Khronos Announces OpenCL 3.0: Hitting the Reset Button on Compute Frameworks
by Ryan Smith on April 27, 2020 6:00 AM ESTOver the last 15 years, the evolution of GPU computing – and now more broadly, various forms of highly parallel computing – has taken an interesting tack. While GPUs becoming more widely used as general purpose accelerators was widely predicted and has landed on target in a big way, how we got here has been an interesting path. CPU progression has sputtered, parallel architectures and whole companies have risen and fallen, the world’s most powerful supercomputers now include GPUs as the core of their computational throughput, and no one saw the deep learning revolution coming until it was already upon us.
Standing over this landscape for most of that last decade and a half as been OpenCL, Khronos’s open framework for programming GPUs and other compute accelerators. Originally birthed by Apple and broadly adopted by the industry as a whole, OpenCL was the first (and still most coherent) effort to create a common API for parallel programming. By taking lessons from the early vendor-proprietary efforts and assembling a broader standard that everyone could use, OpenCL has been adopted for everything from embedded processors and DSPs up to GPUs that push half a kilowatt in power consumption.
On the whole, OpenCL has been broadly successful in meeting the framework’s goals for a common (and largely portable) compute programming platform. It’s not just supported on a wide range of hardware, but it’s incredibly relevant even to current events: it’s the accelerator API being used by the Folding@Home project, the world’s most powerful computing cluster, which is being intensively used to research treatment options for the COVID-19 pandemic.

At the same time, however, just as how no one could quite predict the evolution of the parallel computing market, things haven’t always gone quite according to plan for Khronos and the OpenCL working group that spearheads its development. As we’ve touched upon a few times over the past year in various articles, OpenCL is in something of a precarious state on the PC desktop, its original home. Over a decade since its inception, the GPU computing ecosystem is fracturing: NVIDIA’s interest is tempered by the fact that they already have their very successful CUDA API, AMD’s OpenCL drivers are a mess, Apple has deprecated OpenCL and is moving to its own proprietary Metal API. The only vendor who seems to have a real interest in OpenCL at this time is strangely enough Intel. Meanwhile OpenCL was never wildly adopted in mobile devices, despite its patchy use and the fact that these are getting ever more powerful GPUs and other parallel processing blocks.
So today Khronos is doing something for which I’m not sure there’s any parallel for in the computing industry – and certainly, there’s never been anything like it in the GPU computing ecosystem: the framework is taking a large step backwards. Looking to reset the ecosystem, as the group likes to call it, today Khronos is revealing OpenCL 3.0, the latest version of their compute API. Taking some hard earned (and hard learned) lessons to heart, the group is turning back the clock on OpenCL, reverting the core API to a fork of OpenCL 1.2.
As a result, everything developed as part of OpenCL 2.x has now become optional: vendors can (and generally will) continue to support those features, but those features are no longer required for compliance with the core specification. Instead of having to support every OpenCL feature, no matter how useful or useless it might be for a given platform, the future of the API is going to be around vendors choosing which optional features they’d like to support on top of the core, OpenCL 1.2-derrived specification.
Politics & Taking Licks
Overall the OpenCL 3.0 announcement brings a lot to unpack. But perhaps the best place to start is understanding the OpenCL development process, and who OpenCL’s users are. Khronos, as a reminder, is an industry consortium. The organization itself has no real power – it’s just a collection of companies – and because it’s not a platform holder like Microsoft or Apple, the group can’t force technological change on anyone. Instead, the strength of Khronos’s efforts is that it gets broad industry support for its standards, incorporating the experience and concerns of many vendors across the ecosystem.
The challenge in a collaborative approach, however, is that it requires at least a certain degree of harmony and agreement among the companies taking part. If no agreement can be reached on what to do next, then a project cannot move forward. Or if no one is happy with the resulting product, then a product may be skipped entirely. Setting industry standards is ultimately a political matter, even if it’s for a technology standard.
This is, in a way, the problem OpenCL has run into. The most recent version of the specification, OpenCL 2.2, was released back in 2017. Critically, it introduced the OpenCL C++ kernel language, finally bringing support for a more modern, object-oriented language to an API that was originally based on C. Equally critical however, three years later no one has adopted OpenCL 2.2. Not NVIDIA, not AMD, not Intel, and certainly not any embedded device manufacturer.
