUs which are not paired with a dGPU. It's a bit of a waste of resources in my view to give 8 vega cores to a ryzen 9 5980HS which is going to be paired with a dgpu and only 6 vega cores to a ryzen 3 5300 whose prospects of being paired with a dGPU are limited.
I don't know what you think about this, but if you agree, then it'd be helpful if you managed to get them to reconsider. Thanks.
Spunjji - Thursday, January 28, 2021 - link
I get your point here, and I agree that it would be a nice thing to have - a 15W 4-core CPU with fully-enabled iGPU would be lovely. Unfortunately it doesn't make much sense from AMD's perspective - they only have one chip design, and they want to get as much money as possible for the fully-enabled ones. It would also add a lot of complexity to their product lineup to have some models that have more CPU cores and fewer GPU CUs, and some that reversed the balance. It's easier for them just to have one line-up that goes from worst to best. :/Makste - Thursday, January 28, 2021 - link
Yes. It could be that, they are sticking with their original plan from the time they decided to introduce iGPUs to X86. But, I don't see why they can't make an overhaul to their offerings now that they are also on top. They could still offer 8 vega dies from the beginning of the series to the top most 8 core cpu offering. And those would be the high end offerings.Then, the other mid and low end variants would be those without the fully enabled vega dies. This way, nothing would be wasted and cezanne would then have a multitude of offerings, I believe people, even at this moment, would like to own a piece of cezanne, be it 3 cores or 5 cores. I think it's the customer to decide what is valuable and what is not valuable. Black and white thinking won't do (that cores will only sell if they are in even numbers). They should simply offer everything they have especially since their design can allow them to do so and more so now that there are supply constraints.
Spunjji - Friday, January 29, 2021 - link
The problem is that it's not just about what the end-user might want. AMD's customers are the OEMs, and the OEMs don't want to build a range of laptops with several dozen CPU options in it, because then they have to keep stock of all of those processors and try to guess the right amount of laptops to build with each different option. It's just not efficient for them. Unfortunately, what you're asking for isn't likely to happen.Makste - Friday, January 29, 2021 - link
Sigh... I realise the cold hard truth now that you've put it more bluntly....An OEM has to fill this gap.
Spunjji - Thursday, January 28, 2021 - link
I might be in the market for a laptop later this year, and it's nice to know that unlike the jump from Zen+ to Zen 2, the newer APUs are better but not *devastatingly so*. I might be able to pick up something using a 4000 series APU on discount and not feel like I'm missing out, but if funds allow I can go for a new device with a 5000 APU and know that I'm getting the absolute best mobile x86 performance per watt/dollar on the market. Either way, it's good to see that the Intel/Nvidia duopoly is finally being broken in a meaningful way.I do have one request - it would be nice to get a separate article with a little more analysis on Tiger Lake in shipping devices vs. the preview device they sent you. Your preview model appears to absolutely annihilate its own very close retail cousin here, and I'd love to see some informed thoughts on how and why that happens. I really don't like the fact that Intel seeded reviewers with something that, in retrospect, appears to significantly over-represent the performance of actually shipping products. It would be good to know whether that's a fluke or something you can replicate consistently - and, if it's the latter, for that to be called out more prominently.
Regardless, thanks for the efforts. It's good to see AMD maintaining good pace. When they get around to slapping RDNA 2 into a future APU, I might finally go ahead and replace my media centre with something that can game!