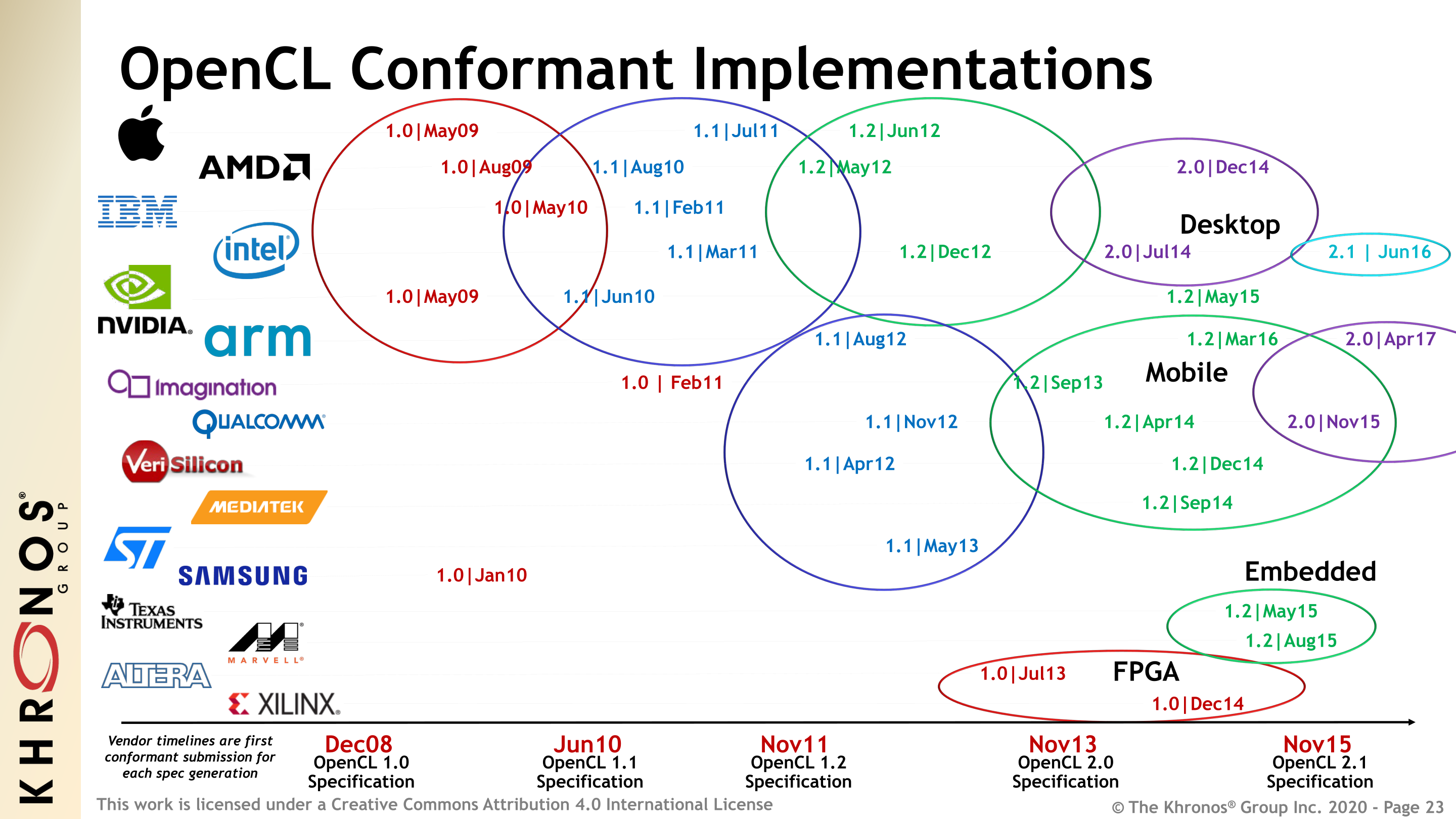
For as important a step forward as OpenCL 2.2 was (and 2.1 before it), the fact of the matter is that no one ended up particularly happy with the state of OpenCL after 1.2 & 2.0. As a result it’s been losing relevance, and is no longer fulfilling the goals of the project. The OpenCL project tried to please everyone with 2.x, and instead it ended up pleasing no one.
OpenCL 3.0: Going Forwards by Going Backwards
So if OpenCL 2.x has largely been ignored, what’s the solution to making OpenCL relevant once again? For Khronos and the OpenCL working group, the answer is to go back to what worked. And what worked best was OpenCL 1.2.

First introduced back in 2011, OpenCL 1.2 was the last of the OpenCL 1.x releases. By modern API standards it’s very barebones: it’s based on pure C and lacking support for things like shared virtual memory or the SPIR-V intermediate representation language. But at the same time, it’s also the last version of the API that doesn’t include a bunch of cruft that someone, somewhere, doesn’t want. It’s a pure, fairly low-level parallel computing API for developers across the spectrum, from embedded devices to the beefiest of GPUs.
Ultimately, what the OpenCL working group has been able to agree on is that OpenCL 1.2 should be the core of a new specification – that anything else released after it, no matter how useful in some cases, isn’t useful enough that it should be required in all implementations. And so for OpenCL 3.0 this is exactly what’s happening. The newest version of OpenCL is inheriting 1.2 and making it the new core specification, while all other features beyond that are being moved out of the core specification and being made optional.
It’s this reset that Khronos and the working group is intending to give OpenCL a new path forward. Despite turning back the clock by almost nine years, OpenCL is nowhere close to being done evolving. But its previous rigid, monolithic nature also kept it from evolving, because there was only one path forward. If a vendor was happy with OpenCL 1.2 but wanted a couple of extra 2.1 features, for example, then to be compliant with the specification they’d need to implement the entire 2.1 core specification; OpenCL 1.x/2.x had no mechanism for partial compliance. It was all or nothing, and a number of vendors chose “nothing.”
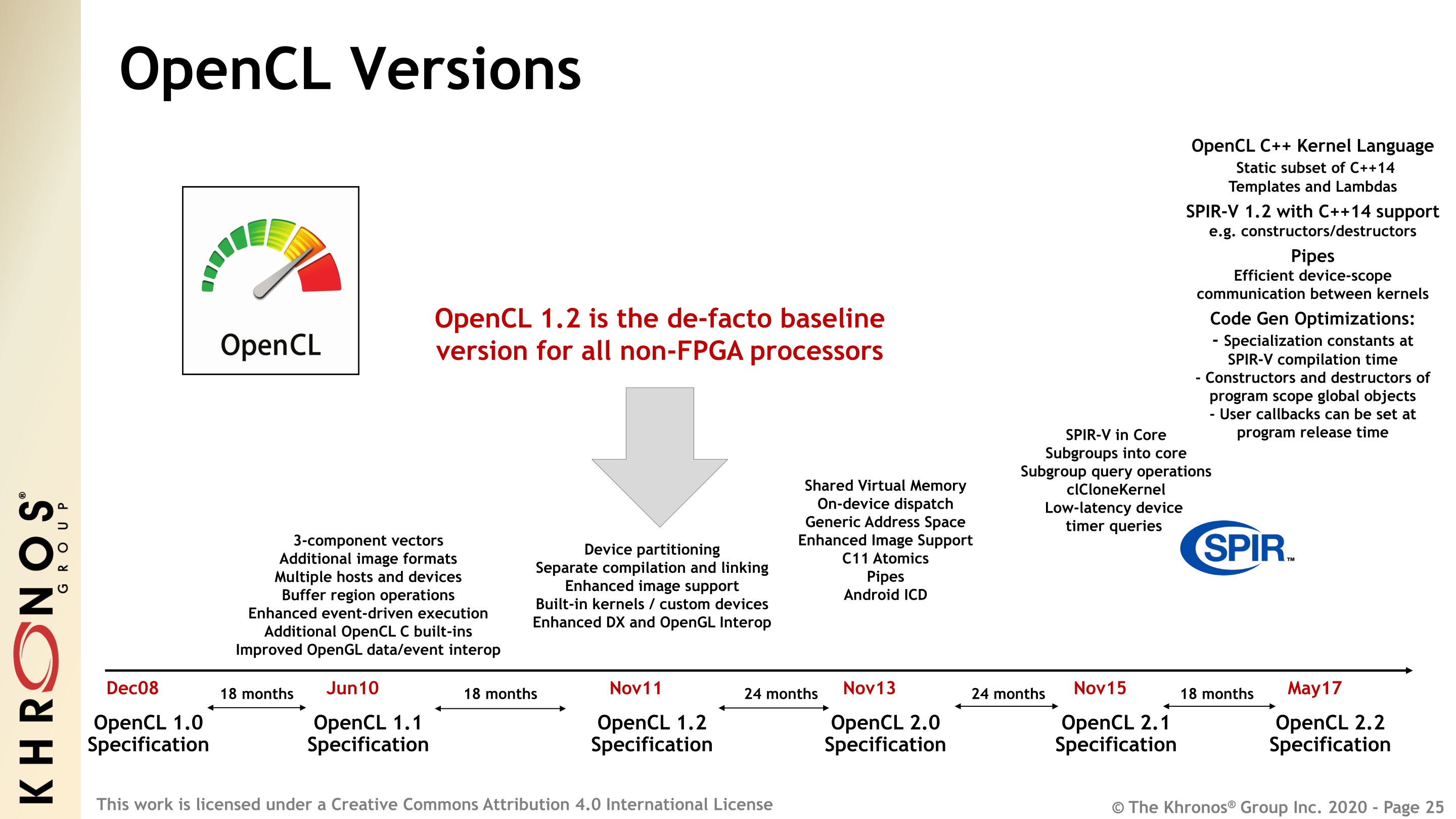
OpenCL 3.0, by contrast, is specifically structured in a way to let vendors use the parts they need, and only those parts. As previously mentioned, the actual core of the specification is essentially OpenCL 1.2, with the addition feature query support, as well as some “minor entry points for improved app portability.” Layered on top of that, in turn, is everything else: all of OpenCL 2.x’s features, as well as OpenCL 3.0’s new features. All of these additional features are optional, allowing platform vendors to pick and choose what additional features they’d like to support, if any at all.
For example, an embedded vendor may stick very close to what was OpenCL 1.2, and then adopt a couple of features like asynchronous DMA extensions and shared virtual memory. Meanwhile a large, green discrete GPU developer may adopt most of OpenCL 2.x, but exclude support for that shared virtual memory, which isn’t very useful for a discrete accelerator. And then a third vendor in the middle might want to adopt on device dispatch, but not SPIR-V. Ultimately OpenCL 3.0 gives platform vendors the ability to select those features they need, in essence tailoring OpenCL to their specific desires.
This, as it turns out, is very similar to how Khronos has tackled Vulkan, which has been far more successful in recent years. Giving vendors some flexibility in what their API implements has allowed Vulkan to be stretched from mobile devices to the desktop, so there is some very clear, real-world evidence that this structure can work. And it’s this kind of success that the OpenCL working group would like to see as well.
Ultimately, as Khronos sees it, OpenCL’s struggles over the last half-decade or so have come from trying to make it everything for everyone while at the same time keeping its monolithic nature. What the embedded guys need is different from the CPU/APU guys, and what those guys need is different still from the dGPU guys – and we still haven’t gotten to things like FPGAs and more esoteric uses of OpenCL. So in order to secure its own future, OpenCL needs to move away from being a monolithic design, and instead being adaptable to the wide range of devices and markets the framework is designed to serve.
Walking the Path Forward
Diving just a bit deeper, let’s take a quick look at what OpenCL 3.0 means for developers, platform vendors, and users as far as software development and compatibility are concerned.

Despite the significant change in development philosophy, OpenCL 3.0 is designed to be as backwards-compatible as is reasonable. For developers and users, because the core specification is based on OpenCL 1.2, 1.2 applications will run unchanged on any OpenCL 3.0 device. Meanwhile for OpenCL 2.x applications, those applications will also run unchanged on OpenCL 3.0 devices as well so long as those devices support whatever 2.x features were being used. Which, to be sure, doesn’t mean you’re going to be running an OpenCL 2.1 application on an embedded system any time soon; but on PCs and other systems where OpenCL 2.1 applications already run, they aren’t expected to stop running under OpenCL 3.0.
The reason for that distinction again comes to down to the optional inclusion of features. Platform vendors developing an OpenCL 3.0 runtime don’t need to support 2.x features, but they also don’t need to drop them; they can (continue to) support optional features as they see fit. In fact, the new specification requires relatively little of platform holders as far as core compliance is concerned. OpenCL 1.2 and 2.x drivers do need some changes to meet 3.x compliance, but this is mainly around supporting OpenCL’s new feature queries. So vendors will be able to release 3.0 drivers in short order.
Going forward then, the focus is going to be on application developers making proper use of feature queries. Because OpenCL 2.x features are optional, all applications using 2.x/3.0 optional features are strongly encouraged to use feature queries to first make sure the necessary features are available; at a minimum an application can then fail gracefully, rather than a harder failure from invoking a feature that doesn’t exist. So while OpenCL 2.x software will continue to work as-is, developers are being encouraged to update their applications to run feature queries.

Now with all of that said, it should be noted that since a bunch of previously required OpenCL 2.x features have been made optional, this does mean that platform vendors are allowed to drop them if they wish. Talking to Khronos, it doesn’t sound like this is going to happen – at least, not with the PC hardware vendors – but it’s an option none the less, and one that they acknowledge. Where it’s more likely to be seen (if anywhere) would be the embedded space and such, where vendors were already dragging their heels on features like SPIR-V.
Finally, while the real-world impact of this will be nil, it’s also worth noting that because OpenCL 2.2 was never adopted, the OpenCL 3.0 standard does technically leave something behind. OpenCL C++, which was introduced in 2.2, has not been included in the OpenCL 3.0 specification, even as an optional feature. Instead, the OpenCL working group is discarding it entirely.
Replacing OpenCL C++ is the C++ for OpenCL project, which, despite the naming similarities, is a separate project entirely. The differences are fairly small from a programming perspective, but essentially C++ for OpenCL is being built with a layered approach. In this case, using Clang/LLVM to compile the code down to SPIR-V, which then can be run on the lower-levels of the OpenCL execution stack like other code. And of course, Khronos’s SYCL remains as well to provide single-source C++ programming for parallel compute. SYCL, it should be noted, is based on top of OpenCL 1.2, so it makes this transition rather unfazed.
What’s New in OpenCL 3.0: Asynchronous DMA Extensions & SPIR-V 1.3
Besides the major reversion to the core specification, OpenCL does also include some new, optional features for platform vendors and developers to dig their teeth into. Chief among these are Asynchronous DMA extensions, which will end up being a particularly tasty carrot for platform vendors whom have been sticking with OpenCL 1.2 so far.

Intended to expose direct memory access operations in OpenCL for devices that have DMA hardware, Asynchronous DMA is exactly what the name says on the tin: support for executing DMA transfers asynchronously. This allows DMA transactions to be run concurrently with compute kernels, as opposed to synchronous operations which generally can only be executed between other compute kernel operations. This includes being able to run multiple DMA operations concurrent to each other as well.
This feature is particularly notable for enabling 2D and 3D memory transfers – that is, complex memory structures that are more advanced than simple 1D (linear) memory structures. As you might expect, this is intended to be useful for images and similar data, which are inherently 2D/3D structures to begin with.
Meanwhile, OpenCL 3.0 also introduces SPIR-V 1.3 support to OpenCL. This again is an optional feature for platform holders, and brings OpenCL slightly more up to date in its SPIR-V support, with mainline SPIR-V now at version 1.5. Truth be told, I’m not sure how relevant the option of 1.3 support is going to be at the moment, however because it’s part of the Vulkan 1.1 specification – and indeed a lot of the advances in it over 1.2 are focused on graphics – it’s going to play a bigger role going forward in reinforcing interoperability between Vulkan and OpenCL.
What’s Next for OpenCL?
Finally, as part of OpenCL’s major overhaul for 3.0, Khronos and the OpenCL working group is also laying out their plans for the future development of OpenCL. By clearing the board and moving so many features to optional, it gives the working group new freedom to add to OpenCL as the user base sees fit. And, following their new philosophy, in a more piecemeal way.
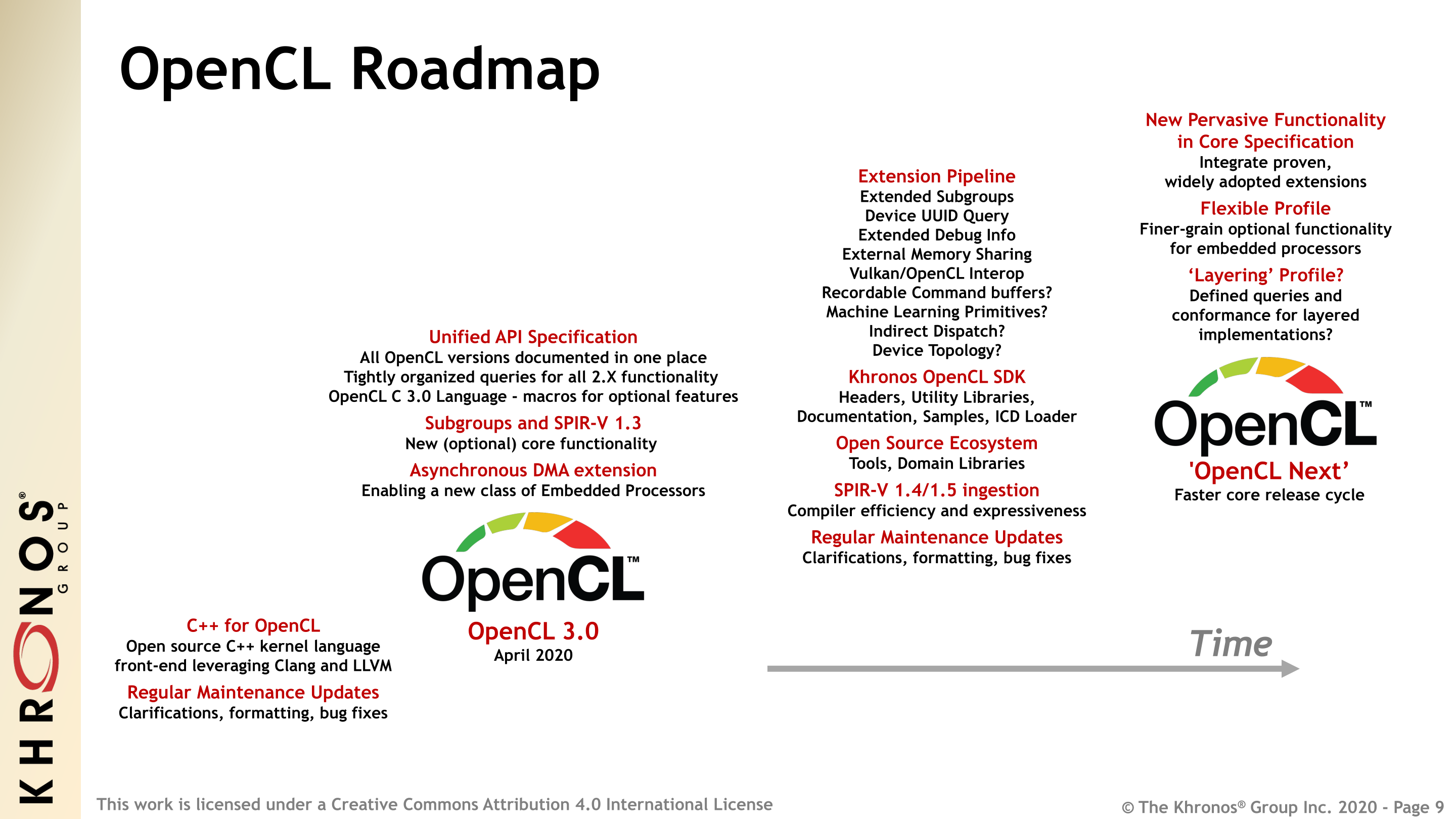
A big part, as always, will be the continued evolution of the OpenCL core specification. While 3.0 winds things back, the plan isn’t to maintain the 1.2-eque core specification forever. Rather, like other Khronos projects, the goal of the working group is still to move widely adopted and well-tested extensions into the core. To once again add additional layers to the onion, as it were, but in a much smarter and measured fashion than was OpenCL 2.x development.
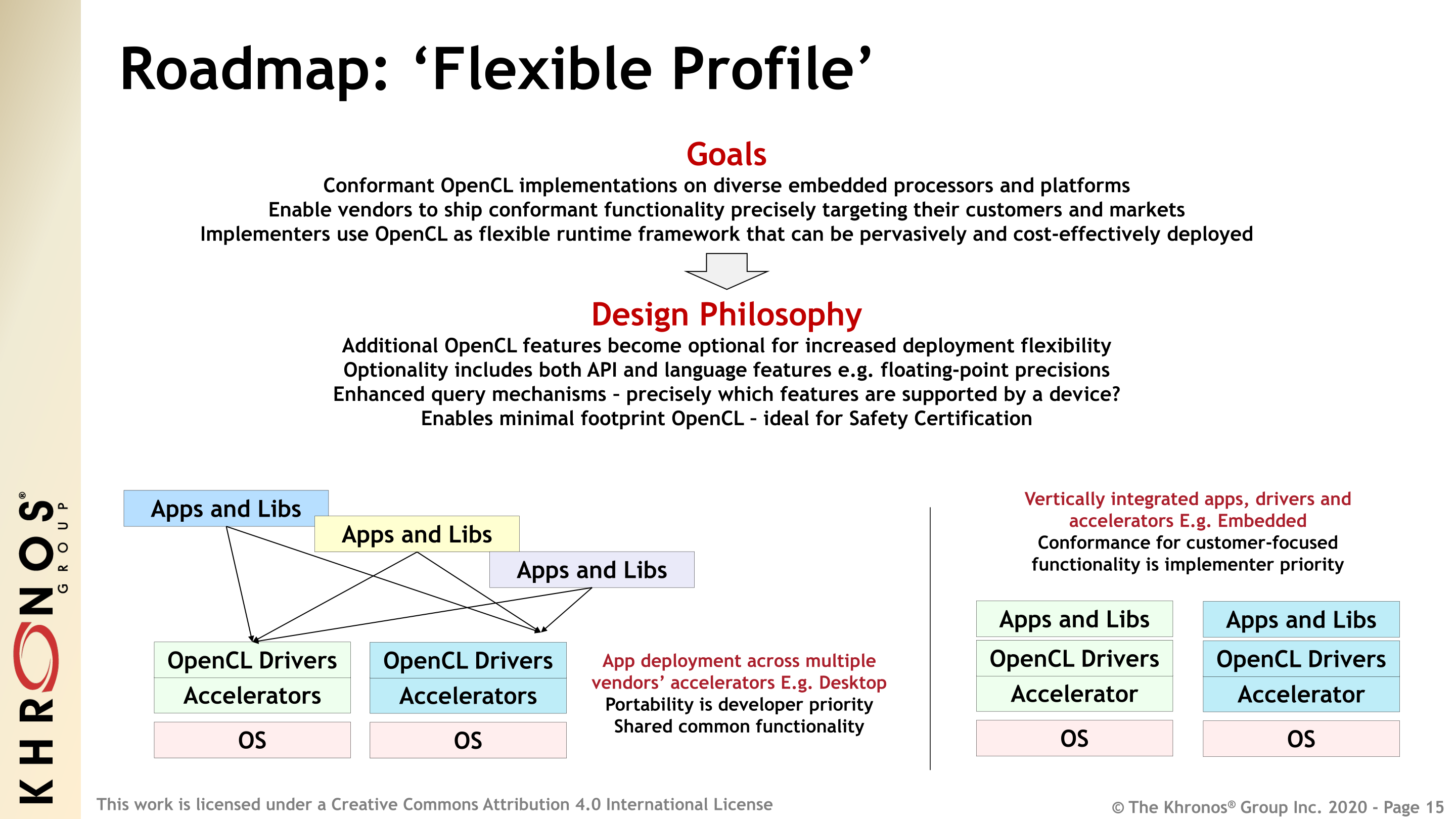
In the meantime, one of the high priority features for future versions will be what the group is calling Flexible Profile, which is another embedded-focused feature. Interestingly, in some respects this is an even more stripped down version of OpenCL, allowing vendors to excise even more features to specifically match what their hardware can do. For example, floating-point precision modes like IEEE single precision, which are normally required in OpenCL 1.2/3.0 could be removed, as well as some API calls. Besides further simplifying things for some developers, it would make OpenCL a better fit for environments with rigorous safety certification requirements (think automotive), as a smaller OpenCL feature set would be much easier to validate and get certified.
Meanwhile at the other end of the spectrum, Khronos is once again looking at the idea of feature sets for OpenCL, to help software developers better navigate the differences between major platforms. While the option-heavy nature of OpenCL 3.0 makes it relatively fine-grained, it also hurts portability to a degree – a developer can’t count on another OpenCL 3.0 implementation to necessary have anything more than what the 1.2-eqsue core specification calls for. So not unlike graphics feature sets for GPUs, OpenCL feature sets would allow the industry to engage in some standardization – say a PC profile with numerous modern features, and then a machine learning profile with support for a smaller number of features more relevant to just deep learning operations.
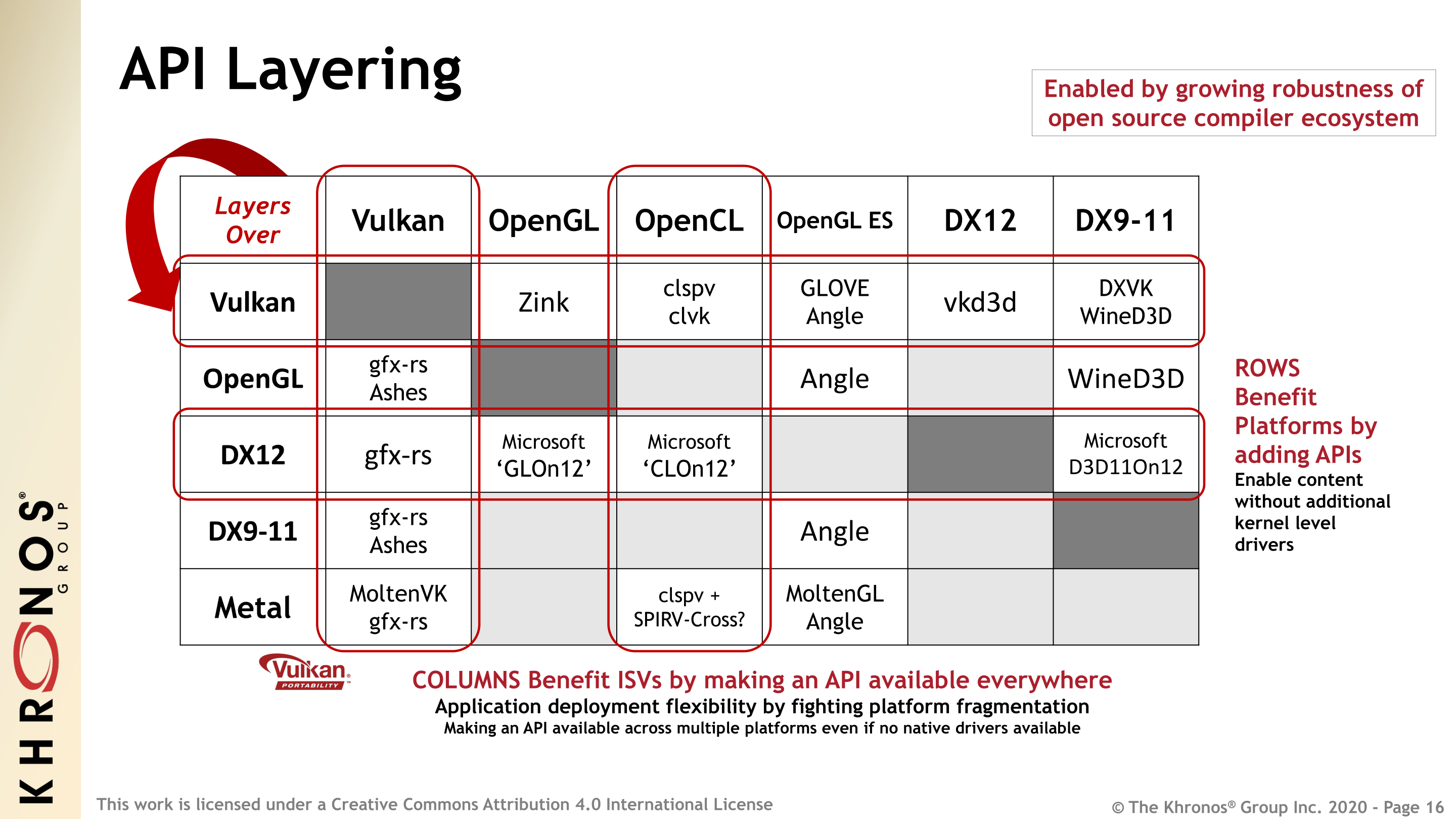
The group is also looking at continued opportunities for layered approaches, where OpenCL support isn’t (and likely never will be) a native part of the platform. This is another concept taken from the Vulkan playbook, where there are layers available to run Vulkan on platforms like Apple’s Metal. OpenCL already has an active project to run on top of Vulkan – clspv and clvk – which has been used in mobile to help Adobe port and reuse its OpenCL code from deskto0p Premiere over to Premiere Rush without requiring an extensive rewrite. Meanwhile Microsoft has been backing an OpenCL project as well, (Open)CLOn12, which will implement OpenCL 1.2 support on top of DirectX 12.
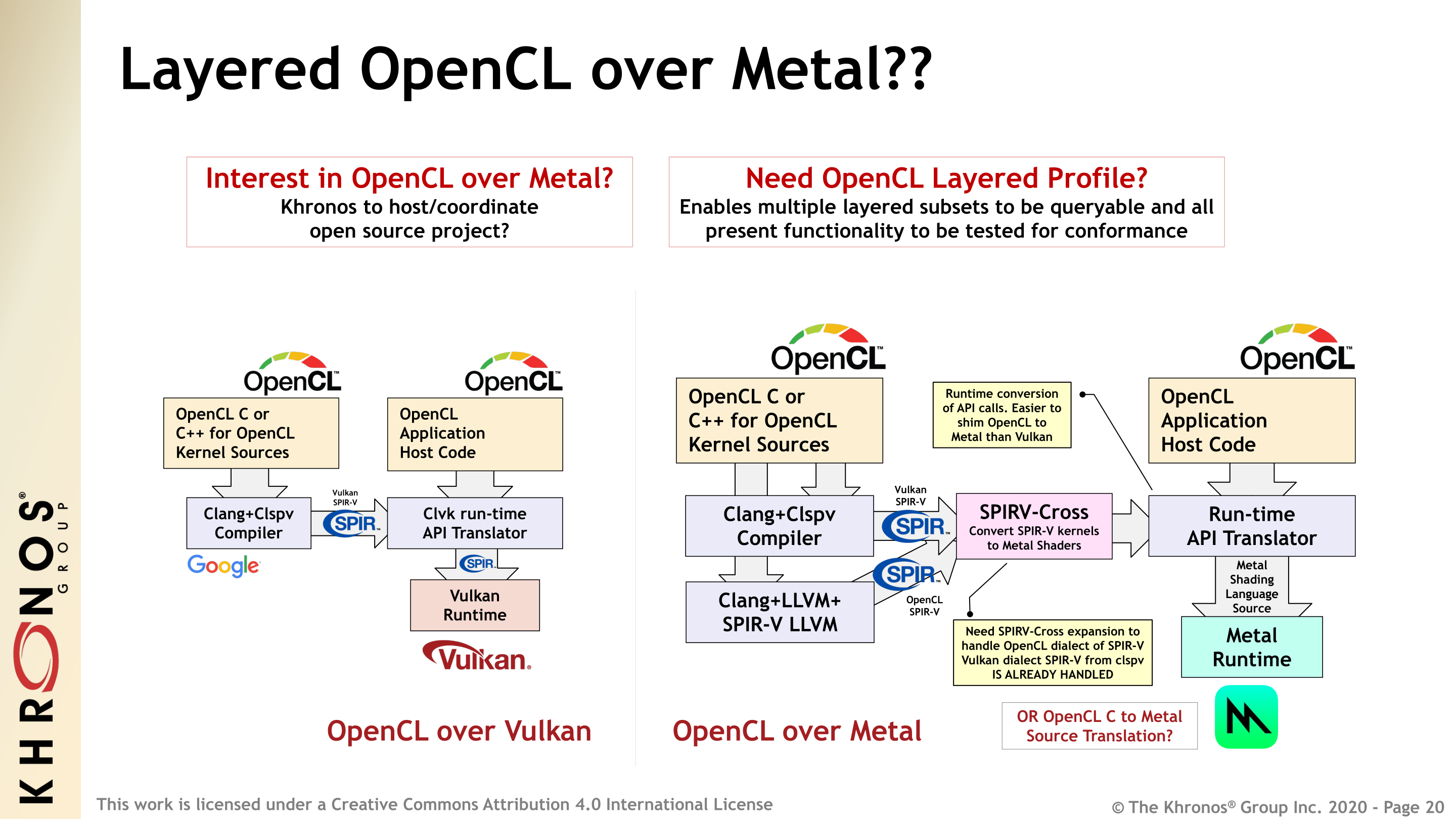
But the big layering question that Khronos is posing right now revolves around OpenCL for Apple’s platforms. The original author of OpenCL hasn’t made it any farther than supporting OpenCL 1.2, and they’ve marked the feature for deprecation. So if OpenCL is going to stay working on Apple platforms – never mind supporting new 2.x and 3.x features – then new support would need to be added as a higher level layer. So while there isn’t currently a OpenCL over Metal project, it seems like it’s only a matter of time until one is started, if of course Khronos can find enough interested parties for the project. The group has seen a lot of success with MoltenVK, their Vulkan-over-Metal layer, so an OpenCL project would fit in well with that.

Finally, even Vulkan itself is a potential project of sorts for the OpenCL working group. The reversions to the core specification mean that Vulkan/OpenCL interoperability have taken a step back, and the working group would like to push that forward. Ideally, OpenCL should be able to work within the same memory set as Vulkan, as well as import and export semaphores, all in an explicit fashion.
OpenCL 3.0: Provisional Today, Formalization In A Few Months?
But before any of this can formally happen, Khronos and the OpenCL working group will have their work cut out for them getting OpenCL 3.0 out the door. While the group is introducing OpenCL 3.0 today, the standard is still provisional – it’s being revealed to developers and the wider public to get feedback ahead of full formalization. And given the currently sputtering state of OpenCL 2.x, the group is eager to get OpenCL 3.0 finalized sooner than later.

All told, Khronos hopes that they’ll be able to get ratification for the standard in a few months. Along with getting member and developer buy-in, finalization will also require that the OpenCL 3.0 conformance tests (which are also already in development) are completed, so that the group can formally approve OpenCL 3.0 implementations. Being the technical part, this may end up being the easier task; with the OpenCL 3.0 core specification unwinding so many features and adding so little in return, vendors who already have solid OpenCL implementations shouldn’t have too much trouble getting their OpenCL 3.0 drivers ready.














69 Comments
View All Comments
sharathc - Monday, April 27, 2020 - link
Rest in Peace OpenCLmode_13h - Wednesday, April 29, 2020 - link
That would've made more sense, *before* this move.I still think one of the best things for OpenCL would be Raspberry Pi supporting it.
NikosD - Friday, May 1, 2020 - link
The President of Khronos Group is the Vice President of nVidia.Or you could say that the Vice President of nVidia is the President of Khronos Group.
Or you could say RIP OpenCL but long live CUDA
You got the meaning...
mode_13h - Tuesday, May 5, 2020 - link
That's nothing new. Consider that Nvidia didn't appoint themselves to those positions. If the majority of Khronos members felt that Nvidia was derailing the body's activities, you'd think they'd get voted out, right?ProDigit - Monday, April 27, 2020 - link
Shout out to all those who finished reading the entire article!Valantar - Tuesday, April 28, 2020 - link
I made it! Barely.Spunjji - Tuesday, April 28, 2020 - link
Woo! The nerdliest of nerds!wr3zzz - Monday, April 27, 2020 - link
I don't know when it became a trend that a "standard" has features that are optional. It's not a standard if something that says it is but isn't. USB-C compatibility is already a mess and HDMI 2.1 might be next. Are engineering schools nowadays taught by politicians?drexnx - Monday, April 27, 2020 - link
my thoughts exactly, Khronos saw the "success" of the USB-IF group and what an absolute mess 3.0 3.1 gen 1, 3.2 gen 1x1 all being the same port is and figured, hey, let's do that!Deicidium369 - Tuesday, April 28, 2020 - link
No they saw the market closing ranks, and are trying to get a foot in the door before it's completely closed off bu CUDA and One API... nothing like the fiasco of the USB geniuses.